https://learn.deeplearning.ai/courses/improving-accuracy-of-llm-applications
Introduction and Overview
1 介绍了这篇课程,主要使用的llama3 8b的模型然后做了简单的prompt尝试。
2 介绍了模型幻觉,然后提出使用fine-tuning去解决幻觉。
Lesson 1: Llama 3 Basics
Note: You can access the
dataandutilsubdirectories used in the course. In Jupyter version 6, this is via the File>Open menu. In Jupyter version 7 this is in View> File Browser
Also note that as models and systems change, the output of the models may shift from the video content.
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env fileimport laminillm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")prompt = """\
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Please write a birthday card for my good friend Andrew\
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""result = llm.generate(prompt, max_new_tokens=200)
print(result)prompt2 = (
"<|begin_of_text|>" # Start of prompt
"<|start_header_id|>system<|end_header_id|>\n\n" # header - system
"You are a helpful assistant." # system prompt
"<|eot_id|>" # end of turn
"<|start_header_id|>user<|end_header_id|>\n\n" # header - user
"Please write a birthday card for my good friend Andrew"
"<|eot_id|>" # end of turn
"<|start_header_id|>assistant<|end_header_id|>\n\n" # header - assistant
)
print(prompt2)prompt == prompt2def make_llama_3_prompt(user, system=""):
system_prompt = ""
if system != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>\n\n{system}"
f"<|eot_id|>"
)
prompt = (f"<|begin_of_text|>{system_prompt}"
f"<|start_header_id|>user<|end_header_id|>\n\n"
f"{user}"
f"<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>\n\n"
)
return prompt system_prompt = user_prompt = "You are a helpful assistant."
user_prompt = "Please write a birthday card for my good friend Andrew"
prompt3 = make_llama_3_prompt(user_prompt, system_prompt)
print(prompt3)prompt == prompt3user_prompt = "Tell me a joke about birthday cake"
prompt = make_llama_3_prompt(user_prompt)
print(prompt)result = llm.generate(prompt, max_new_tokens=200)
print(result)Try some prompts of your own!
Llama 3 can generate SQL
question = (
"Given an arbitrary table named `sql_table`, "
"write a query to return how many rows are in the table."
)
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))question = """Given an arbitrary table named `sql_table`,
help me calculate the average `height` where `age` is above 20."""
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))question = """Given an arbitrary table named `sql_table`,
Can you calculate the p95 `height` where the `age` is above 20?"""
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))question = ("Given an arbitrary table named `sql_table`, "
"Can you calculate the p95 `height` "
"where the `age` is above 20? Use sqlite.")
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))Try some questions of your own!
Creating a SQL Agent
本节内容使用一个简答的sql例子,说明了模型的输出会产生幻觉(似乎是对的),但是其实返回的结果并不对。
Lesson 2: Create a SQL Agent
Note: You can access the
dataandutilsubdirectories used in the course. In Jupyter version 6, this is via the File>Open menu. In Jupyter version 7 this is in View> File Browser
Also note that as models and systems change, the output of the models may shift from the video content.
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env fileimport lamini import logging
import sqlite3
import pandas as pd
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")# Meta Llama 3 Instruct uses a prompt template, with special tags used to indicate the user query and system prompt.
# You can find the documentation on this [model card](https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3/#meta-llama-3-instruct).
def make_llama_3_prompt(user, system=""):
system_prompt = ""
if system != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>\n\n{system}<|eot_id|>"
)
return f"<|begin_of_text|>{system_prompt}<|start_header_id|>user<|end_header_id|>\n\n{user}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"def get_schema():
return """\
0|Team|TEXT
1|NAME|TEXT
2|Jersey|TEXT
3|POS|TEXT
4|AGE|INT
5|HT|TEXT
6|WT|TEXT
7|COLLEGE|TEXT
8|SALARY|TEXT eg.
"""user = """Who is the highest paid NBA player?"""system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""print(system)prompt = make_llama_3_prompt(user, system)print(llm.generate(prompt, max_new_tokens=200))def get_updated_schema():
return """\
0|Team|TEXT eg. "Toronto Raptors"
1|NAME|TEXT eg. "Otto Porter Jr."
2|Jersey|TEXT eg. "0" and when null has a value "NA"
3|POS|TEXT eg. "PF"
4|AGE|INT eg. "22" in years
5|HT|TEXT eg. `6' 7"` or `6' 10"`
6|WT|TEXT eg. "232 lbs"
7|COLLEGE|TEXT eg. "Michigan" and when null has a value "--"
8|SALARY|TEXT eg. "$9,945,830" and when null has a value "--"
"""system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_updated_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""prompt = make_llama_3_prompt(user, system)print(prompt)print(llm.generate(prompt, max_new_tokens=200))Structured Output
We'd like to be able to get just SQL output so we don't have to parse the query from the model response. For this we can use structured output.
result = llm.generate(prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)resultThis is great, now we can directly query with the output
df = pd.read_sql(result['sqlite_query'], con=engine)dfDiagnose Hallucinations
The wrong query looks like this:
SELECT NAME, SALARY
FROM nba_roster
WHERE salary != '--'
ORDER BY CAST(SALARY AS REAL) DESC
LIMIT 1;The correct query is:
SELECT salary, name
FROM nba_roster
WHERE salary != '--'
ORDER BY CAST(REPLACE(REPLACE(salary, '$', ''), ',','') AS INTEGER) DESC
LIMIT 1;query="""SELECT salary, name
FROM nba_roster
WHERE salary != '--'
ORDER BY CAST(REPLACE(REPLACE(salary, '$', ''), ',','') AS INTEGER) DESC
LIMIT 1;"""
df = pd.read_sql(query, con=engine)
print(df)Create an evaluation
本节内容主要是评估模型的质量以及怎样提高。
好的评价指标是可量化的.
how to evaluate:
Start small 20-100 examples
Quality > Quantity
Focus the era you want to improve
Practical tips for evaluation dataset.
Easiest examples that still fail
Use an adversarial playground
set a next accuracy target for your llm
Use an llm to score your output
Get the llm to output a numerical score.
provide the question, generate an answer, and scoring method through the prompt of your eval llm.
Evaluation is iterative
Expand you evaluation datasets with more breadth
Improve score mechanism to catch misktakes.
Add harder hallucintion examples, as the model learns to get those eaiser ones.
L3: Create an Evaluation
Note: You can access the
dataandutilsubdirectories used in the course. In Jupyter version 6, this is via the File>Open menu. In Jupyter version 7 this is in View> File Browser
Also note that as models and systems change, the output of the models may shift from the video content.
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env file!cat data/gold-test-set.jsonlquestion = "What is the median weight in the NBA?"import lamini from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_promptllm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)generated_query = llm.generate(prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)
print(generated_query)import pandas as pd
import sqlite3
engine = sqlite3.connect("./nba_roster.db")The following cell is expected to create an error.
df = pd.read_sql(generated_query['sqlite_query'], con=engine)import pandas as pd
import sqlite3
engine = sqlite3.connect("./nba_roster.db")
try:
df = pd.read_sql(generated_query['sqlite_query'], con=engine)
print(df)
except Exception as e:
print(e)Try Agent Reflection to see if that can improve the query.
reflection = f"Question: {question}. Query: {generated_query['sqlite_query']}. This query is invalid (gets the error Execution failed on sql 'SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,'') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL': near \"FROM\": syntax error), so it cannot answer the question. Write a corrected sqlite query."reflection_prompt = make_llama_3_prompt(reflection, system)reflection_promptreflection_query = llm.generate(reflection_prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)reflection_querytry:
df = pd.read_sql(reflection_query['sqlite_query'], con=engine)
print(df)
except Exception as e:
print(e)Look at the right answer
correct_sql = "select CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) as percentile from nba_roster order by percentile limit 1 offset (select count(*) from nba_roster)/2;"correct_sqldf_corrected = pd.read_sql(correct_sql, con=engine)
print(df_corrected)Evaluate over a larger dataset
import logging
import os
from datetime import datetime
from pprint import pprint
from typing import AsyncIterator, Iterator, Union
import sqlite3
from tqdm import tqdm
import pandas as pd
import jsonlines
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_node import GenerationNode
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_pipeline import GenerationPipeline
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
class Args:
def __init__(self,
max_examples=100,
sql_model_name="meta-llama/Meta-Llama-3-8B-Instruct",
gold_file_name="gold-test-set.jsonl",
training_file_name="archive/generated_queries.jsonl",
num_to_generate=10):
self.sql_model_name = sql_model_name
self.max_examples = max_examples
self.gold_file_name = gold_file_name
self.training_file_name = training_file_name
self.num_to_generate = num_to_generatedef load_gold_dataset(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
for index, obj in enumerate(reversed(list(reader))):
if index >= args.max_examples:
break
yield PromptObject(prompt="", data=obj)path = "data/gold-test-set.jsonl"
with jsonlines.open(path) as reader:
data = [obj for obj in reader]datapoint = data[4]datapointdatapoint = data[7]datapointsystem = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = datapoint["question"]
prompt = make_llama_3_prompt(user, system)
generated_sql = llm.generate(prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)
print(generated_sql)df = pd.read_sql(generated_sql['sqlite_query'], con=engine)
print(df)query_succeeded = False
try:
df = pd.read_sql(generated_sql['sqlite_query'], con=engine)
query_succeeded = True
print("Query is valid")
except Exception as e:
print(
f"Failed to run SQL query: {generated_sql}"
)reference_sql = datapoint["sql"]
ref_df = pd.read_sql(reference_sql, con=engine)
print(ref_df)# Here's how to wrap that all up in a runnable class
class QueryStage(GenerationNode):
def __init__(self, model_name):
super().__init__(
model_name=model_name,
max_new_tokens=200,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"sqlite_query": "str"},
*args,
**kwargs,
)
return results
def postprocess(self, obj: PromptObject):
# Run both the generated and reference (Gold Dataset) SQL queries
# Assessing whether the SQL queries succeeded in hitting the database (not correctness yet!)
query_succeeded = False
try:
logger.error(f"Running SQL query '{obj.response['sqlite_query']}'")
obj.data["generated_query"] = obj.response["sqlite_query"]
df = pd.read_sql(obj.response["sqlite_query"], con=engine)
obj.data['df'] = df
logger.error(f"Got data: {df}")
query_succeeded = True
except Exception as e:
logger.error(
f"Failed to run SQL query: {obj.response['sqlite_query']}"
)
logger.info(f"Running reference SQL query '{obj.data['sql']}'")
df = pd.read_sql(obj.data["sql"], con=engine)
logger.info(f"Got data: {df}")
obj.data['reference_df'] = df
logger.info(f"For question: {obj.data['question']}")
logger.info(f"For query: {obj.response['sqlite_query']}")
obj.data["query_succeeded"] = query_succeeded
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_prompt(obj.data))
obj.prompt = new_prompt
def make_prompt(self, data: dict):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = data["question"]
return {
"user": user,
"system": system,
}Compare strings.
str(df).lower() == str(ref_df).lower()Use an LLM to compare.
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
system_promptuser_prompt = (
f"========== Dataframe 1 =========\n{str(df).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(ref_df).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"llm_similarity_prompt = make_llama_3_prompt(user_prompt, system_prompt)llm_similarity = llm.generate(llm_similarity_prompt, output_type={"explanation": "str", "similar": "bool"}, max_new_tokens=200)llm_similaritystr(df).lower() == str(ref_df).lower() or llm_similarity["similar"]# How to wrap it up in a class
class ScoreStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
logger.debug("ScoreStage Generate")
results = super().generate(
prompt,
output_type={"explanation": "str", "similar": ["true", "false"]},
*args,
**kwargs,
)
logger.debug(f"ScoreStage Results {results}")
return results
def preprocess(self, obj: PromptObject):
obj.prompt = make_llama_3_prompt(**self.make_prompt(obj))
logger.info(f"Scoring Stage Prompt:\n{obj.prompt}")
def postprocess(self, obj: PromptObject):
logger.info(f"Postprocess")
obj.data['is_matching'] = self.is_matching(obj.data, obj.response)
obj.data['explanation'] = obj.response["explanation"]
obj.data['similar'] = obj.response["similar"] == "true"
def is_matching(self, data, response):
return (str(data.get('df',"None")).lower() == str(data['reference_df']).lower()
or response['similar'] == "true")
def make_prompt(self, obj: PromptObject):
# Your evaluation model compares SQL output from the generated and reference SQL queries, using another LLM in the pipeline
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
user_prompt = (
f"========== Dataframe 1 =========\n{str(obj.data.get('df','None')).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(obj.data['reference_df']).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
return {
"system": system_prompt,
"user": user_prompt
}class EvaluationPipeline(GenerationPipeline):
def __init__(self, args):
super().__init__()
self.query_stage = QueryStage(args.sql_model_name)
self.score_stage = ScoreStage()
def forward(self, x):
x = self.query_stage(x)
x = self.score_stage(x)
return xasync def run_eval(dataset, args):
results = await run_evaluation_pipeline(dataset, args)
print("Total results:", len(results))
return results
async def run_evaluation_pipeline(dataset, args):
results = EvaluationPipeline(args).call(dataset)
result_list = []
pbar = tqdm(desc="Saving results", unit=" results")
async for result in results:
result_list.append(result)
pbar.update()
return result_listdef save_eval_results(results, args):
base_path = "./data/results"
now = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
experiment_name = f"nba_sql_pipeline_{now}"
experiment_dir = os.path.join(base_path, experiment_name)
os.makedirs(os.path.join(base_path, experiment_name))
# Write args to file
args_file_name = f"{experiment_dir}/args.txt"
with open(args_file_name, "w") as writer:
pprint(args.__dict__, writer)
def is_correct(r):
if (
(r.data["query_succeeded"] and r.data['is_matching']) or
r.data["generated_query"] == r.data['sql']
):
return True
return False
# Write sql results and errors to file
results_file_name = f"{experiment_dir}/sql_results.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if not is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"reference_sql": result.data['sql'],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
results_file_name = f"{experiment_dir}/sql_errors.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
# Write statistics to file
average_sql_succeeded = sum(
[result.data["query_succeeded"] for result in results]
) / len(results)
average_correct = sum(
[result.data["query_succeeded"] and result.data['is_matching'] for result in results]
) / len(results)
file_name = f"{experiment_dir}/summary.txt"
with open(file_name, "w") as writer:
print(f"Total size of eval dataset: {len(results)}", file=writer)
print(f"Total size of eval dataset: {len(results)}")
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}", file=writer)
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}")
print(f"Percent Correct SQL Query: {average_correct*100}", file=writer)
print(f"Percent Correct SQL Query: {average_correct*100}")
args = Args()
dataset = load_gold_dataset(args)
results = await run_eval(dataset, args)
save_eval_results(results, args)Finetuning, PEFT & memory tuning
Types of Finetuning
Instruction Finetuning
Memory Finetuning: get an LLM to not hallucinate

Memory finetuning:
Reduce error to zero on facts
Near-perfect on facts, pretty good at everything else


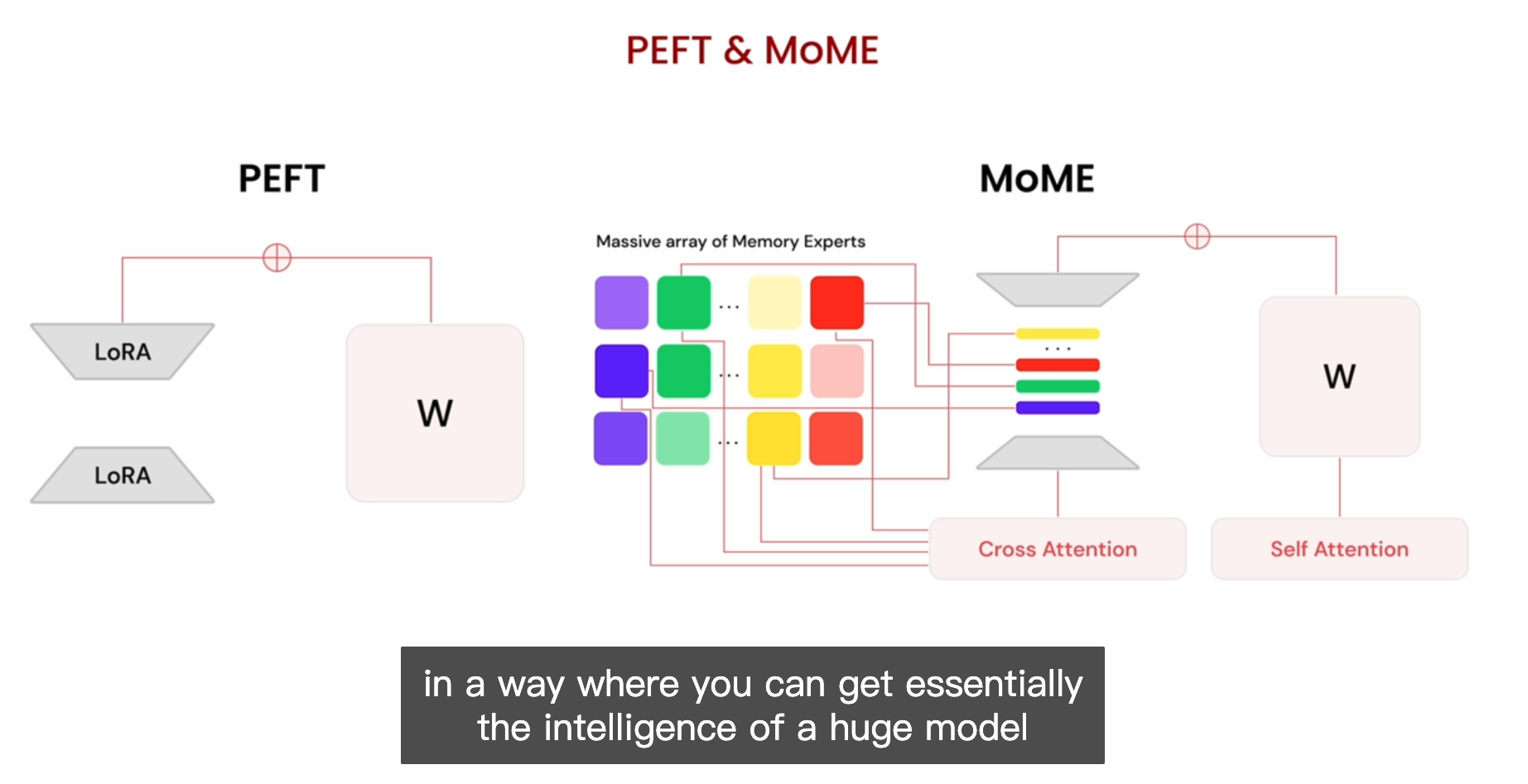
Generate Data & Finetune

Practical tips for generating data
Add examples:
few-shot or in-context learning
especailly corrected hallucinatory examples, that are similar to what the LLM needs to learn
Generate variations: can help you to reach breadth
It's worth examining what worked/didn't work
adjust prompts

不同场景的电脑硬件要求
petaflops: 每秒1015千万亿次浮点运算
exaflops: 每秒1018 (百万兆)浮点运算


L5: Generate Data & Finetune
Note: You can access the
dataandutilsubdirectories used in the course. In Jupyter version 6, this is via the File>Open menu. In Jupyter version 7 this is in View> File Browser
Also note that as models and systems change, the output of the models may shift from the video content.
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env fileimport laminiimport logging
import random
from typing import AsyncIterator, Iterator, Union
import sqlite3
import copy
from tqdm import tqdm
import pandas as pd
import jsonlines
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_node import GenerationNode
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_pipeline import GenerationPipeline
from util.get_schema import get_schema, get_schema_s
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
class Args:
def __init__(self,
max_examples=100,
sql_model_name="meta-llama/Meta-Llama-3-8B-Instruct",
gold_file_name="gold-test-set.jsonl",
training_file_name="generated_queries.jsonl",
num_to_generate=10):
self.sql_model_name = sql_model_name
self.max_examples = max_examples
self.gold_file_name = gold_file_name
self.training_file_name = training_file_name
self.num_to_generate = num_to_generateWorking Backwards from what you have:
First: From Scheme and example, generate new SQL queries
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema_s()
system += "Consider the following questions, and queries used to answer them:\n"
systemquestion = """What is the median weight in the NBA?"""
sql = "select CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) as percentile from nba_roster order by percentile limit 1 offset (select count(*) from nba_roster)/2;"
system += "Question: " + question + "\n"
system += "Query: " + sql + "\n"
print(system)user = "Write two queries that are similar but different to those above.\n"
user += "Format the queries as a JSON object, i.e.\n"
user += '{ "explanation": str, "sql_query_1" : str, "sql_query_2": str }.\n'
print(user)user += "First write an explanation of why you decided to write these new queries in about 3-5 sentences, then write valid sqlite SQL queries for each of the 2 new queries. Make sure each query is complete and ends with a ;\n"print(user)prompt = make_llama_3_prompt(user, system)llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
result = llm.generate(prompt, output_type={ "explanation": "str", "sql_query_1" : "str", "sql_query_2": "str" }, max_new_tokens=200)
print(result)def check_sql_query(query):
try:
pd.read_sql(query, con=engine)
except Exception as e:
logger.debug(f"Error in SQL query: {e}")
return False
logger.info(f"SQL query {query} is valid")
return Truecheck_sql_query(result["sql_query_1"])check_sql_query(result["sql_query_2"])# Wrap it all up together in a class
class ModelStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=300,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
prompt = self.add_template(prompt)
results = super().generate(
prompt,
output_type={
"explanation": "str",
"sql_query_1": "str",
"sql_query_2": "str",
},
*args,
**kwargs,
)
return results
async def add_template(self, prompts):
async for prompt in prompts:
new_prompt = make_llama_3_prompt(**self.make_prompt(prompt.data))
yield PromptObject(prompt=new_prompt, data=prompt.data)
async def process_results(self, results):
async for result in results:
if result is None:
continue
if result.response is None:
continue
logger.info("=====================================")
logger.info(f"Generated query 1: {result.response['sql_query_1']}")
logger.info(f"Generated query 2: {result.response['sql_query_2']}")
logger.info("=====================================")
if self.check_sql_query(result.response["sql_query_1"]):
new_result = PromptObject(prompt="", data=copy.deepcopy(result.data))
new_result.data.generated_sql_query = result.response["sql_query_1"]
yield new_result
if self.check_sql_query(result.response["sql_query_2"]):
new_result = PromptObject(prompt="", data=copy.deepcopy(result.data))
new_result.data.generated_sql_query = result.response["sql_query_2"]
yield new_result
def make_prompt(self, data):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema()
system += "Consider the following questions, and queries used to answer them:\n"
for example in data.sample:
system += "Question: " + example["question"] + "\n"
system += "Query: " + example["sql"] + "\n"
# Important: generate relevant queries to your reference data
# Ideally, close to those that are failing so you can show the model examples of how to do it right!
user = "Write two queries that are similar but different to those above.\n"
user += "Format the queries as a JSON object, i.e.\n"
user += '{ "explanation": str, "sql_query_1" : str, "sql_query_2": str }.\n'
# Next, use Chain of Thought (CoT) and prompt-engineering to help with generating SQL queries
user += "First write an explanation of why you decided to write these new queries in about 3-5 sentences, then write valid sqlite SQL queries for each of the 2 new queries. Make sure each query is complete and ends with a ;\n"
return {"system": system, "user": user}
def check_sql_query(self, query):
try:
pd.read_sql(query, con=engine)
except Exception as e:
logger.debug(f"Error in SQL query: {e}")
return False
logger.info(f"SQL query {query} is valid")
return TrueSecond: Now that you have queries, generate questions for those queries
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema() + "\n"
system += "Queries, and questions that they are used to answer:\n"
example_question = """What is the median weight in the NBA?"""
example_sql = "select CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) as percentile from nba_roster order by percentile limit 1 offset (select count(*) from nba_roster)/2;"
system += "Question: " + example_question + "\n"
system += "Query: " + example_sql + "\n"
generated_sql = result["sql_query_2"]user = "Now consider the following query.\n"
user += "Query: " + generated_sql + "\n"
user += "Write a question that this query could be used to answer.\n"
user += "Format your response as a JSON object, i.e.\n"
user += '{ "explanation": str, "question": str }.\n'
user += "First write an explanation in about 3-5 sentences, then write a one sentence question.\n"
prompt = make_llama_3_prompt(user, system)
result = llm.generate(prompt, output_type={ "explanation": "str", "question" : "str" }, max_new_tokens=200)
print(result)# Wrap it all up together in a class which generates a question
# given a query
class QuestionStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={
"explanation": "str",
"question": "str",
},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_question_prompt(obj.data))
obj.prompt = new_prompt
def make_question_prompt(self, data):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema() + "\n"
system += "Queries, and questions that they are used to answer:\n"
for example in data.sample:
system += "Query: " + example["sql"] + "\n"
system += "Question: " + example["question"] + "\n"
user = "Now consider the following query.\n"
user += "Query: " + data.generated_sql_query + "\n"
user += "Write a question that this query could be used to answer.\n"
# Using Chain of Thought (CoT) again
# This time you can do it programmatically with function calling, so you can easily extract a question out of the JSON object
user += "Format your response as a JSON object, i.e.\n"
user += '{ "explanation": str, "question": str }.\n'
user += "First write an explanation in about 3-5 sentences, then write a one sentence question.\n"
return {"system": system, "user": user}
class QueryGenPipeline(GenerationPipeline):
def __init__(self):
super().__init__()
self.model_stage = ModelStage()
self.question_stage = QuestionStage()
def forward(self, x):
x = self.model_stage(x)
x = self.question_stage(x)
return xasync def run_query_gen_pipeline(gold_queries):
return QueryGenPipeline().call(gold_queries)# Generate N samples, for every example in the gold dataset
all_examples = []
async def load_gold_queries(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
global all_examples
all_examples = [obj for obj in reader]
sample_count = args.num_to_generate
sample_size = 3
random.seed(42)
for i in range(sample_count):
example_sample = ExampleSample(random.sample(all_examples, sample_size), i)
yield PromptObject(prompt="", data=example_sample)
class ExampleSample:
def __init__(self, sample, index):
self.sample = sample
self.index = indexasync def save_generation_results(results, args):
path = f"data/training_data/{args.training_file_name}"
pbar = tqdm(desc="Saving results", unit=" results")
with jsonlines.open(path, "w") as writer:
async for result in results:
writer.write(
{
"question": result.response["question"],
"sql": result.data.generated_sql_query,
}
)
pbar.update()
for example in all_examples:
writer.write(example)
pbar.update()args = Args()
gold_queries = load_gold_queries(args)
results = await run_query_gen_pipeline(gold_queries)
await save_generation_results(results, args)display the queries just generated above
#!cat "data/training_data/generated_queries.jsonl"display the archived queries which match the course video.
!cat "data/training_data/archive/generated_queries.jsonl"Round of finetuning
Now that you have data, even if it is not perfect, go through a round of finetuning!
import logging
import os
from datetime import datetime
from pprint import pprint
from typing import AsyncIterator, Iterator, Union
import sqlite3
from tqdm import tqdm
import pandas as pd
import jsonlines
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_node import GenerationNode
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_pipeline import GenerationPipeline
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
from util.load_dataset import get_dataset
from util.get_default_finetune_args import get_default_finetune_args
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
class Args:
def __init__(self,
max_examples=100,
sql_model_name="meta-llama/Meta-Llama-3-8B-Instruct",
gold_file_name="gold-test-set.jsonl",
training_file_name="archive/generated_queries.jsonl",
num_to_generate=10):
self.sql_model_name = sql_model_name
self.max_examples = max_examples
self.gold_file_name = gold_file_name
self.training_file_name = training_file_name
self.num_to_generate = num_to_generatemake_question will take the questions and queries from the training_file and embed them in the prompt below to form the training data.
def make_question(obj):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = obj["question"]
return {"system": system, "user": user}args = Args()
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")dataset = get_dataset(args, make_question)finetune_args = get_default_finetune_args()This fine tuning step takes about 30 mintues to complete. The dispatch to run on the lamini services is commented out and the pre-computed final results of the run are provided below. You can uncomment and run if you have modified data on your own.
#llm.train(
# data_or_dataset_id=dataset,
# finetune_args=finetune_args,
# is_public=True, # For sharing
#)We can examine this pre-computed finetuning result.
llm = lamini.Lamini(model_name="a5ebf1c4879569101f32444afae5adcafbfce9c5a6ed13035fd892147f7d59bc")question = """Who is the highest paid NBA player?"""
system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)
print("Question:\n", question)print("Answer:")
print(llm.generate(prompt, max_new_tokens=200))query="SELECT salary, name FROM nba_roster WHERE salary != '--' ORDER BY CAST(REPLACE(REPLACE(salary, '$', ''), ',','') AS INTEGER) DESC LIMIT 1;"
df = pd.read_sql(query, con=engine)
print(df)Now lets run an evaluation over the eval dataset. Load code from lesson 3.
# Collapsible or utils from Lesson 3 Lab for evaluation
class QueryStage(GenerationNode):
def __init__(self, model_name):
super().__init__(
model_name=model_name,
max_new_tokens=300,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"sqlite_query": "str"},
*args,
**kwargs,
)
return results
def postprocess(self, obj: PromptObject):
# Run both the generated and reference (Gold Dataset) SQL queries
# Assessing whether the SQL queries succeeded in hitting the database (not correctness yet!)
query_succeeded = False
try:
logger.info(f"Running SQL query '{obj.response['sqlite_query']}'")
obj.data["generated_query"] = obj.response["sqlite_query"]
df = pd.read_sql(obj.response["sqlite_query"], con=engine)
obj.data['df'] = df
logger.info(f"Got data: {df}")
query_succeeded = True
except Exception as e:
logger.error(
f"Failed to run SQL query: {obj.response['sqlite_query']}"
)
logger.info(f"Running reference SQL query '{obj.data['sql']}'")
df = pd.read_sql(obj.data["sql"], con=engine)
logger.info(f"Got data: {df}")
obj.data['reference_df'] = df
logger.info(f"For question: {obj.data['question']}")
logger.info(f"For query: {obj.response['sqlite_query']}")
obj.data["query_succeeded"] = query_succeeded
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_prompt(obj.data))
obj.prompt = new_prompt
def make_prompt(self, data: dict):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question. Make sure each query ends with a semicolon:\n"
)
user = data["question"]
return {
"user": user,
"system": system,
}
class ScoreStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"explanation": "str", "similar": ["true", "false"]},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
obj.prompt = make_llama_3_prompt(**self.make_prompt(obj))
logger.info(f"Scoring Stage Prompt:\n{obj.prompt}")
def postprocess(self, obj: PromptObject):
obj.data['is_matching'] = self.is_matching(obj.data, obj.response)
obj.data['explanation'] = obj.response["explanation"]
obj.data['similar'] = obj.response["similar"] == "true"
def is_matching(self, data, response):
return (str(data.get('df',"None")).lower() == str(data['reference_df']).lower()
or response['similar'] == "true")
def make_prompt(self, obj: PromptObject):
# Your evaluation model compares SQL output from the generated and reference SQL queries, using another LLM in the pipeline
'''
Note:
Prompt tuning is important!
A previous iteration of this scoring pipeline said `Compare the following two dataframes to see if they are identical`.
That prompt turned out to be too stringent of criteria.
'''
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
user_prompt = (
f"========== Dataframe 1 =========\n{str(obj.data.get('df','None')).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(obj.data['reference_df']).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
return {
"system": system_prompt,
"user": user_prompt
}
async def run_eval(dataset, args):
results = await run_evaluation_pipeline(dataset, args)
print("Total results:", len(results))
return results
async def run_evaluation_pipeline(dataset, args):
results = EvaluationPipeline(args).call(dataset)
result_list = []
pbar = tqdm(desc="Saving results", unit=" results")
async for result in results:
result_list.append(result)
pbar.update()
return result_list
class EvaluationPipeline(GenerationPipeline):
def __init__(self, args):
super().__init__()
self.query_stage = QueryStage(args.sql_model_name)
self.score_stage = ScoreStage()
def forward(self, x):
x = self.query_stage(x)
x = self.score_stage(x)
return x
def load_gold_dataset(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
for index, obj in enumerate(reversed(list(reader))):
if index >= args.max_examples:
break
yield PromptObject(prompt="", data=obj)
def save_eval_results(results, args):
base_path = "./data/results"
now = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
experiment_name = f"nba_sql_pipeline_{now}"
experiment_dir = os.path.join(base_path, experiment_name)
os.makedirs(os.path.join(base_path, experiment_name))
# Write args to file
args_file_name = f"{experiment_dir}/args.txt"
with open(args_file_name, "w") as writer:
pprint(args.__dict__, writer)
def is_correct(r):
if (
(result.data["query_succeeded"] and result.data['is_matching']) or
result.data["generated_query"] == result.data['sql']
):
return True
return False
# Write sql results and errors to file
results_file_name = f"{experiment_dir}/sql_results.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if not is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"reference_sql": result.data['sql'],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
results_file_name = f"{experiment_dir}/sql_errors.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
# Write statistics to file
average_sql_succeeded = sum(
[result.data["query_succeeded"] for result in results]
) / len(results)
average_correct = sum(
[result.data["query_succeeded"] and result.data['is_matching'] for result in results]
) / len(results)
file_name = f"{experiment_dir}/summary.txt"
with open(file_name, "w") as writer:
print(f"Total size of eval dataset: {len(results)}", file=writer)
print(f"Total size of eval dataset: {len(results)}")
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}", file=writer)
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}")
print(f"Percent Correct SQL Query: {average_correct*100}", file=writer)
print(f"Percent Correct SQL Query: {average_correct*100}")
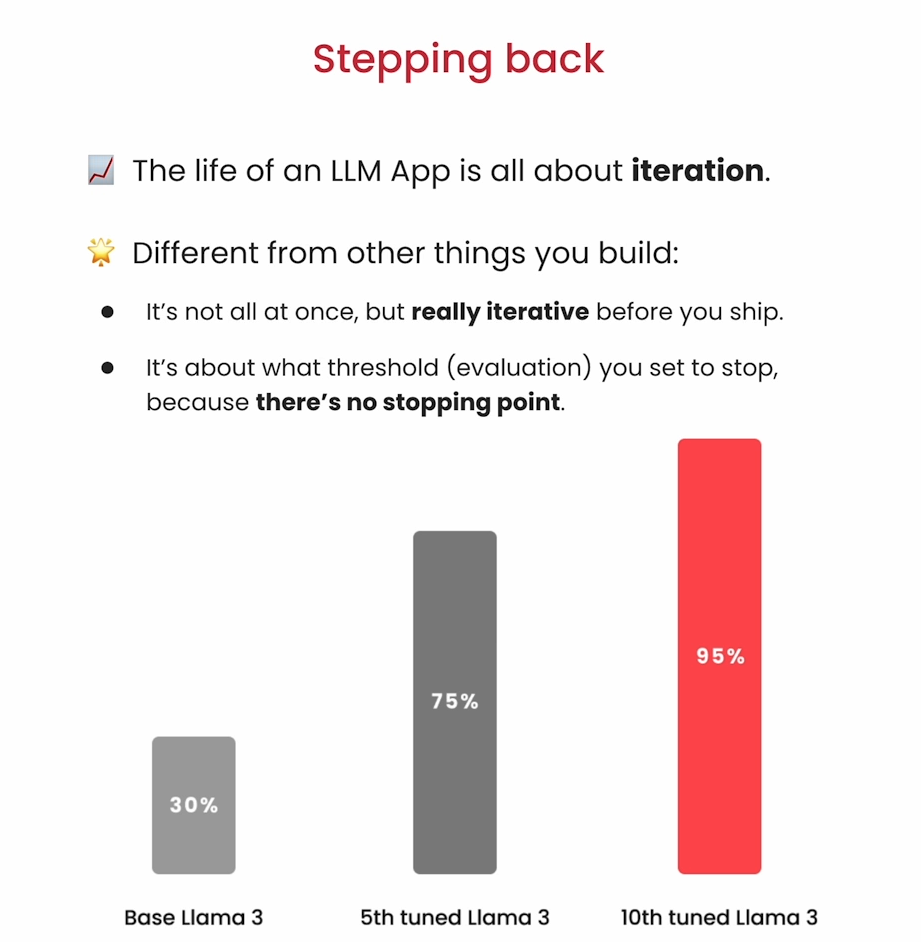
Run the evaluation and you can see there is more valid SQL and correct queries.
args = Args(sql_model_name="a5ebf1c4879569101f32444afae5adcafbfce9c5a6ed13035fd892147f7d59bc")
dataset = load_gold_dataset(args)
results = await run_eval(dataset, args)
save_eval_results(results, args)Iteration 2
Examine remaining errors.
!cat sql_errors_example.jsonl !cat "data/training_data/archive/generated_queries.jsonl" | grep "75th percentile"!cat "data/training_data/archive/generated_queries_large.jsonl" | grep "75th percentile"Filtering the dataset
Next step is filtering. Manually create functions to filter the test set.
question_set = set()
sql_set = set()
def is_not_valid_sql(question, sql):
try:
df = pd.read_sql(sql, con=engine)
return False
except Exception as e:
return True
def has_null_in_sql_or_question(question, sql):
return "null" in sql.lower() or "null" in question
def returns_empty_dataframe(question, sql):
try:
df = pd.read_sql(sql, con=engine)
return "Empty" in str(df) or "None" in str(df)
except Exception as e:
return False
def uses_avg_on_ht_column(question, sql):
return "avg(ht)" in sql.lower() or "avg(salary" in sql.lower()
filter_conditions = [is_not_valid_sql, has_null_in_sql_or_question, returns_empty_dataframe, uses_avg_on_ht_column]
def training_semicolon(sql):
if sql.strip()[-1] != ";":
return sql.strip() + ";"
return sql
with jsonlines.open("data/training_data/archive/generated_queries_large.jsonl", "r") as reader:
with jsonlines.open("data/training_data/generated_queries_large_filtered.jsonl", "w") as writer:
for r in reader:
if r["question"] in question_set or r["sql"] in sql_set:
continue
question_set.add(r["question"])
sql_set.add(r["sql"])
if any(c(r['question'], r['sql']) for c in filter_conditions):
continue
sql = training_semicolon(r['sql'])
writer.write(
{
"question": r["question"],
"sql": sql,
}
)Check the filtered dataset.
!cat "data/training_data/archive/generated_queries_large_filtered.jsonl" | grep "75th percentile"Manually clean the dataset. This has been done for you.
!cat "data/training_data/archive/generated_queries_large_filtered_cleaned.jsonl" | grep "75th percentile"Look at some other errors in the dataset.
The following cell is expected to create an error
df = pd.read_sql("SELECT AVG(CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) FROM nba_roster WHERE WT!= 'NA') as median", con=engine)!cat "data/training_data/archive/generated_queries.jsonl" | grep "median weight"df = pd.read_sql("SELECT COLLEGE, COUNT(*) as count FROM nba_roster WHERE COLLEGE!= '--' GROUP BY COLLEGE ORDER BY count DESC LIMIT 1", con=engine)
print(df)Add more examples of median weight queries. (Done for you).
!cat "data/training_data/archive/generated_queries_large_filtered_cleaned.jsonl" | grep "median weight"!cat "data/training_data/archive/generated_queries_large_filtered_cleaned.jsonl" | grep "median"# Model tuned on `archive/generated_queries_large_filtered_cleaned.jsonl`
llm = lamini.Lamini(model_name="63fd73a775daf24216b46c680a1e963a8d1e02b21bca43fcea6c26737d2e887e")question = """What is the median age of the Chicago Bulls?"""
system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)
print("Question:\n", question)
print("Answer:")
sql = llm.generate(prompt, max_new_tokens=200)
print(sql)df = pd.read_sql(sql, con=engine)
print(df)Here is a larger pre-prepared dataset.
!cat data/gold-test-set-v2.jsonlargs = Args(training_file_name="archive/generated_queries_v2_large_filtered_cleaned.jsonl")llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")dataset = get_dataset(args, make_question)
finetune_args = get_default_finetune_args()This fine tuning step takes about 30 mintues to complete. The dispatch to run on the Lamini services is commented out and the pre-computed final results of the run are provided below. You can uncomment and run if you have modified data on your own.
#llm.train(
# data_or_dataset_id=dataset,
# finetune_args=finetune_args,
# is_public=True, # For sharing
#)Run eval platform again from lab 3.
# Collapsible or utils from Lesson 3 Lab for evaluation
class QueryStage(GenerationNode):
def __init__(self, model_name):
super().__init__(
model_name=model_name,
max_new_tokens=300,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"sqlite_query": "str"},
*args,
**kwargs,
)
return results
def postprocess(self, obj: PromptObject):
# Run both the generated and reference (Gold Dataset) SQL queries
# Assessing whether the SQL queries succeeded in hitting the database (not correctness yet!)
query_succeeded = False
try:
logger.info(f"Running SQL query '{obj.response['sqlite_query']}'")
obj.data["generated_query"] = obj.response["sqlite_query"]
df = pd.read_sql(obj.response["sqlite_query"], con=engine)
obj.data['df'] = df
logger.info(f"Got data: {df}")
query_succeeded = True
except Exception as e:
logger.error(
f"Failed to run SQL query: {obj.response['sqlite_query']}"
)
logger.info(f"Running reference SQL query '{obj.data['sql']}'")
df = pd.read_sql(obj.data["sql"], con=engine)
logger.info(f"Got data: {df}")
obj.data['reference_df'] = df
logger.info(f"For question: {obj.data['question']}")
logger.info(f"For query: {obj.response['sqlite_query']}")
obj.data["query_succeeded"] = query_succeeded
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_prompt(obj.data))
obj.prompt = new_prompt
def make_prompt(self, data: dict):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"#"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = data["question"]
return {
"user": user,
"system": system,
}
class ScoreStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"explanation": "str", "similar": ["true", "false"]},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
obj.prompt = make_llama_3_prompt(**self.make_prompt(obj))
logger.info(f"Scoring Stage Prompt:\n{obj.prompt}")
def postprocess(self, obj: PromptObject):
obj.data['is_matching'] = self.is_matching(obj.data, obj.response)
obj.data['explanation'] = obj.response["explanation"]
obj.data['similar'] = obj.response["similar"] == "true"
def is_matching(self, data, response):
return (str(data.get('df',"None")).lower() == str(data['reference_df']).lower()
or response['similar'] == "true")
def make_prompt(self, obj: PromptObject):
# Your evaluation model compares SQL output from the generated and reference SQL queries, using another LLM in the pipeline
'''
Note:
Prompt tuning is important!
A previous iteration of this scoring pipeline said `Compare the following two dataframes to see if they are identical`.
That prompt turned out to be too stringent of criteria.
'''
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
user_prompt = (
f"========== Dataframe 1 =========\n{str(obj.data.get('df','None')).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(obj.data['reference_df']).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
return {
"system": system_prompt,
"user": user_prompt
}
async def run_eval(dataset, args):
results = await run_evaluation_pipeline(dataset, args)
print("Total results:", len(results))
return results
async def run_evaluation_pipeline(dataset, args):
results = EvaluationPipeline(args).call(dataset)
result_list = []
pbar = tqdm(desc="Saving results", unit=" results")
async for result in results:
result_list.append(result)
pbar.update()
return result_list
class EvaluationPipeline(GenerationPipeline):
def __init__(self, args):
super().__init__()
self.query_stage = QueryStage(args.sql_model_name)
self.score_stage = ScoreStage()
def forward(self, x):
x = self.query_stage(x)
x = self.score_stage(x)
return x
def load_gold_dataset(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
for index, obj in enumerate(reversed(list(reader))):
if index >= args.max_examples:
break
yield PromptObject(prompt="", data=obj)
def save_eval_results(results, args):
base_path = "./data/results"
now = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
experiment_name = f"nba_sql_pipeline_{now}"
experiment_dir = os.path.join(base_path, experiment_name)
os.makedirs(os.path.join(base_path, experiment_name))
# Write args to file
args_file_name = f"{experiment_dir}/args.txt"
with open(args_file_name, "w") as writer:
pprint(args.__dict__, writer)
def is_correct(r):
if (
(result.data["query_succeeded"] and result.data['is_matching']) or
result.data["generated_query"] == result.data['sql']
):
return True
return False
# Write sql results and errors to file
results_file_name = f"{experiment_dir}/sql_results.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if not is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"reference_sql": result.data['sql'],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
results_file_name = f"{experiment_dir}/sql_errors.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
# Write statistics to file
average_sql_succeeded = sum(
[result.data["query_succeeded"] for result in results]
) / len(results)
average_correct = sum(
[result.data["query_succeeded"] and result.data['is_matching'] for result in results]
) / len(results)
file_name = f"{experiment_dir}/summary.txt"
with open(file_name, "w") as writer:
print(f"Total size of eval dataset: {len(results)}", file=writer)
print(f"Total size of eval dataset: {len(results)}")
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}", file=writer)
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}")
print(f"Percent Correct SQL Query: {average_correct*100}", file=writer)
print(f"Percent Correct SQL Query: {average_correct*100}")
Use pretrained model trained with the above dataset.
args = Args(sql_model_name="3f7e740c0ea2227631a30d293b51564ad1b80727c3768a3b136fbae93170c1e2", gold_file_name='gold-test-set-v2.jsonl')
dataset = load_gold_dataset(args)
results = await run_eval(dataset, args)
save_eval_results(results, args)