课程链接:https://learn.deeplearning.ai/courses/chatgpt-building-system/lesson/1/introduction
github: https://github.com/MSzgy/Building-Systems-with-the-ChatGPT-API
Introduction
在本课程中介绍了LLM的基本原理,LLM的使用场景,LLM对输入的安全检测。同时,也介绍了两种LLM prompt的两种方式,”Chain of Thought Reasoing“ 与 ”Chaining Prompts“。最后介绍了如何评估模型的输出结果质量。
Language Models, the Chat Format and Tokens
这里简单回顾下LLM是怎样训练的,不断根据前面的词去预测下一个词。
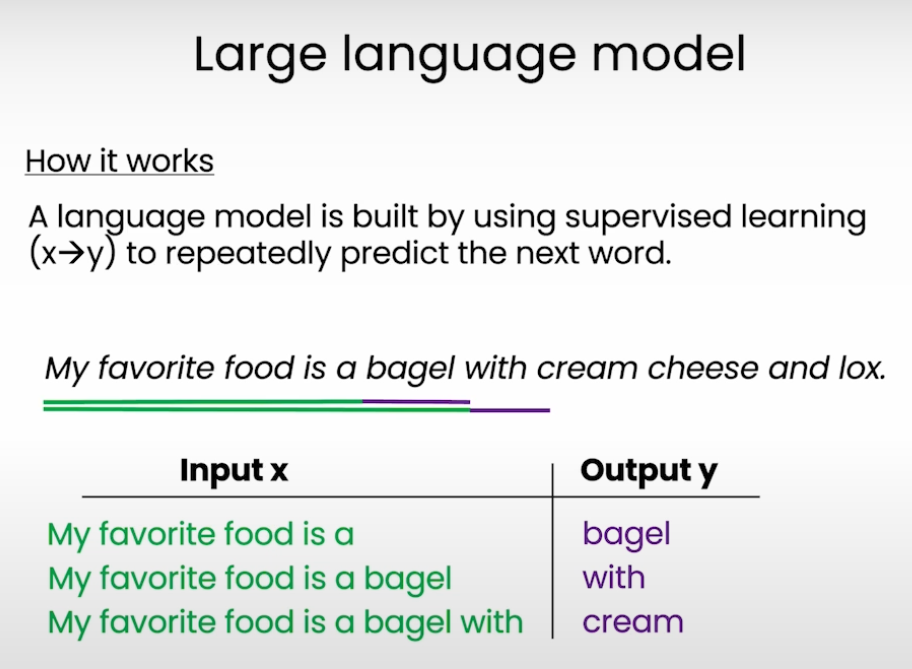
在训练LLM时,有两个模型需要训练,首先是基础模型可以进行文本补全,然后是Instruction model,会给出相关question和answer作为一个训练对进行训练。

下面介绍了如何从base model到instruction tuned model的方法
1 首先要准备instruction的数据集
2 对与LLM的输出进行打分,选取有用的高质量的回答。

LLM在处理句子时是按照token划分的

Classification
在这节举了一个例子,根据客户的sentence进行问题分类:
delimiter = "####"
system_message = f"""
You will be provided with customer service queries. \
The customer service query will be delimited with \
{delimiter} characters.
Classify each query into a primary category \
and a secondary category.
Provide your output in json format with the \
keys: primary and secondary.
Primary categories: Billing, Technical Support, \
Account Management, or General Inquiry.
Billing secondary categories:
Unsubscribe or upgrade
Add a payment method
Explanation for charge
Dispute a charge
Technical Support secondary categories:
General troubleshooting
Device compatibility
Software updates
Account Management secondary categories:
Password reset
Update personal information
Close account
Account security
General Inquiry secondary categories:
Product information
Pricing
Feedback
Speak to a human
"""
user_message = f"""\
I want you to delete my profile and all of my user data"""
messages = [
{'role':'system',
'content': system_message},
{'role':'user',
'content': f"{delimiter}{user_message}{delimiter}"},
]
response = get_completion_from_messages(messages)
print(response)Moderation
来自用户的prompt有可能会包含一些色情,暴力信息,对于这一类的问题,不应该被回到。ChatGPT也提供了相应的接口去检测这些不合适的问题。
在处理时,应该对于用户的问题做隔离处理,比如利用 ### 去特意指明用户的问题,与预置的prompt区分开来。
Chain of Thought Reasoning
有时在向LLM询问问题时,如果仅是直接询问,则会输出错误的答案,因此我们需要将复杂的问题给分解开,在prompt中按步骤说明,让LLM一步步给出答案,回答准确率则会大大提高。
Follow these steps to answer the customer queries.
The customer query will be delimited with four hashtags,\
i.e. {delimiter}.
Step 1:{delimiter} First decide whether the user is \
asking a question about a specific product or products. \
Product cateogry doesn't count.
Step 2:{delimiter} If the user is asking about \
specific products, identify whether \
the products are in the following list.
All available products:
1. Product: TechPro Ultrabook
Category: Computers and Laptops
Brand: TechPro
Model Number: TP-UB100
Warranty: 1 year
Rating: 4.5
Features: 13.3-inch display, 8GB RAM, 256GB SSD, Intel Core i5 processor
Description: A sleek and lightweight ultrabook for everyday use.
Price: $799.99
2. Product: BlueWave Gaming Laptop
Category: Computers and Laptops
Brand: BlueWave
Model Number: BW-GL200
Warranty: 2 years
Rating: 4.7
Features: 15.6-inch display, 16GB RAM, 512GB SSD, NVIDIA GeForce RTX 3060
Description: A high-performance gaming laptop for an immersive experience.
Price: $1199.99
3. Product: PowerLite Convertible
Category: Computers and Laptops
Brand: PowerLite
Model Number: PL-CV300
Warranty: 1 year
Rating: 4.3
Features: 14-inch touchscreen, 8GB RAM, 256GB SSD, 360-degree hinge
Description: A versatile convertible laptop with a responsive touchscreen.
Price: $699.99
4. Product: TechPro Desktop
Category: Computers and Laptops
Brand: TechPro
Model Number: TP-DT500
Warranty: 1 year
Rating: 4.4
Features: Intel Core i7 processor, 16GB RAM, 1TB HDD, NVIDIA GeForce GTX 1660
Description: A powerful desktop computer for work and play.
Price: $999.99
5. Product: BlueWave Chromebook
Category: Computers and Laptops
Brand: BlueWave
Model Number: BW-CB100
Warranty: 1 year
Rating: 4.1
Features: 11.6-inch display, 4GB RAM, 32GB eMMC, Chrome OS
Description: A compact and affordable Chromebook for everyday tasks.
Price: $249.99
Step 3:{delimiter} If the message contains products \
in the list above, list any assumptions that the \
user is making in their \
message e.g. that Laptop X is bigger than \
Laptop Y, or that Laptop Z has a 2 year warranty.
Step 4:{delimiter}: If the user made any assumptions, \
figure out whether the assumption is true based on your \
product information.
Step 5:{delimiter}: First, politely correct the \
customer's incorrect assumptions if applicable. \
Only mention or reference products in the list of \
5 available products, as these are the only 5 \
products that the store sells. \
Answer the customer in a friendly tone.
Use the following format:
Step 1:{delimiter} <step 1 reasoning>
Step 2:{delimiter} <step 2 reasoning>
Step 3:{delimiter} <step 3 reasoning>
Step 4:{delimiter} <step 4 reasoning>
Response to user:{delimiter} <response to customer>
Make sure to include {delimiter} to separate every step.Chaining Prompts
好处:



与上节Chain of Thought Reasoning异同点
Chaining Prompts 和 Chain of Thought Reasoning 是两个在大语言模型(LLM)中常用的方法,分别用来处理复杂任务或提高模型的推理能力。虽然名称相似,它们的核心思想和应用场景有所不同。
1. Chaining Prompts
Chaining Prompts 是指将多个任务或问题拆分成更小的步骤,用多个提示(prompts)串联起来,每个提示的输出会作为下一个提示的输入。这种方法特别适用于复杂任务的分解和逐步处理。
• 核心理念: 分解任务,将一个大问题拆成多个小问题,逐步解决。
• 典型场景:
1. 数据处理: 清洗数据 -> 结构化数据 -> 提取关键信息。
2. 内容生成: 先生成大纲 -> 生成每一部分的内容 -> 合并。
3. 多步骤逻辑: 分步求解复杂逻辑问题。
实现方式:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
# Step 1: Define prompts
prompt1 = PromptTemplate(input_variables=["topic"], template="Write an outline about {topic}.")
prompt2 = PromptTemplate(input_variables=["outline"], template="Expand on this outline: {outline}.")
# Step 2: Create chains
chain1 = LLMChain(prompt=prompt1, llm=llm)
chain2 = LLMChain(prompt=prompt2, llm=llm)
# Step 3: Chain them sequentially
overall_chain = SequentialChain(chains=[chain1, chain2])• 优点:
• 更易于控制模型行为。
• 每一步输出更透明,可以手动检查和调整。
• 缺点:
• 效率低,需要多次调用模型。
• 每一步的错误可能会积累。
2. Chain of Thought Reasoning
Chain of Thought Reasoning (CoT) 是一种推理方法,旨在通过显式的推理链条帮助模型得出最终结论。这种方法主要用于解决需要多步推理或复杂逻辑的问题,比如数学题、常识推理题。
• 核心理念: 显示推理过程,让模型“想出来”答案,而不是直接给出答案。
• 典型场景:
1. 数学推理: 分步计算复杂数学问题。
2. 逻辑推理: 逐步分析问题的原因和结果。
3. 问答: 综合多条信息逐步得出结论。
提示示例:
Q: A train leaves the station at 2 PM and travels at a speed of 60 miles per hour. Another train leaves the same station at 3 PM and travels at a speed of 80 miles per hour. At what time will the second train catch up to the first train?
A: Let's think step by step.
- The first train has a head start of 1 hour at 60 miles per hour, so it is 60 miles ahead.
- The relative speed of the second train compared to the first train is 80 - 60 = 20 miles per hour.
- Time taken to close the gap is 60 miles / 20 miles per hour = 3 hours.
- The second train will catch up at 3 PM + 3 hours = 6 PM.
Answer: 6 PM.
• 优点:
• 提高复杂推理的准确性。
• 模型输出的推理过程可解释性更强。
• 缺点:
• 有时会生成冗长且不必要的推理。
• 对 prompt 工程要求高。
实现方式:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Define a CoT prompt
prompt = PromptTemplate(
input_variables=["question"],
template="You are a helpful assistant. Solve this problem step by step:\nQuestion: {question}\nAnswer:"
)
chain = LLMChain(prompt=prompt, llm=llm)对比总结
特性 Chaining Prompts Chain of Thought Reasoning
目标 任务分解,逐步完成复杂任务 显示推理过程,提高逻辑准确性
应用场景 工作流分解、多步骤数据处理 数学推理、逻辑推理、问答
实现复杂度 高,需要设计多步任务 中等,需要设计好的 prompt
效率 较低,多次调用模型 较高,单次调用模型即可
透明性和可解释性 高,每一步可以独立检查 高,显式展示推理过程
两者并不互斥,可以结合使用:例如通过 Chaining Prompts 分解任务,在每个任务步骤中使用 CoT 提高准确性。
Evaluation
在评价LLM输出结果时,可以利用事先准备好的数据集做测试,如果返回没有固定的数据集,只想对一个回答做相关度测试,那可以直接利用LLM做评价是否满足要求。
user_message = f"""\
You are evaluating a submitted answer to a question based on the context \
that the agent uses to answer the question.
Here is the data:
[BEGIN DATA]
************
[Question]: {cust_msg}
************
[Context]: {context}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the context. \
Ignore any differences in style, grammar, or punctuation.
Answer the following questions:
- Is the Assistant response based only on the context provided? (Y or N)
- Does the answer include information that is not provided in the context? (Y or N)
- Is there any disagreement between the response and the context? (Y or N)
- Count how many questions the user asked. (output a number)
- For each question that the user asked, is there a corresponding answer to it?
Question 1: (Y or N)
Question 2: (Y or N)
...
Question N: (Y or N)
- Of the number of questions asked, how many of these questions were addressed by the answer? (output a number)
""" user_message = f"""\
You are comparing a submitted answer to an expert answer on a given question. Here is the data:
[BEGIN DATA]
************
[Question]: {cust_msg}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
choice_strings: ABCDE
"""