课程链接:https://b.geekbang.org/member/course/intro/100613101
学习使用的免费链接:https://freegeektime.com/
介绍
本课程分为下面几个章节 (以下摘录于课程原文)
热身篇和架构基础篇。带你搭建知识体系,夯实基础,为后续学习做好准备。重点学习 AI 系统的技术发展历程,如何快速利用开源工具实现自用级大模型底座的搭建,AI 系统有哪些成熟范式,它们又和现在的 AI 大模型系统有何联系?
技术原理篇。为你梳理 AI 大模型技术的发展脉络,深入解读大模型关键技术背后的技术原理,包括预训练模型的前世今生、GPT 1-3 核心技术,大语言模型的未来展望。学完这个部分,你就能跟上 AI 大模型技术的最新进展。
架构实战篇。重点讲解工业级 AI 大模型系统的关键技术,深入学习 AI 大模型系统最前沿设计理念和工程方法。聚焦如何解决 AI 大模型系统的新问题?如何构建工业级的 AI 大模型系统?AI 大模型系统领域还有哪些难题尚待解决?
前沿拓展篇。开阔视野,带你了解大模型产业的最新情况。洞察机遇,分享大厂的 AI 人才考察重点,为你的职业发展提供更多可能
热身篇
基础模型:
兼顾参数量大(大型模型),训练数据量大(大量数据大规模训练)和迁移学习能力强(适应多种下游任务)几点才能够叫做基础模型
ReAct:
Thought:表示让大语言模型思考,目前需要做哪些行为,行为的对象是谁,它要采取的行为是不是合理的。
Act:也就是针对目标对象,执行具体的动作,比如调用 API 这样的动作,然后收集环境反馈的信息。
Obs:它代表把外界观察的反馈信息,同步给大语言模型,协助它做出进一步的分析或者决策。
零代码快速搭建(Flowise)
Flowise,用于零代码搭建 LLM 应用平台。通过使用它,你可以在一分钟内搭建起刚才的应用。
首先是 Flowise 的安装,在安装完成后通过下面的指令启动 Flowise 服务(推荐用 Linux/Mac)。
$ npm install -g flowise
$ npx flowise start --FLOWISE_USERNAME=user --FLOWISE_PASSWORD=1234进入浏览器打开 http://localhost:3000,输入用户名和密码。
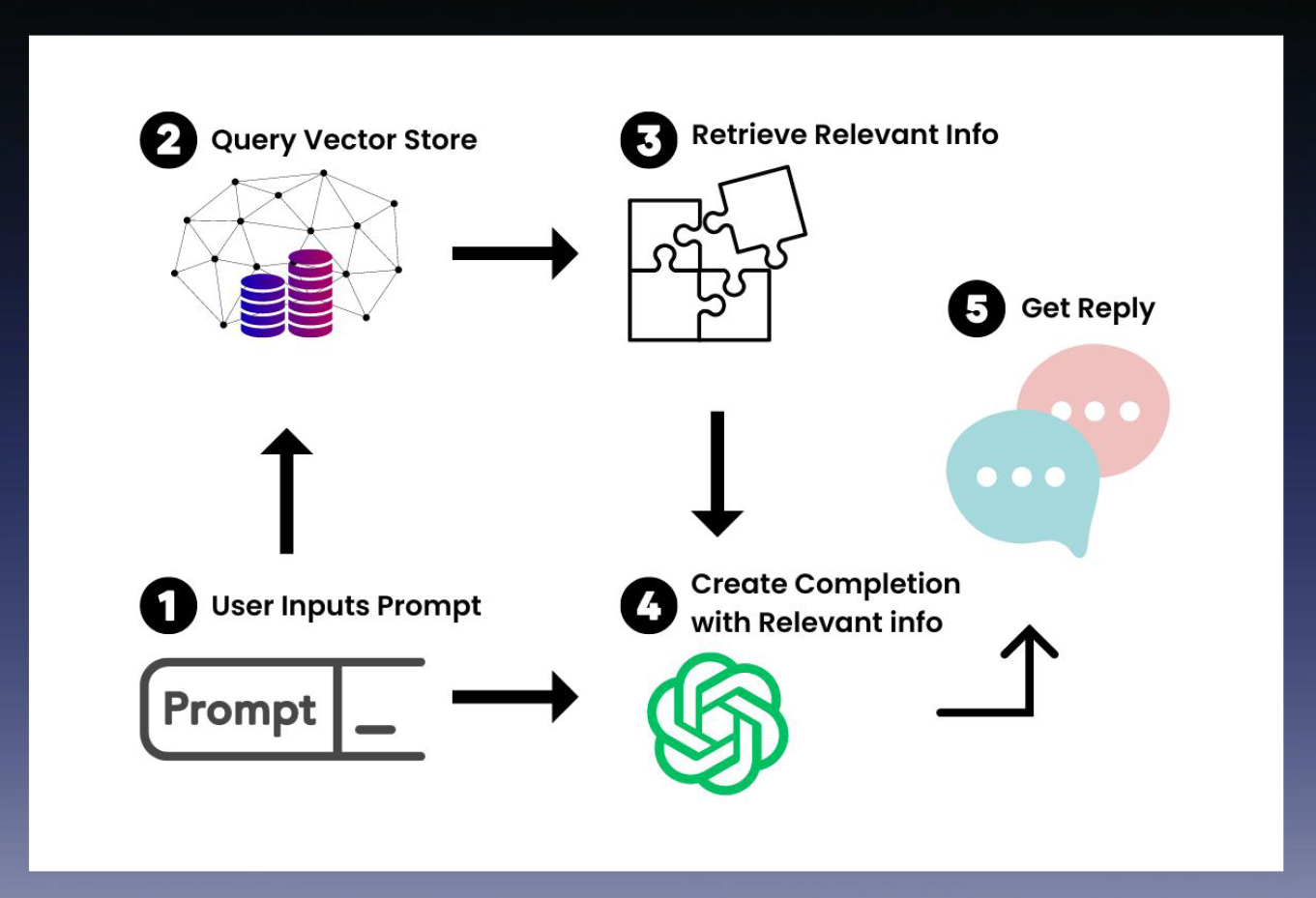
搭建RAG
Local AI
$ git clone https://github.com/go-skynet/LocalAI
$ cd LocalAI工业级大模型
提出了目前这些框架的问题,距离工业级大模型的应用还是很遥远。
问题:
将 LangChain 和 AutoGPT 认作真正的 LLM 系统
将 Embedding 检索奉为记忆增强的“圭臬”
无视开源大模型的内容生成质量问题
架构基础篇
AIRC系统建模方法
策略建模
以电商举例说明AIRC 系统如何对海量的内容进行在线实时的排序。我们先要给系统设定北极星指标,并通过业务特点进行漏斗建模,之后将系统抽象成召回,排序两个模块,来提高排序效率,完成海量内容的在线实时排序。
特征工程
从浅层特征到隐层特征
从低维到高维
从高维到世界(将高维向量的意义体现在语义上)
如何衡量预料中词的关系
下面的是 Word2Vec 的思想,笔者曾经本科毕设也用到过,是 NLP 预训练模型(PTM)的重要工作。现在的 GPT 系列最早也是从 Word2Vec 一步步发展出来的。

Skip-gram:通过给定一个中心词用它来预测前后单词
训练数据格式
"likes" -> ["John", "to"]
"to" -> ["likes", "watch"]
"watch" -> ["to", "movies"]
"movies" -> ["watch", "and"]CBOW:模型的目标是通过前后词来预测中心词
训练数据格式
"John" -> ["likes"]
"to" -> ["likes", "watch"]
"likes" -> ["Mary"]
"watch" -> ["to"]
"movies" -> ["watch"]
"and" -> ["movies"]模型工程
人工智能在学术上的三大学派,它们分别是符号主义学派、连接主义学派和行为主义学派,其中的代表分别是知识图谱、深度学习和强化学习。
监督学习
点击率模型
介绍了相应的拟合函数,损失函数以及梯度下降算法
对比学习(Contrastive Learning)
这是大语言模型技术的核心方法。
强化学习(Reinforcement learning)
通过“感知”+“行动”来控制
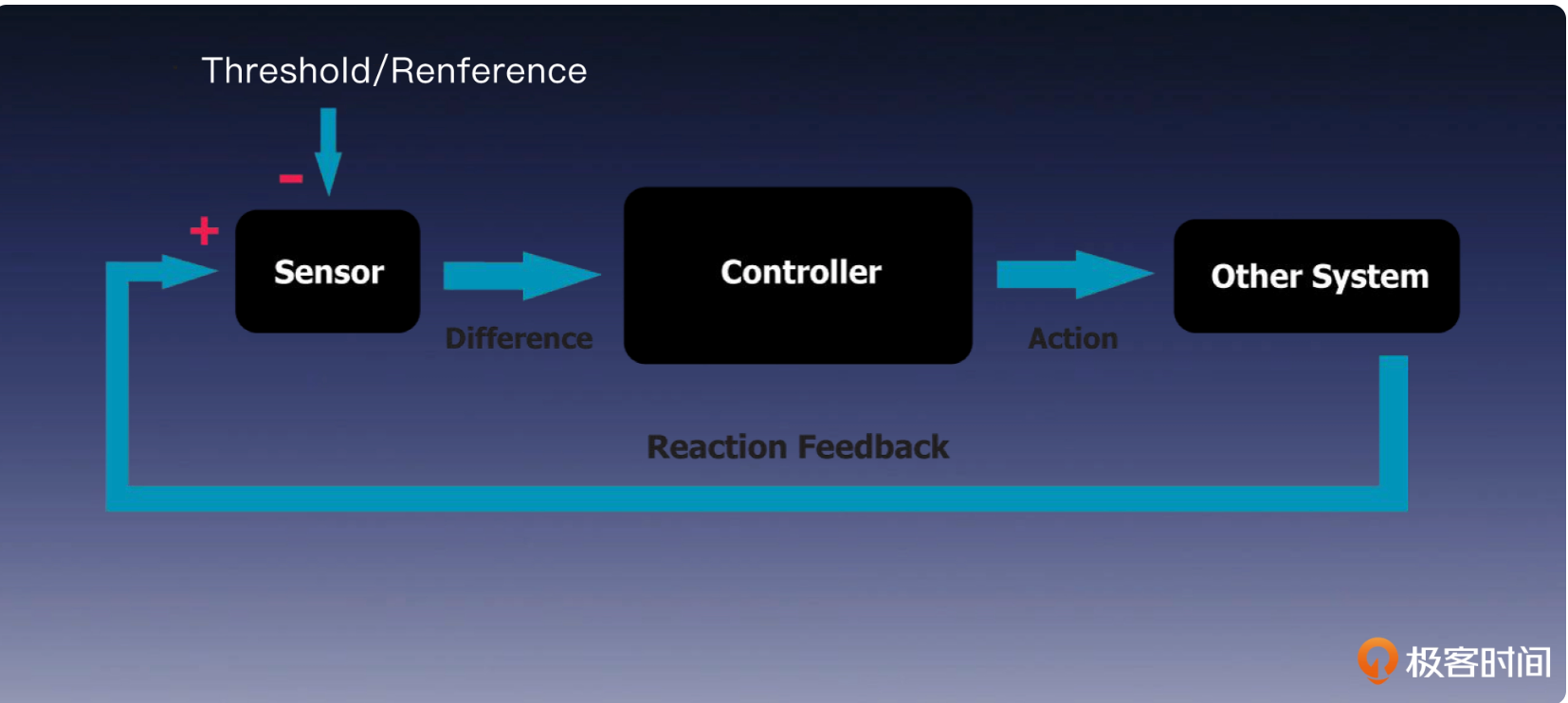
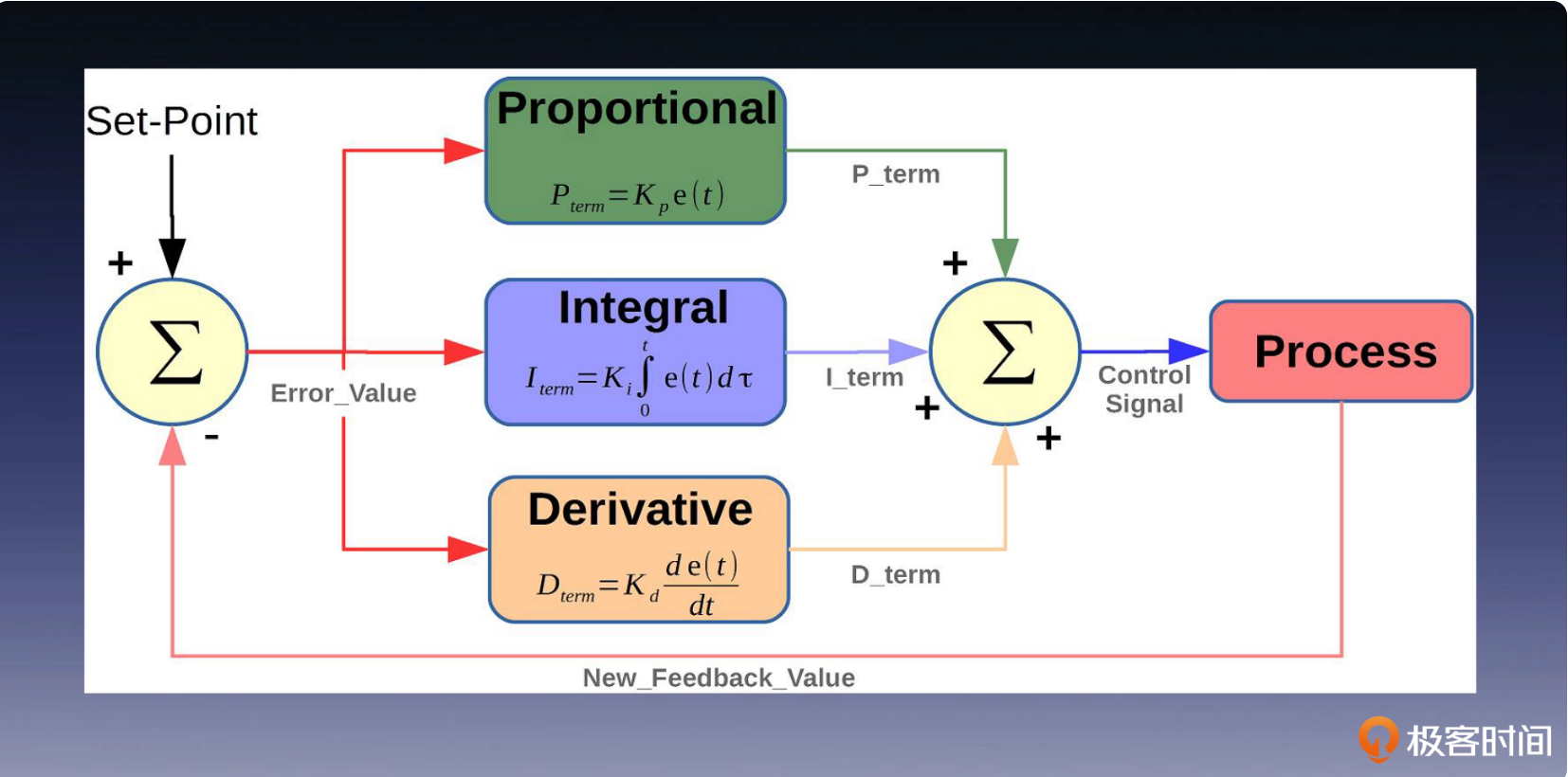
PID是典型的感知+行动机制,下面是PID控制器的架构
与上面PID算法不同的是:强化学习不依赖于预先标记的数据,而是通过与环境的交互来进行自主学习(不需要主动提供错误信息),根据奖励信号的反馈进行实时的策略更新。
数据算法
用户画像
用户画像数据被视为每个产品最宝贵的资源,同时也是 AI 系统中价值最高的数据。
人群扩展算法
挖掘潜在高净值用户。比如识别出与“保时捷”车主相似的用户,扩大推广活动的覆盖范围。
提高风控能力。比如通过用户相似行为和特征,发现黑灰产作案团伙,识别出潜在欺诈活动。
提高冷启动推荐效果。比如利用相似人的特征代表未知新用户,做出更准确的推荐决策。
GraphSAGE算法
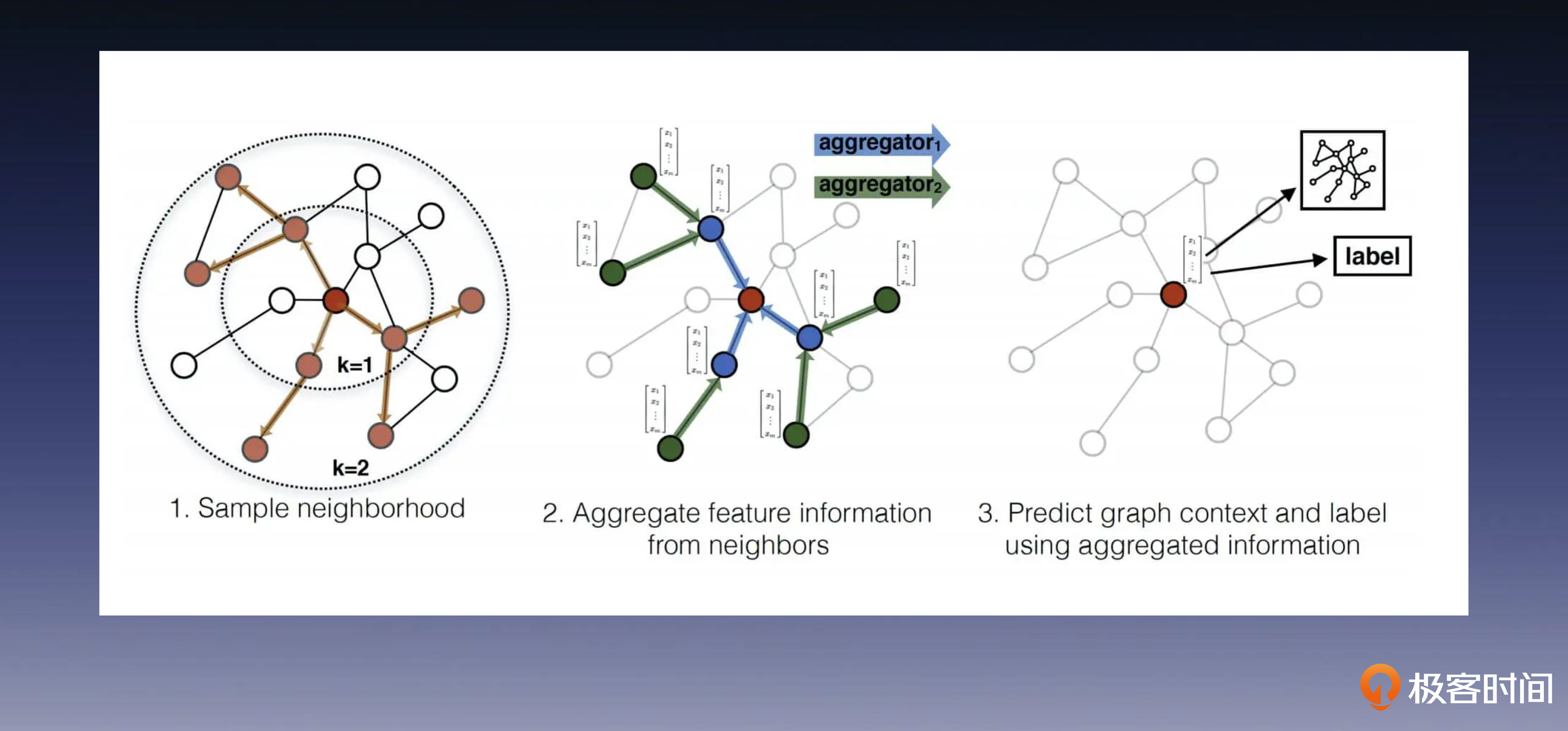
建图:将用户作为节点,如果用户之间若存在相同属性,则增加一条边。
采集:随机选一个幸运节点,向它的各个方向走两步,路径会形成一棵树,如左图。你需要重复此过程,采出若干棵树,留作备用。
聚合:随机取一棵树,将第三层节点和向第二层聚合(如中图),生成第二层节点表征。之后再对第二层和树根做同样的操作,每棵树都如法炮制。
训练:将树根原来的表征与上一步的聚合表征拼接起来,以此来保留图中结构信息(如右图),然后与一个参数相乘,就得到了树根的融合表征。
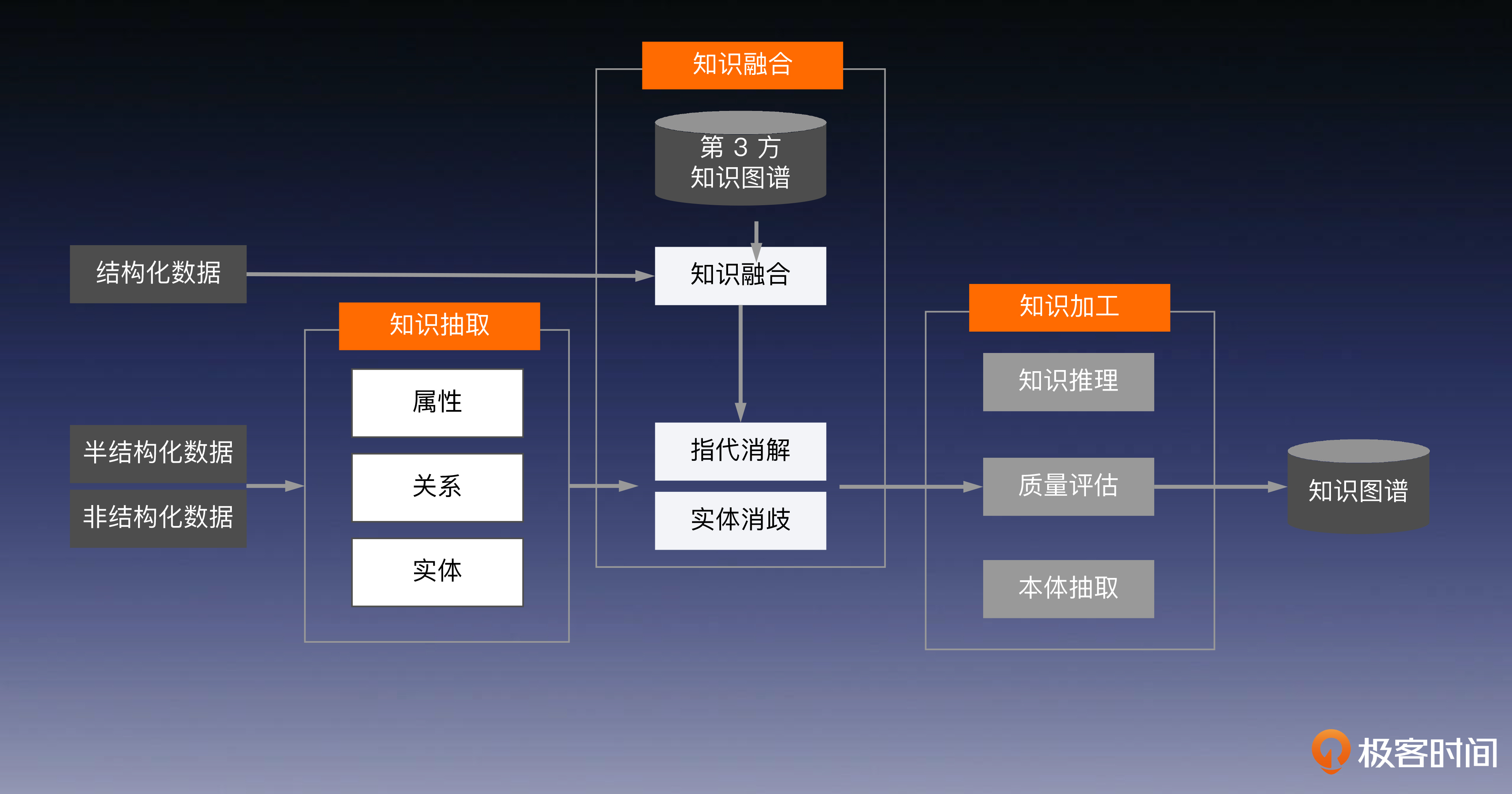
知识图谱(KG)
构建知识图谱的三个主要步骤:知识抽取、知识融合和知识加工
系统构建
离线系统
全量模型训练
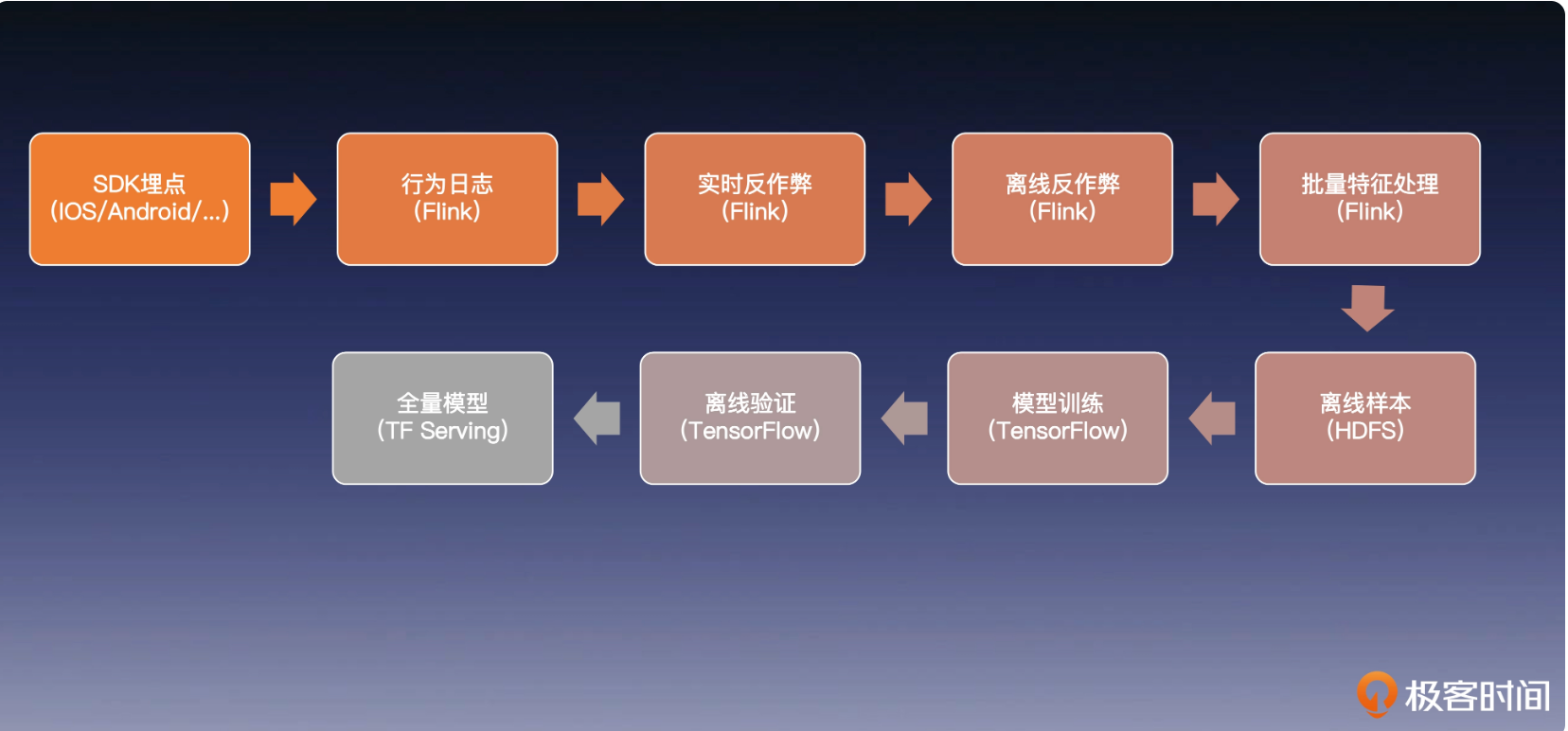
安全的日志系统
通过加密防止日志被篡改
反作弊系统
因为要获取真实的流量数据,而不是通过一些作弊机制刷出来的
样本生成
对原数据做筛选,拼接,以符合训练数据格式
模型训练
通过各种机器学习,深度学习算法进行训练
模型验证
使用离线的数据验证模型的性能以及效率
增量模型训练
第一级火箭使用全量(例如过去一年)的样本,进行前面提到的完整模型的训练流程。由于这个过程需要大量数据,训练的算力开销特别大,因此我们应该尽量减少全量模型的训练频率,例如一周训练一次就可以了,这也是许多大公司的惯例。
第二级火箭是模型的短期增量训练,使用第一级训练出的模型和最近一天的样本数据,训练一个最新的二级模型。二级模型通常每天训练一次,来更新前一天的二级模型,当然如果刚好赶上一级模型更新,则可以停更一天,这是为了确保每天的增量都得到更新。
第三级火箭指的是,把在二级模型部署到线上后,24 小时内产生的增量数据,实时地喂给在线模型进行训练和更新,来确保在线模型的实效性。不过,因为在线增量训练中缺少离线反作弊的参与,所以不能用增量训练替代全量训练,需要另外两级火箭做安全性和实时性的平衡。
存储索引
倒排索引
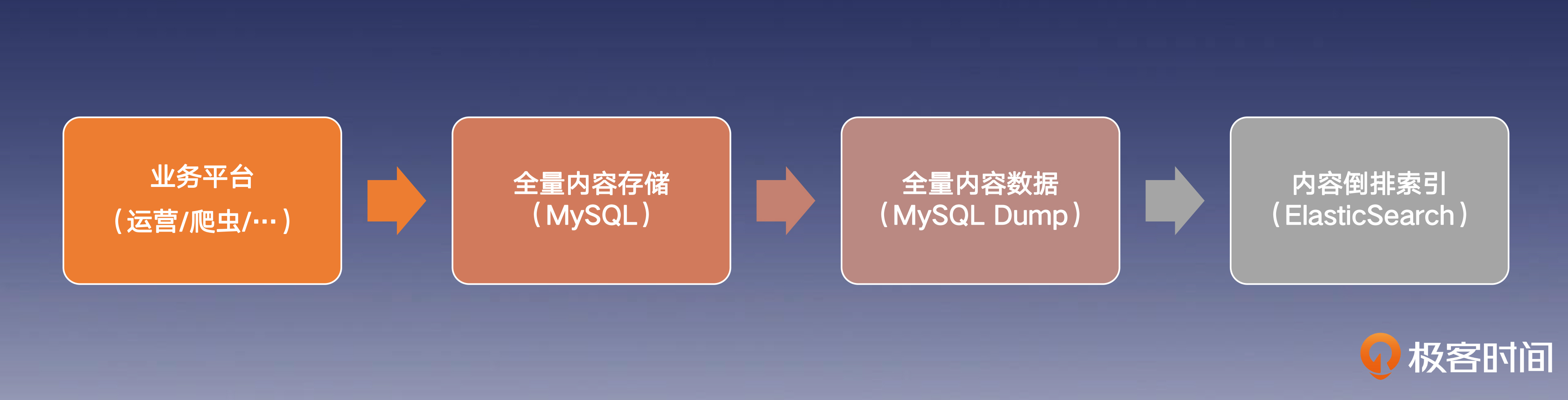
向量索引
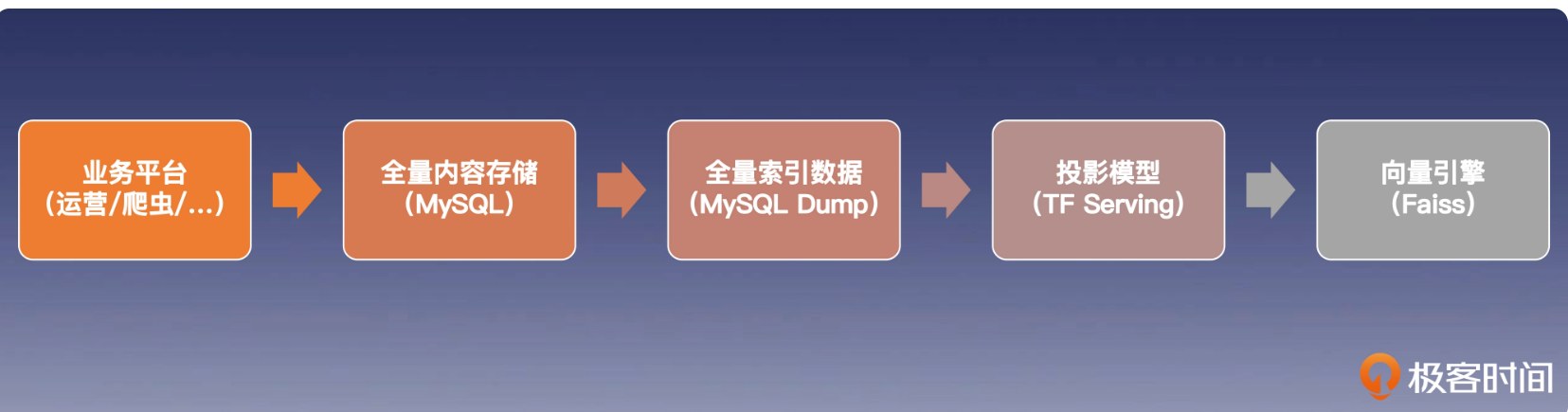
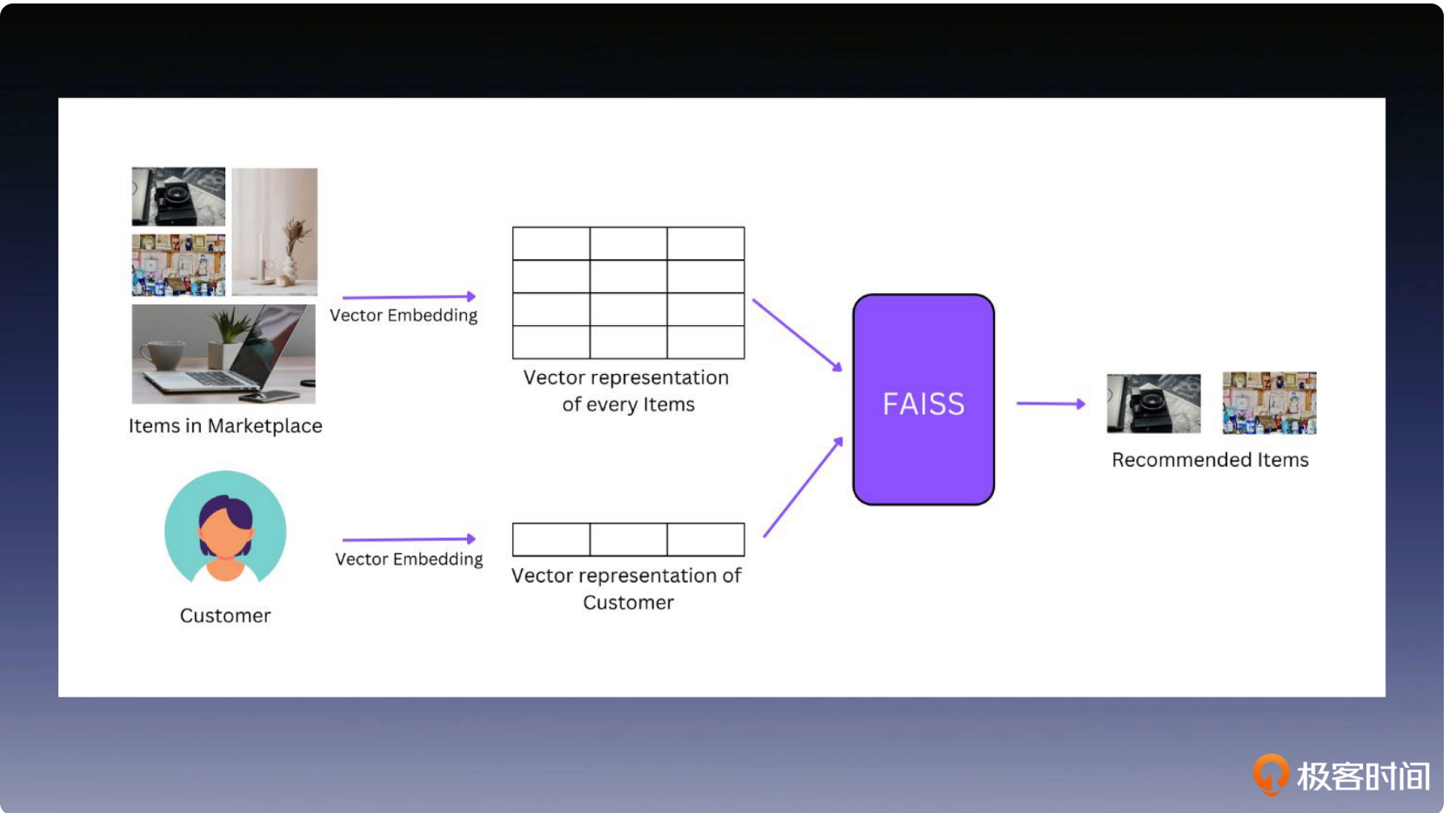
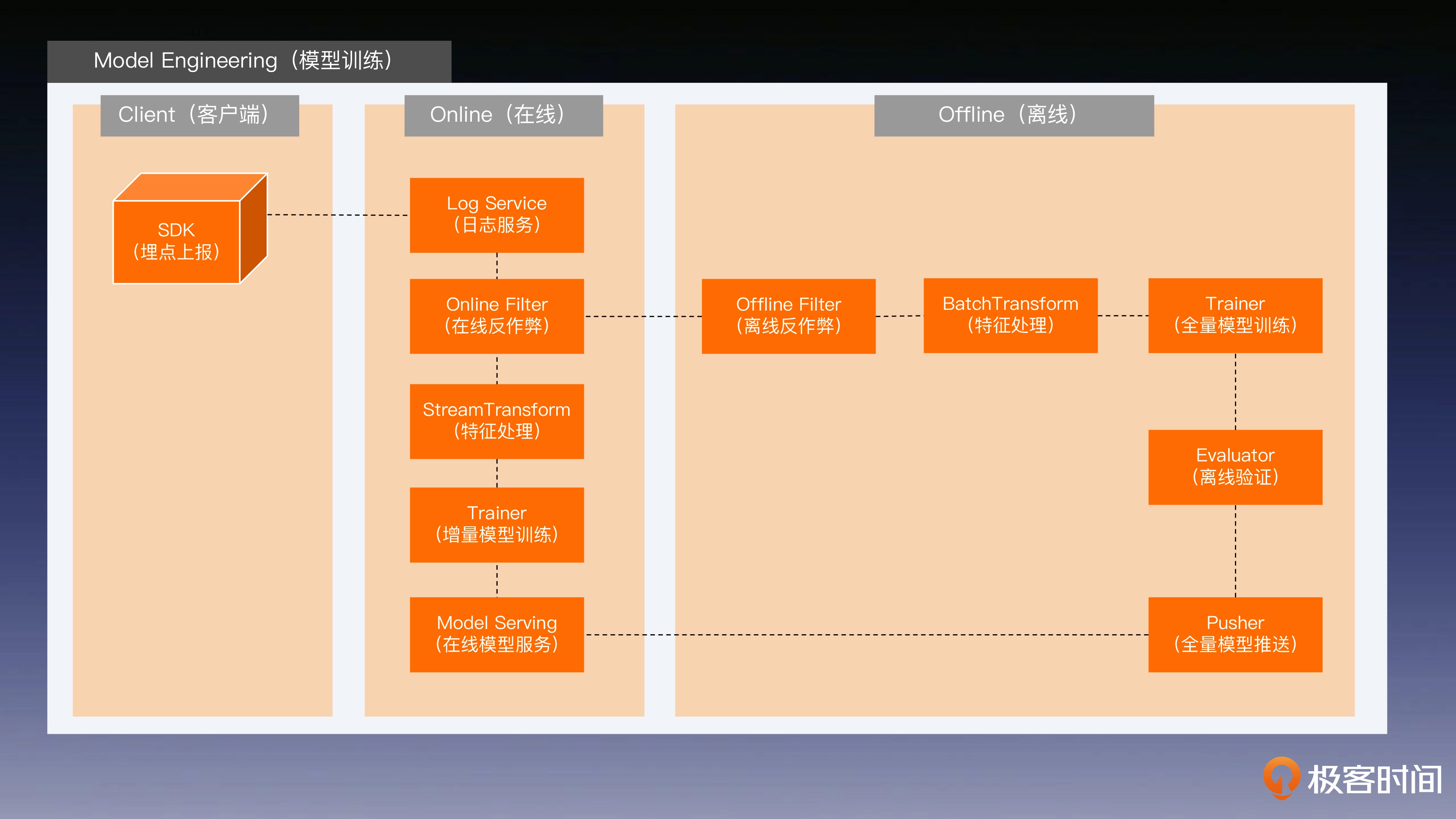
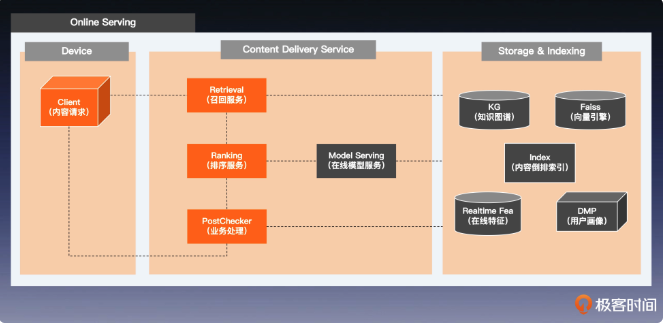
在线系统
这一节,笔者认为原文写的很无章法,很多东西一笔带过,因此这里笔者写的也不大好,只是简单的截图。
排序服务
指标排序
通过控制排序因子,影响产品业务表现
下图的点击率,收购率,付款率,单价都是各个指标因子。

控制因子

多方博弈
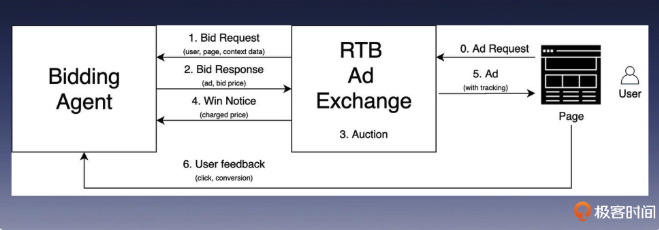
实时竞价问题
实时竞价智能体
RTB: RealTime Bidding
多智能体博弈
经典的人工智能系统架构
一些问题以及思考
构建一个程序,支持根据文档中出现的内容,搜索本地所有文本文档,你觉得应该分为哪几个步骤?(提示:倒排索引)
通过系统 API 遍历所有本地文本文件,遍历过程中使用 restfulAPI 写入 < 文件地址,全文 > 到 elasticsearch 构建倒排索引。
通过 restfulAPI 调用 elasticsearch 接口查询倒排,获得文件地址列表。
进一步如果需要根据你的使用习惯,让程序猜测你现在要使用哪个文件,把排名前十的文件推荐给你,要求将时延控制在 100ms 内,你会怎么做?(提示:多路召回)
开发一个后台进程订阅系统日志,解析文件使用时段,文件使用时系统活跃进程和当天是星期几,分别对其建立倒排索引(使用时段 / 活跃进程 / 星期几三路召回)。
在用户打开程序时立刻获取当前所处时段,系统活跃进程和当天是星期几,随后触发各个并行查询,对各个倒排索引查询,查询时每路只返回前 N 个文件即可;最后对多路返回结果根据文件最后修改时间进行归并排序。
独热编码是如何处理分类特征的?
对于有 N 个不同取值的分类特征,独热编码会创建一个长度为 N 的二进制向量,其中只有一个位置为 1,表示该分类特征的取值。
为什么需要进行正交的空间投影?
在没有得到特征之间的彼此关系时,让特征之间正交可以消除相互影响,避免模型得到错误信息。
解释一下在高维空间刻画特征距离的意义和作用。
富含语义关系的空间中的各个特征更接近于它们在真实世界之间的关系,模型可以利用这些信息更好地完成任务。
如果让你设计一个模型来完成文本摘要、文本问答、机器翻译等各类 NLP 任务,该为这个多任务学习算法准备什么样的训练数据?
这里提两个思路,第一个思路是传统 NLP 多任务学习的思路。
为文本摘要、文本问答、机器翻译等各类 NLP 任务准备的训练数据可以包括以下内容。
文本摘要数据:可以使用新闻文章、学术论文、产品说明等文本数据来训练文本摘要模型。这些数据可以用来训练生成摘要的模型,也可以用来训练评估摘要质量的模型。
文本问答数据:可以使用问答数据集来训练文本问答模型。这些数据集通常包含问题和答案的对应关系。
机器翻译数据:可以使用平行语料库来训练机器翻译模型。平行语料库是指由同一段文本用不同语言表示的语料库。
具体来说,可以将上述数据集进行合并,以形成一个更大的多任务学习数据集。例如,可以将文本摘要数据和文本问答数据合并起来,以训练一个能够生成摘要和回答问题的模型。
第二个思路则是 GPT3(大模型)的思路,也就是用所有互联网上的语料做一个大力出奇迹的多任务学习数据集 CommonCrawl。
设计一个对话系统,让它在行为学派的学习框架下,自动优化自己的对话能力,给出大致流程即可。
RLHF(大模型):其实这节课就是在为后面基于人类反馈的强化学习算法做铺垫,因为这是 GPT3.5 的核心贡献。
你认为 ChatGPT 中的主体、客体和环境数据分别是什么?如何基于用户、内容和场景的特征来优化 ChatGPT 的内容生成质量?答出大概思路即可。
其实和搜索引擎一模一样:用户、文档和应用环境,这也是 NewBing 打响第一枪的原因。
如何区分场景特征和用户特征,比如“用户最近 30 分钟内,观看的运动类视频数量”是哪类特征?
“用户最近 30 分钟的商品点击数量”是场景特征。场景特征的变化频率比较高,所以模型的敏感性很大一部分来自于场景特征。
如果让你选择三个算法,放入知识图谱的三个步骤中,你会选哪三个?
知识图谱不是一个具体算法,而是知识抽取,知识融合和知识加工这一整套构图思路。
在线增量模型的训练为什么要用三级火箭,直接用增量模型不可以吗?
不可以,因为在线的增量数据由于需要保证实时性,没有做离线反作弊,可能存在作弊数据混入其中。所以要每天替换二级火箭。
想一想,内容分发系统和现在的生成式 AI 系统的共性是什么?
内容分发系统和内容生成系统本质上都是在为用户交付内容。
我们知道 Bard 是支持给出多个草稿并展示最优结果的,如果让你为 ChatGPT 对同一问题生成的几个不同答案排序,你会怎么做?
这个任务本质上是在做模型生成的诸多内容和用户提问之间的相关性排序,其实完全可以用 AIRC 的方式来做,目前的大多工业级大模型系统也确实是这么做的。
技术原理篇
图像
介绍了CNN,
文本
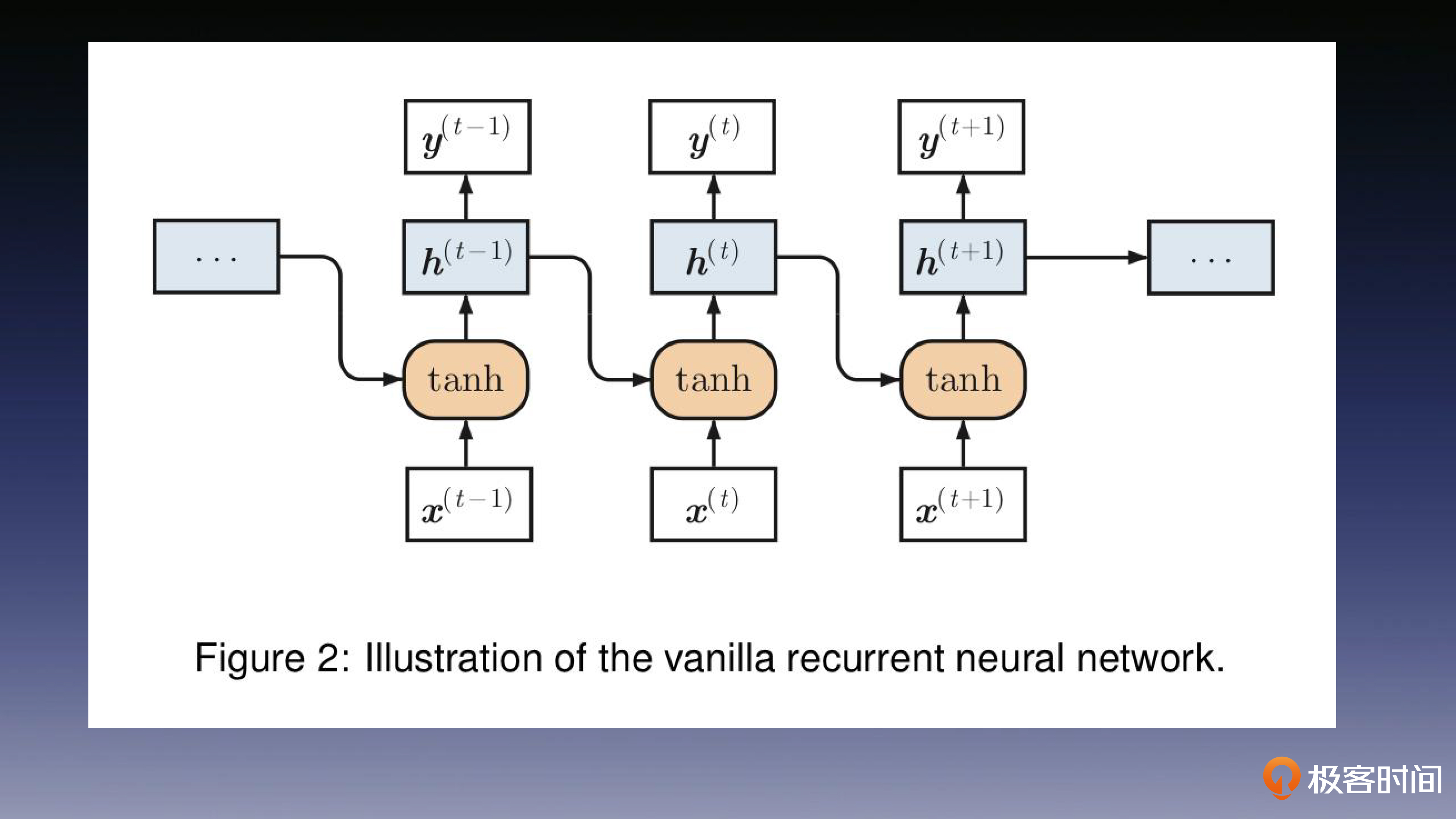
介绍了RNN(循环神经网络),LSTM(Long short-term memory),Seq2Seq(序列到序列模型),Attention(注意力机制)
RNN
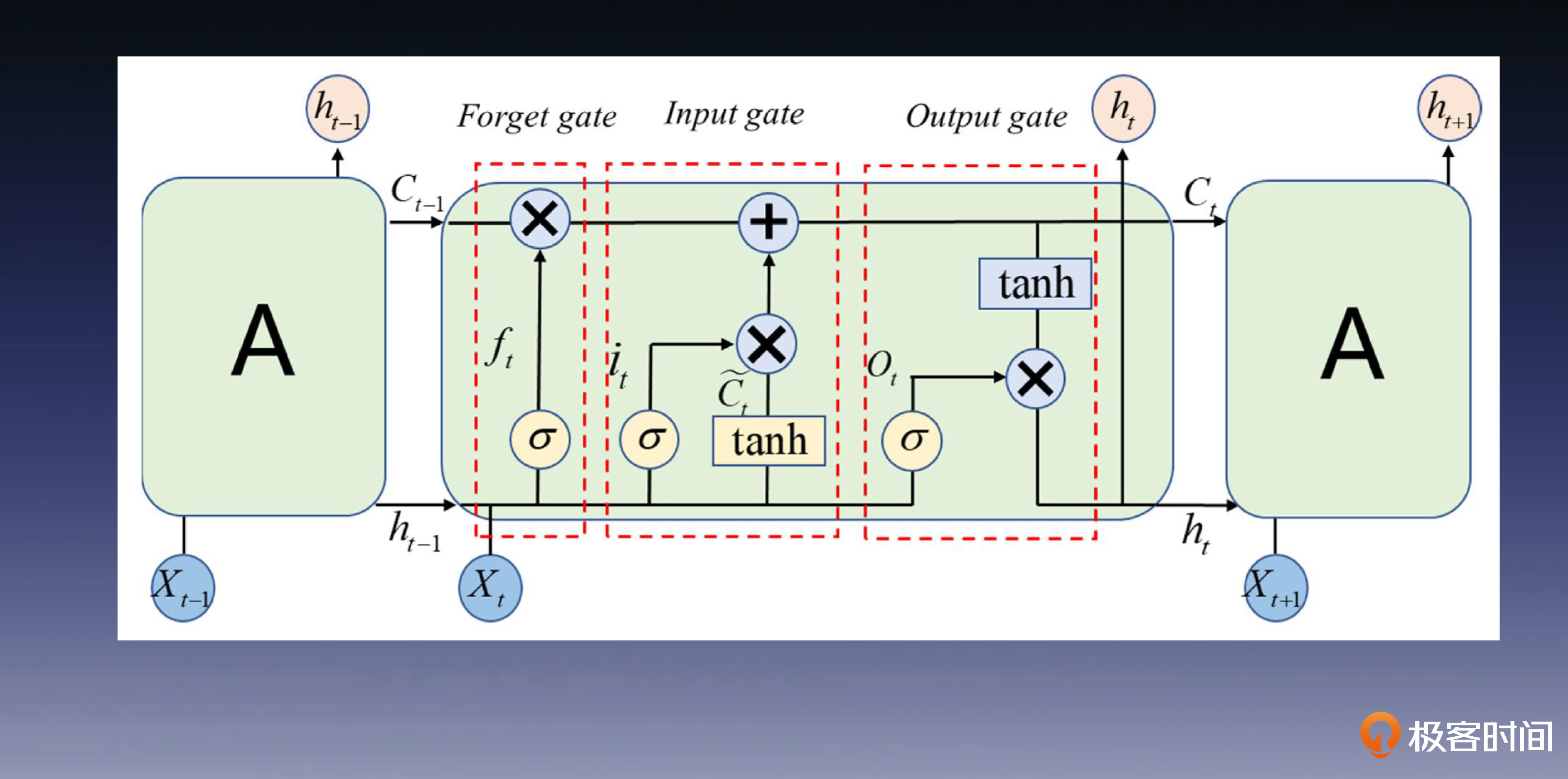
LSTM
在RNN基础上加了三道门控制单位:遗忘门、输入门和输出门,这些“门”控制了信息的流动和保留,使网络能够有选择地记住或遗忘相关信息,从而有效解决了梯度消失和爆炸问题。
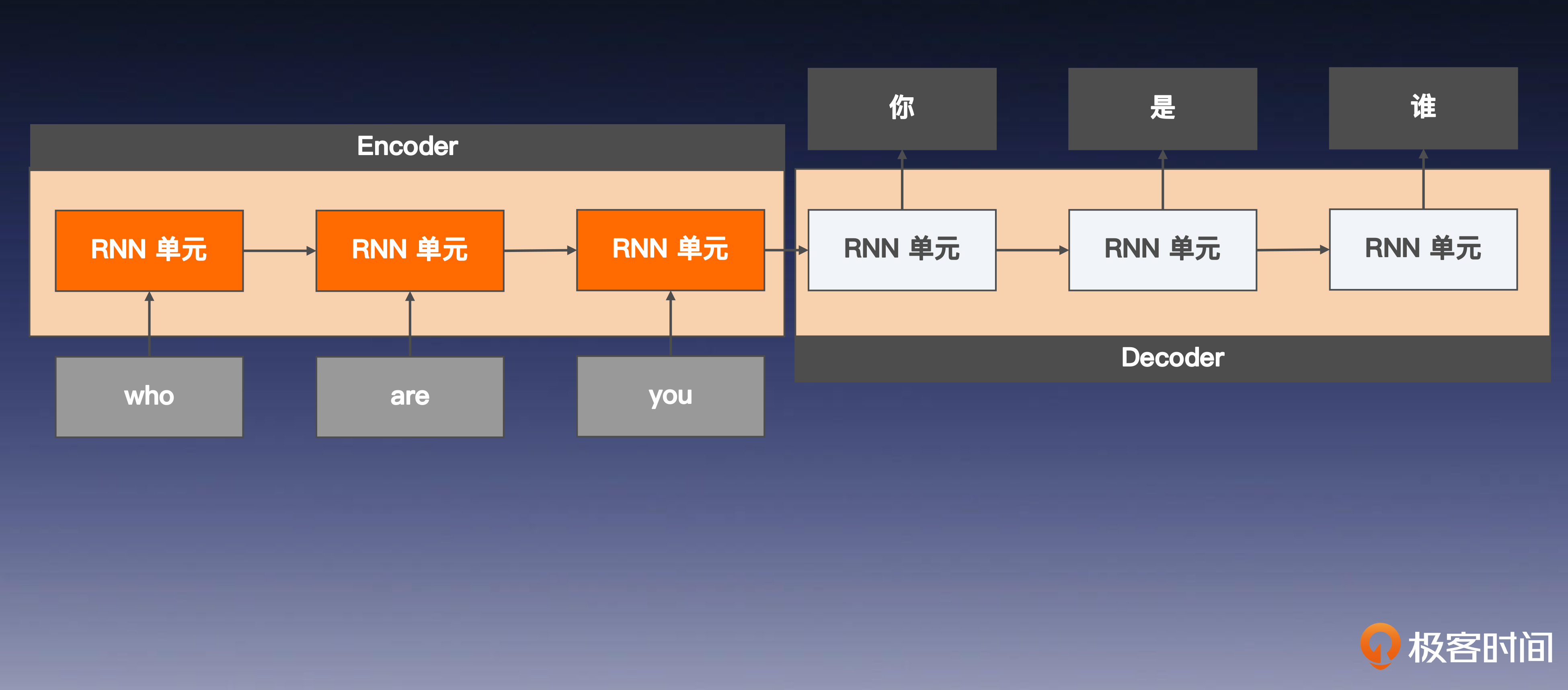
Seq2Seq
编码器-解码器结构,首先编码器会将输入序列从源空间(例如中文)投影到一个高维语义空间的向量表示中。接着,解码器将这个高维向量从语义空间映射回目标空间(例如英文),生成一个新的序列作为翻译输出。
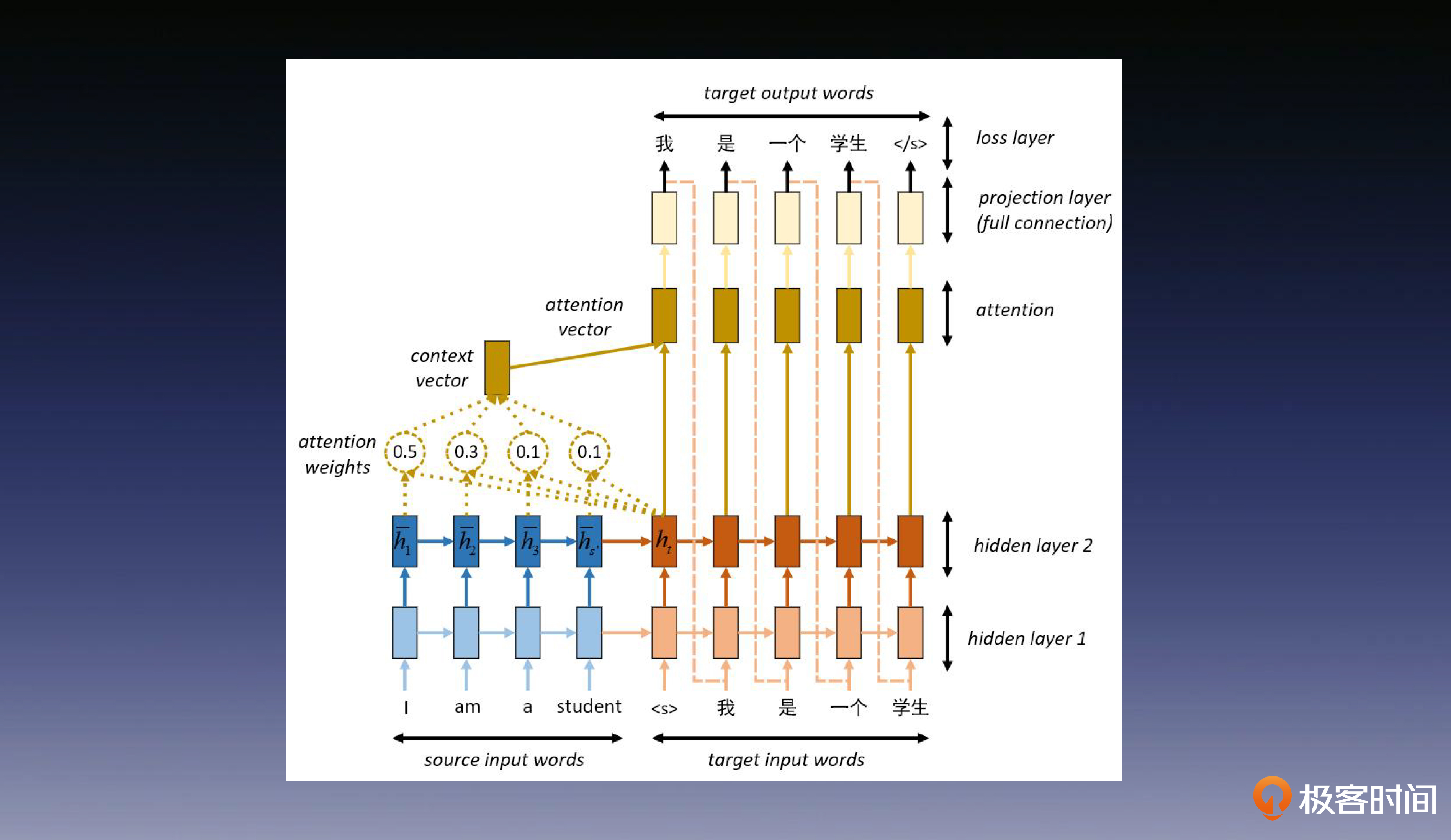
注意力机制
通过注意力机制可以提取出文本的重点,有利于建立更长的语义依赖。
Transformer
来自于论文《Attention is all you need》,是大模型的基础,重中之重。
发展过程
Word2Vec:对比学习加持特征表征
ELMo:语言模型消除歧义
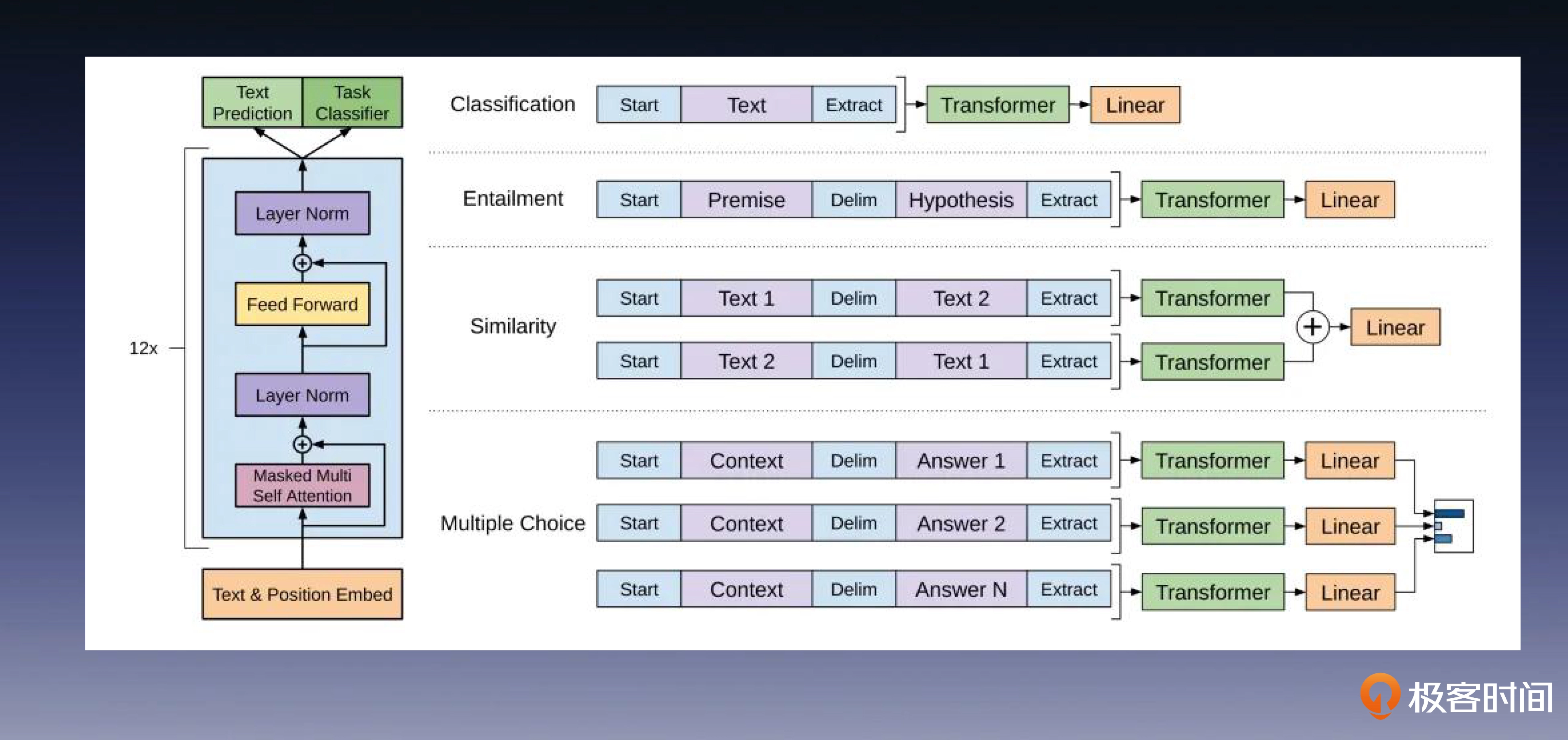
GPT:预训练模型走上舞台
GPT只用了Transformer中的decoder架构,可以通过下游任务的数据做微调。首先,在第一阶段使用一个庞大的语言模型进行预训练;然后,在第二阶段,使用特定下游任务的数据集做模型微调。后面这张图展示了如何修改 GPT 预训练模型,以便其兼容各种下游的 NLP 任务。
BERT:预训练模型一鸣惊人
BERT 系列从一开始就采用了 Encoder Only 的 Transformer 架构
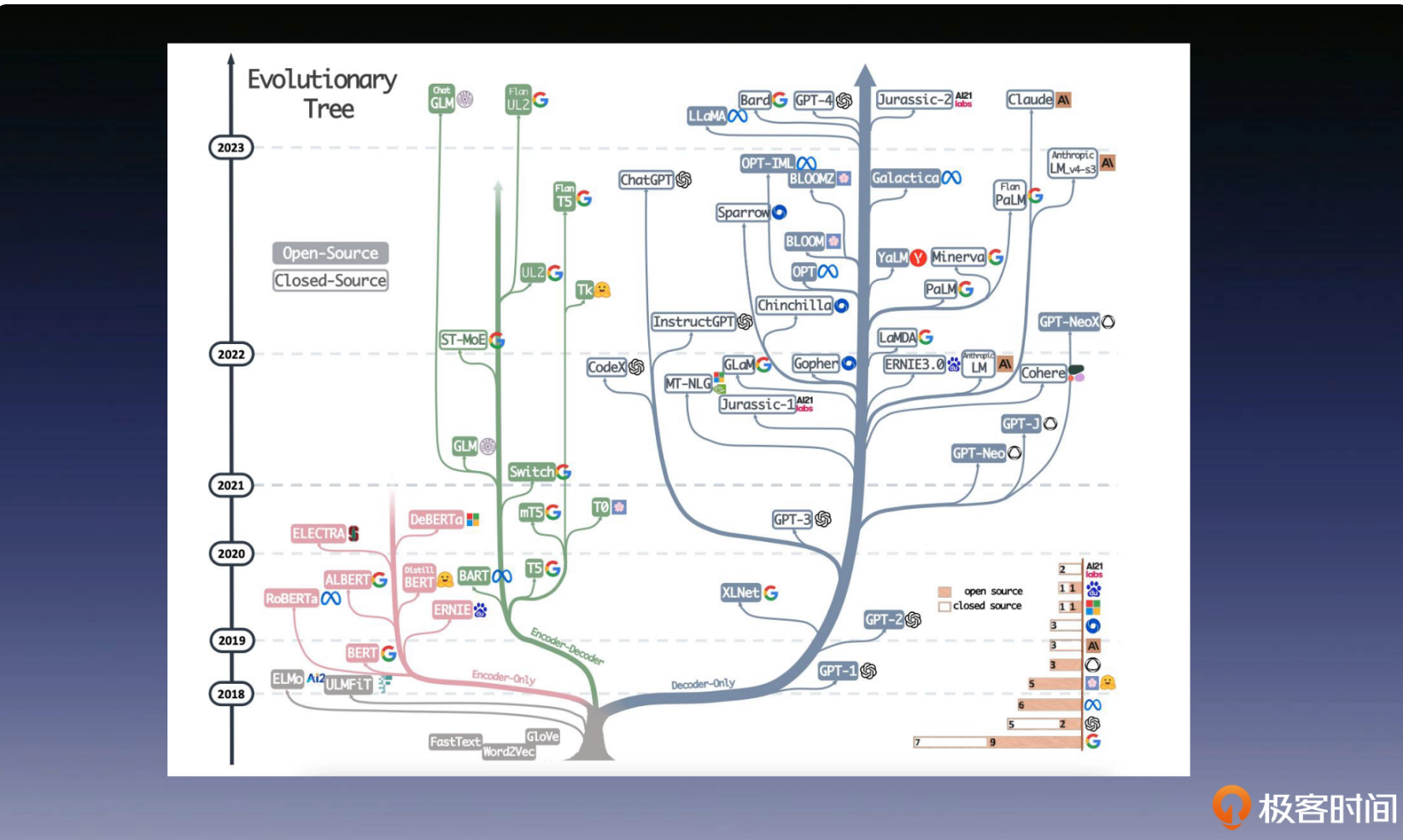
大模型发展过程
Transformer介绍
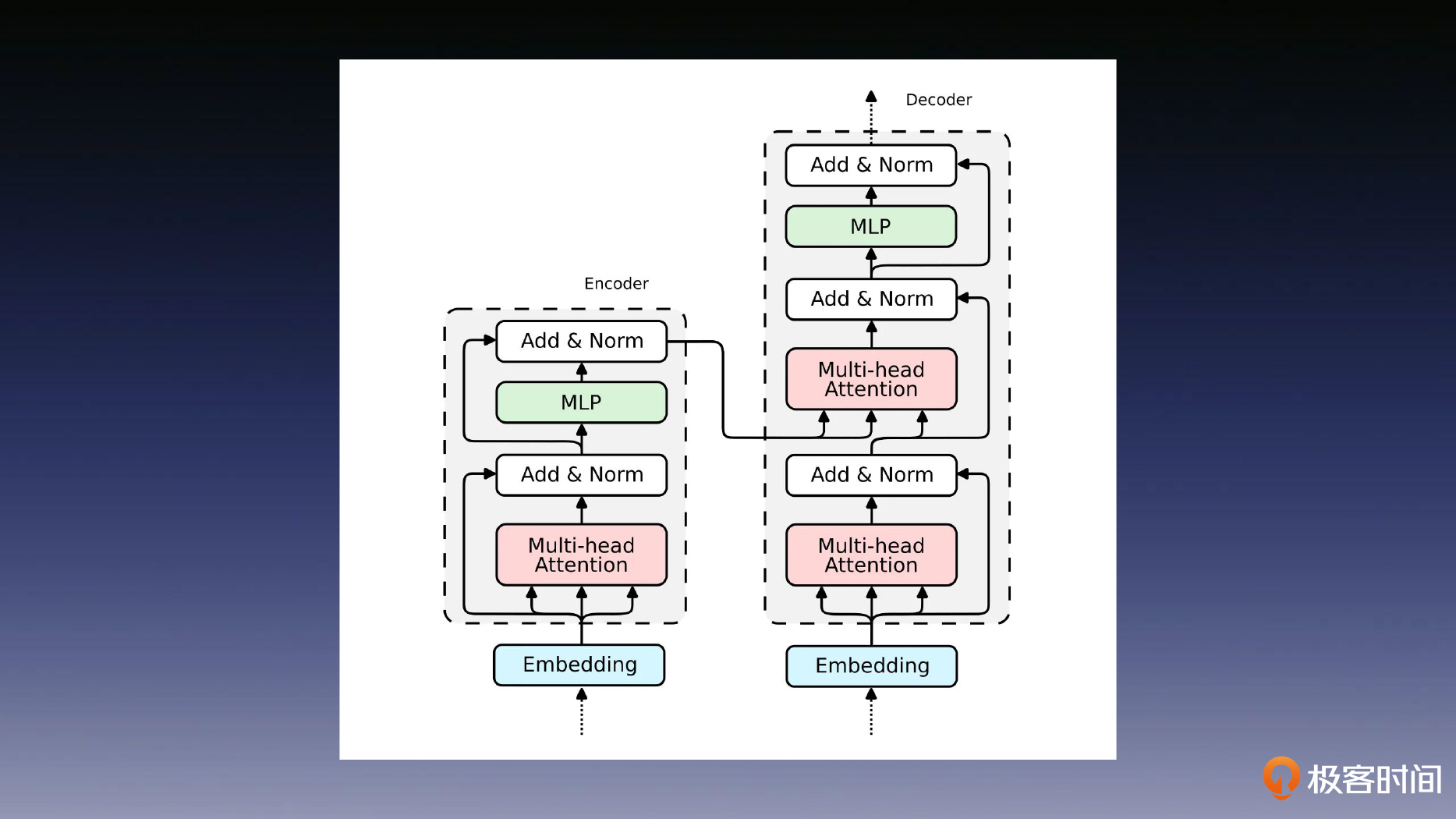
自注意力机制
位置编码
多头注意力
残差连接
全连接层(MLP)
GPT发展历程
GPT1
微调(Finetune)
GPT-1 的微调方法是,使用预训练好的模型来初始化权重,同时在 GPT-1 的预训练模型后面增加一个线性层,就像我们在第 13 节课的时候预训练 CV 领域 PTM 那样。最后只要根据下游具体 NLP 任务的训练数据来微调更新模型的参数就可以了。
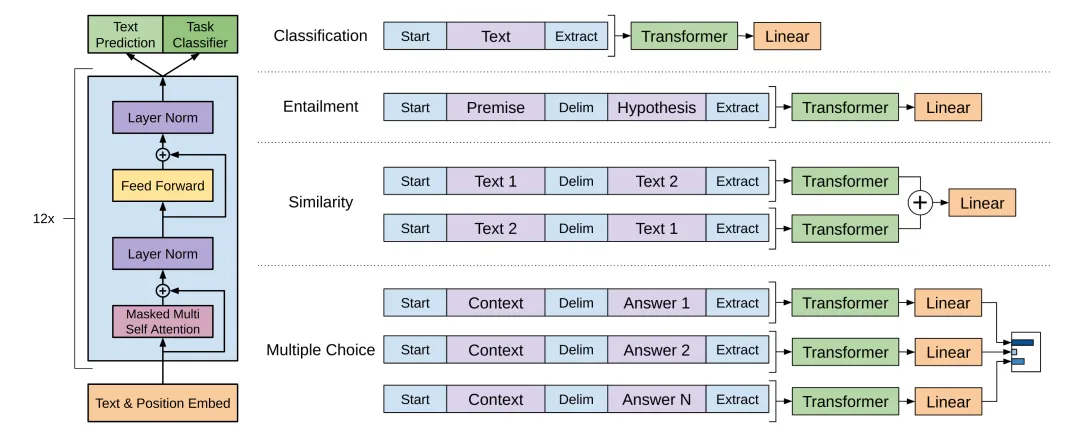
GPT2
zero-shot
将下游任务数据集也作为GPT-2模型的训练数据 + Prompt,在经过这些步骤以后,GPT-2 的预训练模型在未经过任何微调的情况下,就能战胜许多下游任务的最佳结果。
GPT3
few-shot
允许在prompt中输入某些数据作为例子,让模型在提示语中学习新样本的模式和规律,这种方法的学名叫做 in-context learning。
WebGPT
WebGPT 提供了一整套的方法,使 LLM 能够自主地搜索内容、浏览网页并获取知识,以使语言模型更准确地回答问题,并为回答的内容提供引用来源,从而提高回答的可信度。
WebGPT 提供了一整套的方法,使 LLM 能够自主地搜索内容、浏览网页并获取知识,以使语言模型更准确地回答问题,并为回答的内容提供引用来源,从而提高回答的可信度。
ChatGPT
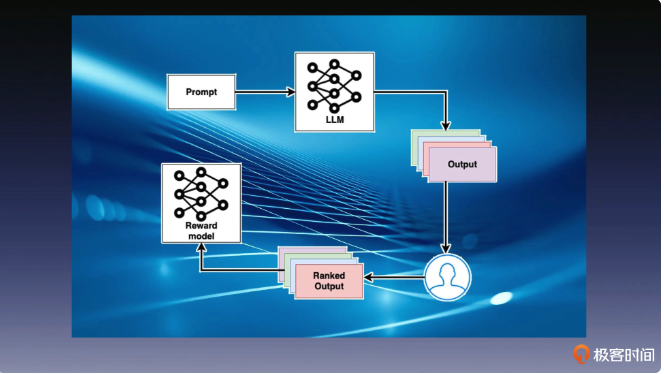
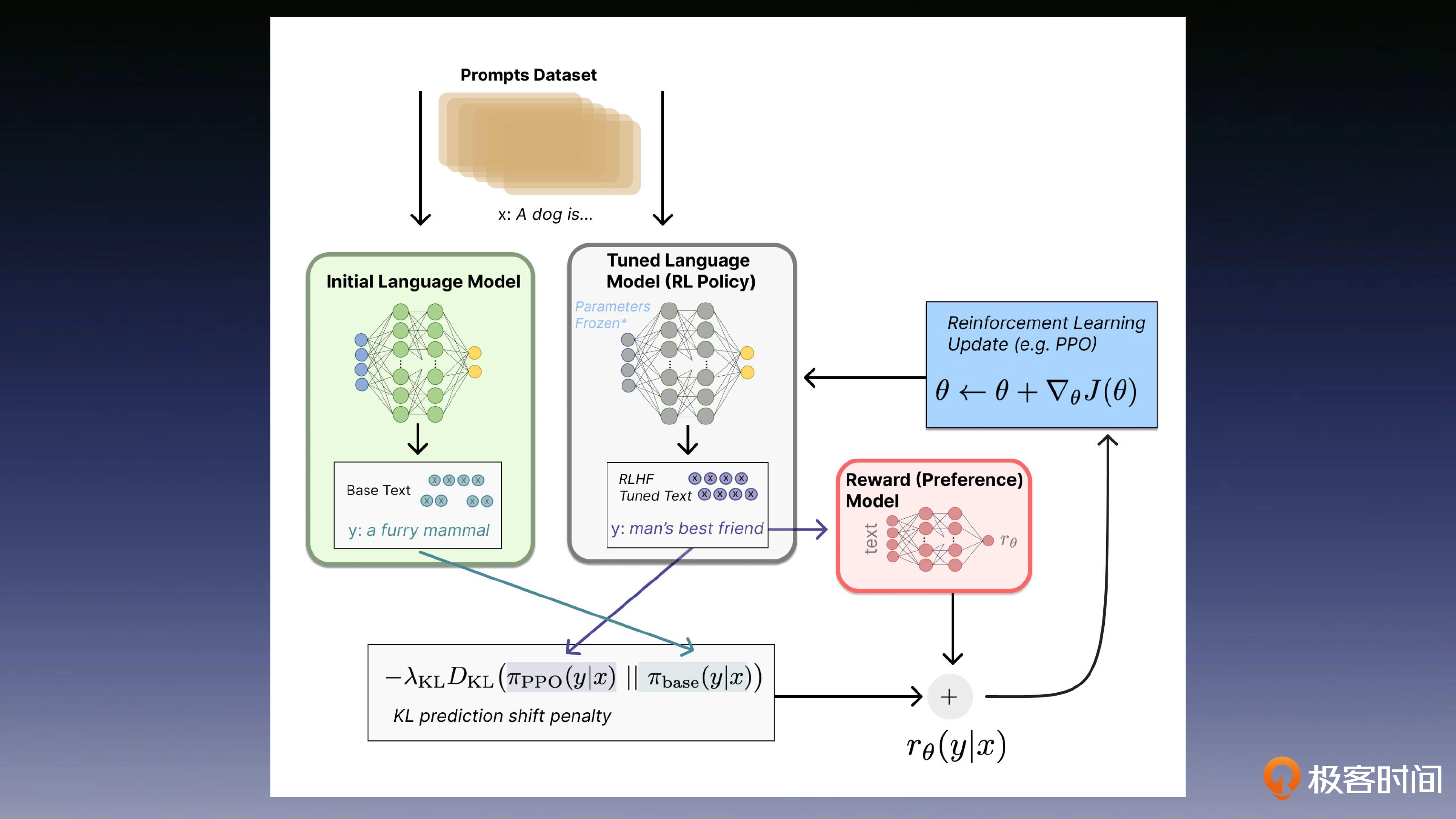
训练过程
RLHF 是一种结合了强化学习和人类反馈的方法,用于训练模型以生成更符合人类期望的回答或行为。它通常用于训练对话系统或推荐系统,其中人类的反馈用来指导模型的学习过程,以改善回答的质量。
SFT,即监督微调,是一种在预训练模型的基础上,使用标注数据集来进一步训练模型的方法。这种方法通常用于调整模型以适应特定的任务或领域。
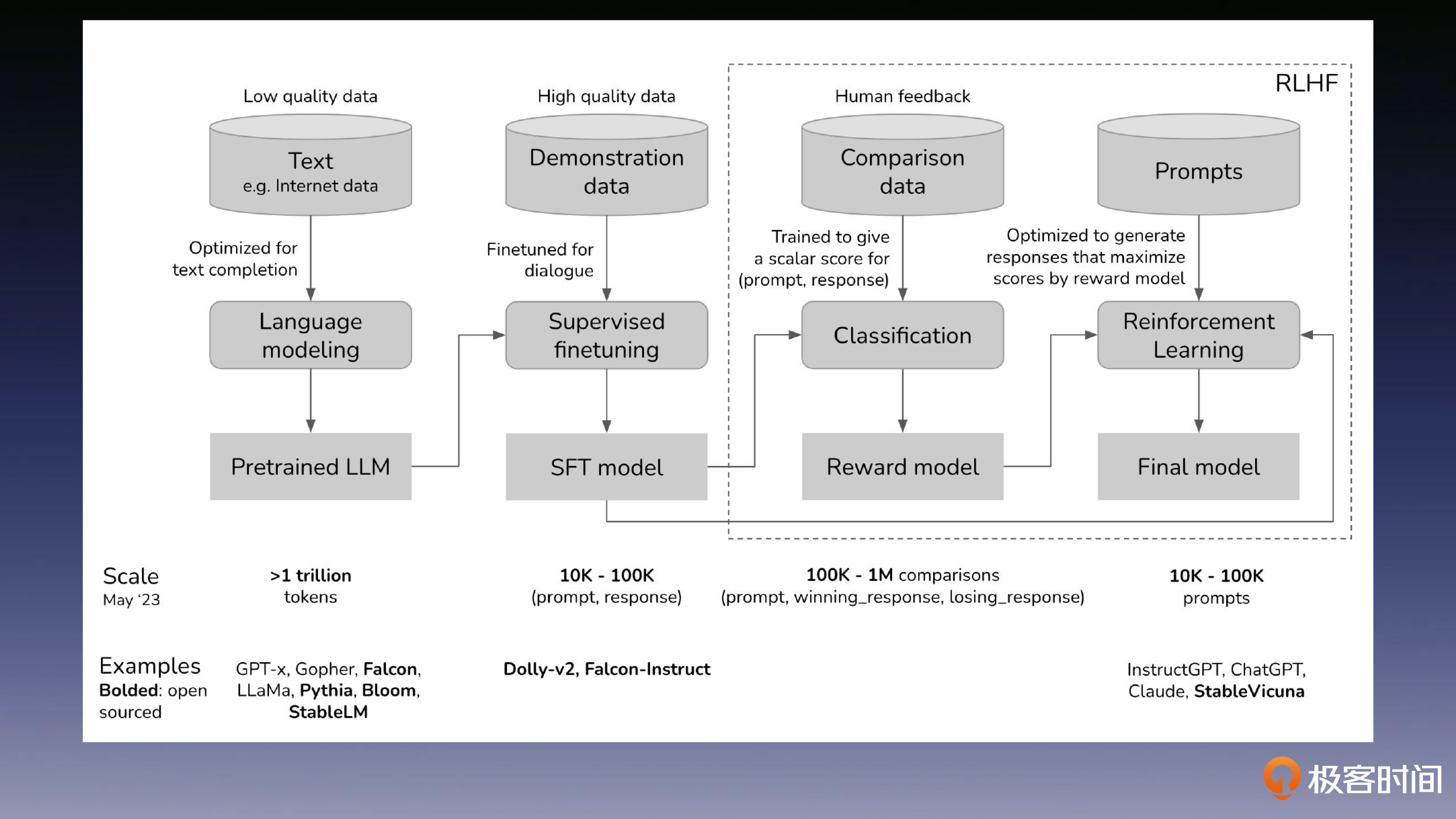
首先,我们通过比较容易获得的公开无标签数据,来训练一个大语言模型,比如 GPT-3,这是我们在前几节课就已经学过的知识。然后,通过人工编写的问答对,来生成高质量的监督对话数据,来优化大语言模型的对话能力。
在得到了这个优化后模型之后,标注者便在给定问题上可以基于模型生成的答案,对回答进行排序,并用排序数据训练一个奖励模型对回答的结果排序打分,用来评估回答的质量。
强化学习
大模型性能影响因素
参数规模的影响
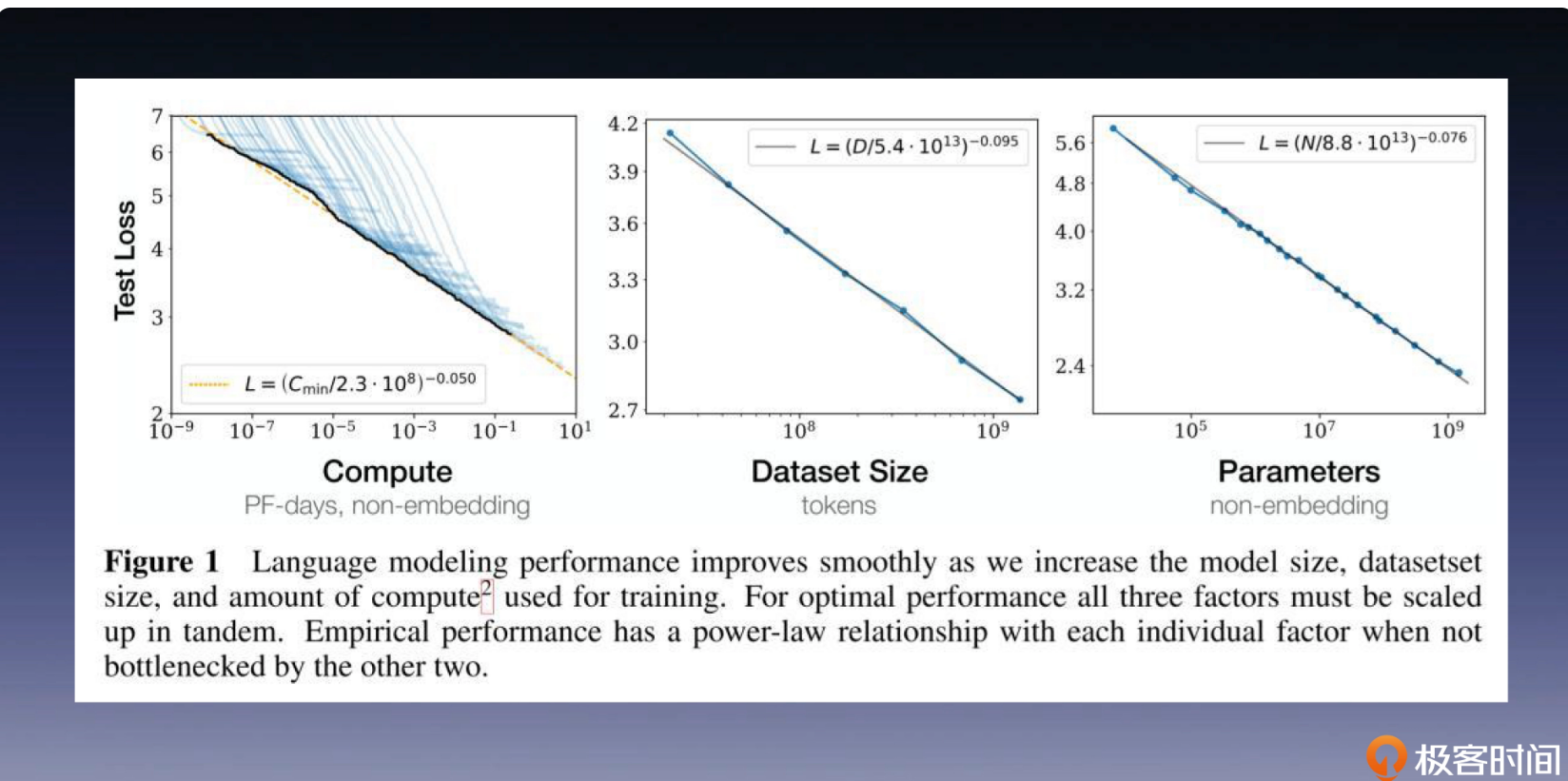
Scaling Laws
在论文 Scaling Laws for Neural Language Models 中,OpenAI 提出了“伸缩法则”(scaling law)。如下图所示,大语言模型性能分别受训练时长、模型参数量和数据集大小的影响,而大模型性能与每个单独的因素都有正相关性,体现为 Test Loss 的降低,这意味着模型性能的提升。
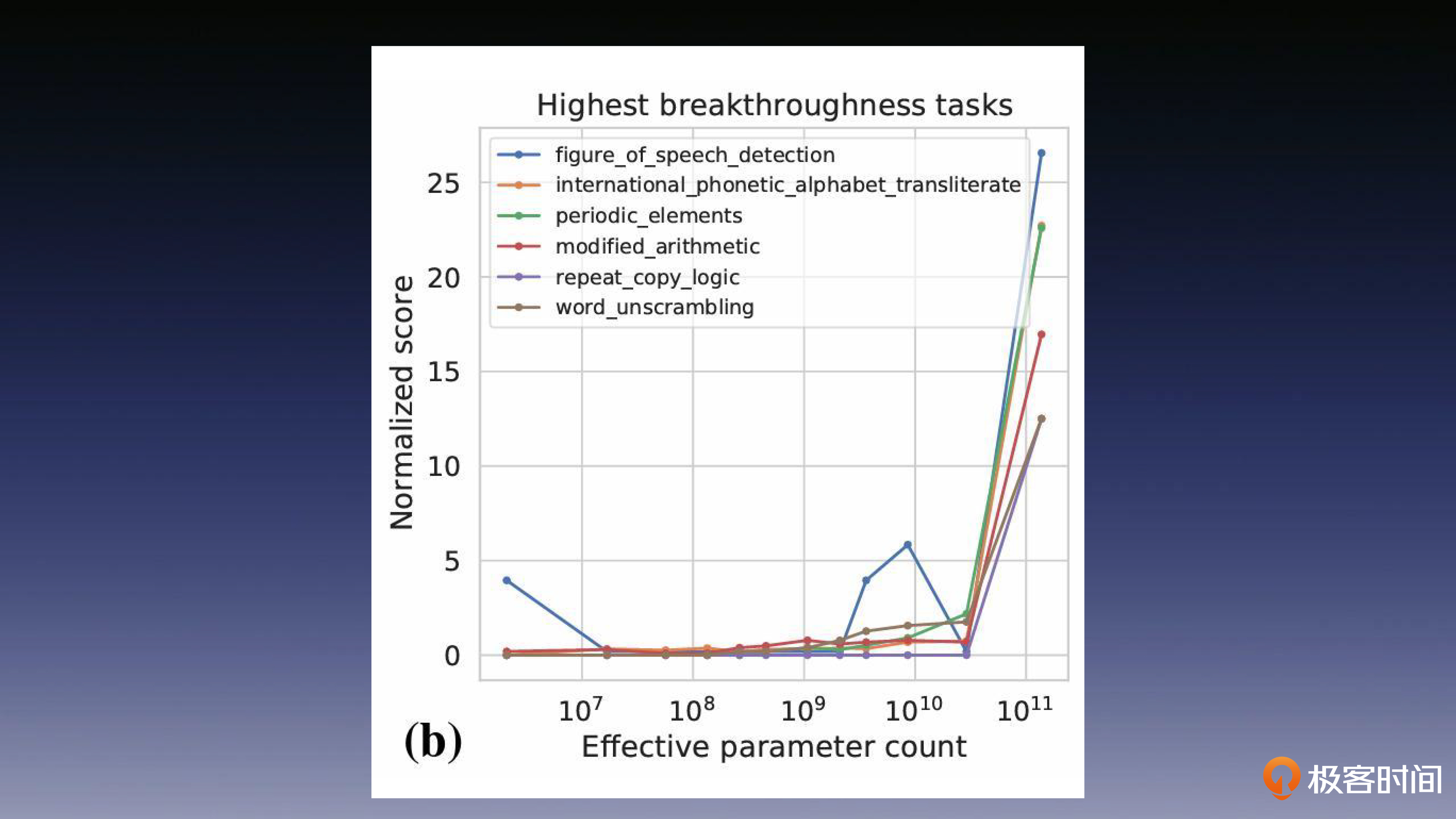
涌现能力
涌现能力的典型特征就是,在小规模的时候,模型基本上没有任务解决能力,而在模型规模达到一定的临界值之后,模型能力就会迅速提高。这种现象,在处理多步骤复杂任务的时候尤其明显。这种新能力的涌现,让模型在处理复杂任务的时候,具备了更高的性能和解决能力。
可以在下面这张图中看出,各项任务的性能都在参数规模达到了 10^10 时发生了骤变,攀升到了一个很高的数值。这便是涌现在模型参数量和性能的相关性数据上所呈现的特征。
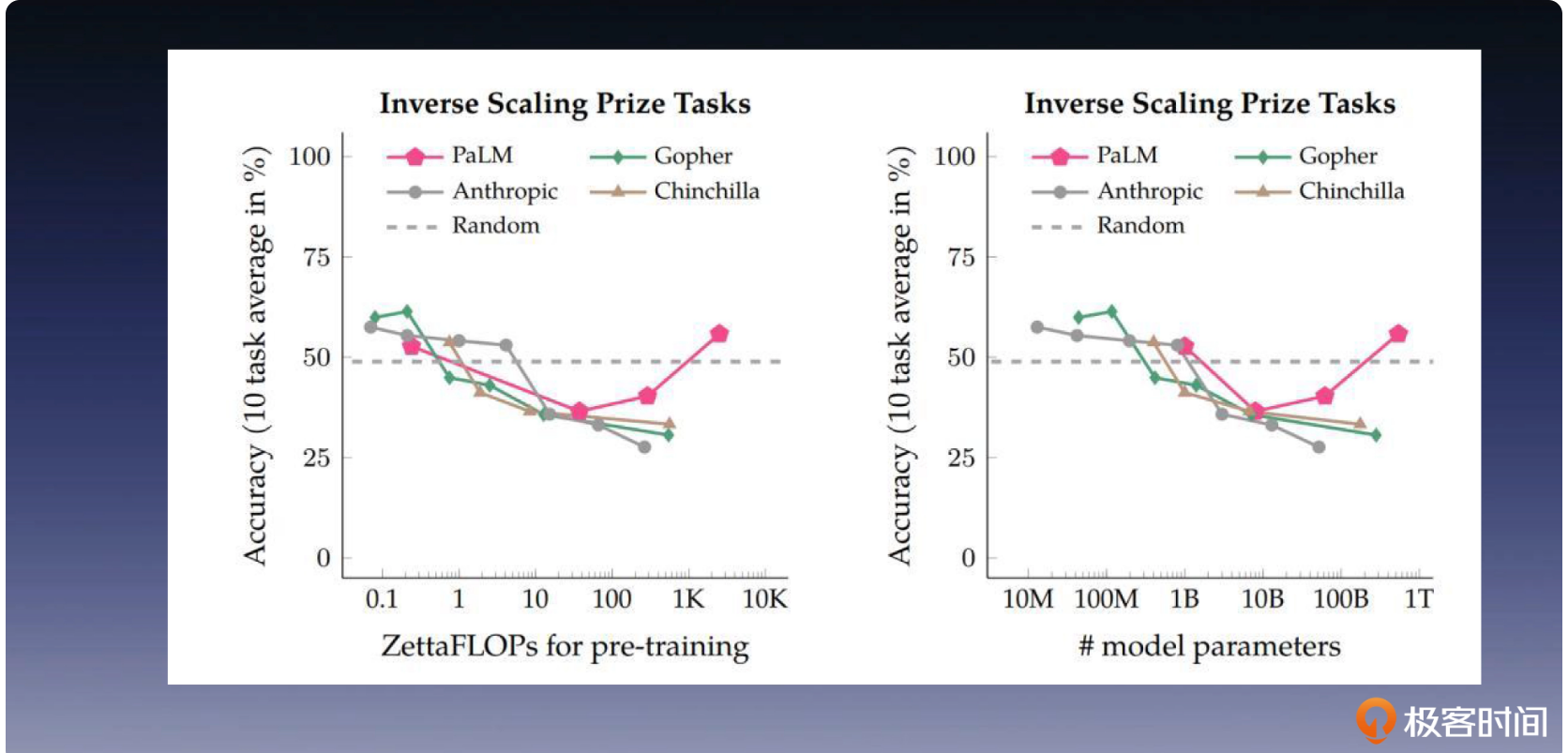
U 形曲线效应
Google 在 Inverse scaling can become U-shaped 提出了 U 形曲线的任务,研究人员们开始对下图中这种奇怪的现象进行研究。
研究人员经过多组类似的观察后归纳总结,将这种随着模型规模的增长,刚开始模型效果下降,但当模型规模足够大时,效果反而会提升的现象称为“U 形曲线效应”。因为如果把参数规模作为横坐标,把模型性能作为纵坐标,那么就会出现一个 U 型曲线。
涌现能力
In Context Learning (ICL):大语言模型从少量的示例中学习,而无需微调参数的能力。
ICL 允许大语言模型从上下文示例中学习。在 ICL 中,我们只需给模型提供几个示例,它就可以在许多下游任务中表现出色,甚至超过了经过监微调的小型模型。
思维链 (CoT):大语言模型能够理解和执行复杂的推理过程。
CoT 本质上也是一种 Few-Shot 的提示方法,它允许用户为复杂的推理问题提供详细的推理过程,并将其提供给大语言模型。这使得模型能在执行复杂的推理任务(包括数学问题和符号推理等)过程当中表现出色。
架构实战篇
Prompt engineering
目标是提高LLM输出质量
Selecting
LLM外部记忆示例
KATE(就近法则)
跟提问内容语义(高维空间距离)更相近的示例,能够帮助大语言模型得到更好的结果。

EPR(因材施教)
第二类方法是以论文 “Learning To Retrieve Prompts for In-Context Learning” 为代表的监督学习方法。其实监督学习的方法更符合我们对提示语工程的期望,因为它可以让大语言模型自身来判断示例样本的好坏。
这个方法名叫 EPR,它借鉴了 Learning to Rank 中 Pairwise 的对比学习方法。相信你还记得我们在 GPT 系列课程里面学过这类方法。这类方法只需要给出优秀示例和劣质示例的对比关系,就可以训练出一个打分模型,用来评价示例样本的质量。
所以这里唯一的问题,就是如何定义提示语中示例样本的“质量”高低。文章中提出了一种方法,这种方法可以利用大语言模型本身来为打分模型提供输入。
首先,我们需要从示例样本集中选择一个示例样本。然后,基于这个示例样本和训练集中的题目进行组合作为提示语,通过大语言模型为这个提示语生成的输出结果打分。接着,将平均得分高的示例样本选为正样本,平均得分低的示例样本选为负样本。最后,基于正负样本进行对比学习训练,得到一个对示例样本打分的模型。
这样,我们就可以在多个示例样本中,根据分数排序来优选样本。
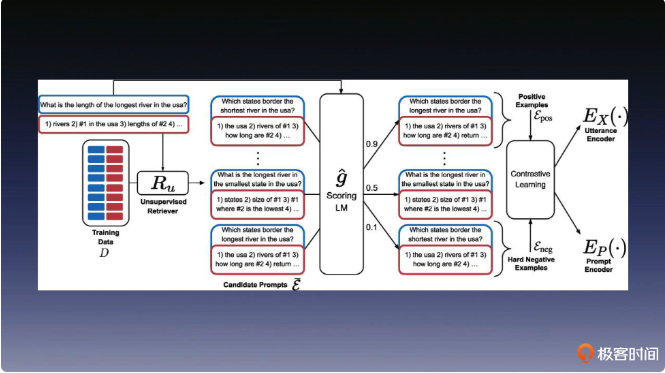
ordering
基于熵的排序策略
reference from article:
我们可以根据 ACL 22 的这篇杰出论文 “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity” 提出的方法,使用熵来决定示例的排序。简单来说,我们可以对一个示例样本的序列,计算它概率的熵值。熵值越大,就表示该序列的质量越高。 研究人员发现,使用他们提出的全局熵(Global Entropy: GlobalE)和局部熵(Local Entropy: LocalE),跟随机排序的方法相比,可以分别平均提高 13% 和 9.6% 的性能。这种方法相较于“就近示例”方法更加复杂,但在理论上具有更强的可解释性,更适用于对稳定性要求较高的工业级系统。
prompt模板
Automatic Prompt Engineer(自问自答)
APE 方法的主要思想是,根据用户要完成任务的具体内容,自动生成一个更适合大语言模型的提示词模板,主要包含以下几个步骤: 首先,你需要提供示例,包括任务描述和任务示例,一般来说任务示例是一组输入输出对。大语言模型会根据提供的示例,生成一些备选的“提示语模板”。 之后,你需要使用大语言模型作为打分模型,给每个提示语模板打分,选出分数最高的提示语模板作为这个任务的模板。 最后,是改进模板,这里要使用迭代蒙特卡洛搜索的方法,针对刚刚生成好的提示语模板,生成语义相似的指令变体,改进最佳模板。
Prompt方式
Self-Consistency Sampling(一题多解)
大语言模型通常会在解码器的每个时间步,选择概率最高的词汇作为输出。这种策略在只有一次回答机会的情况下是非常有效的。但是,如果我们希望模型在回答某个问题时,充分考虑他所学过的所有知识,这种方法就不太适用了。为了优化这种方法,Google 提出了自一致采样(Self-Consistency Sampling)的方法。
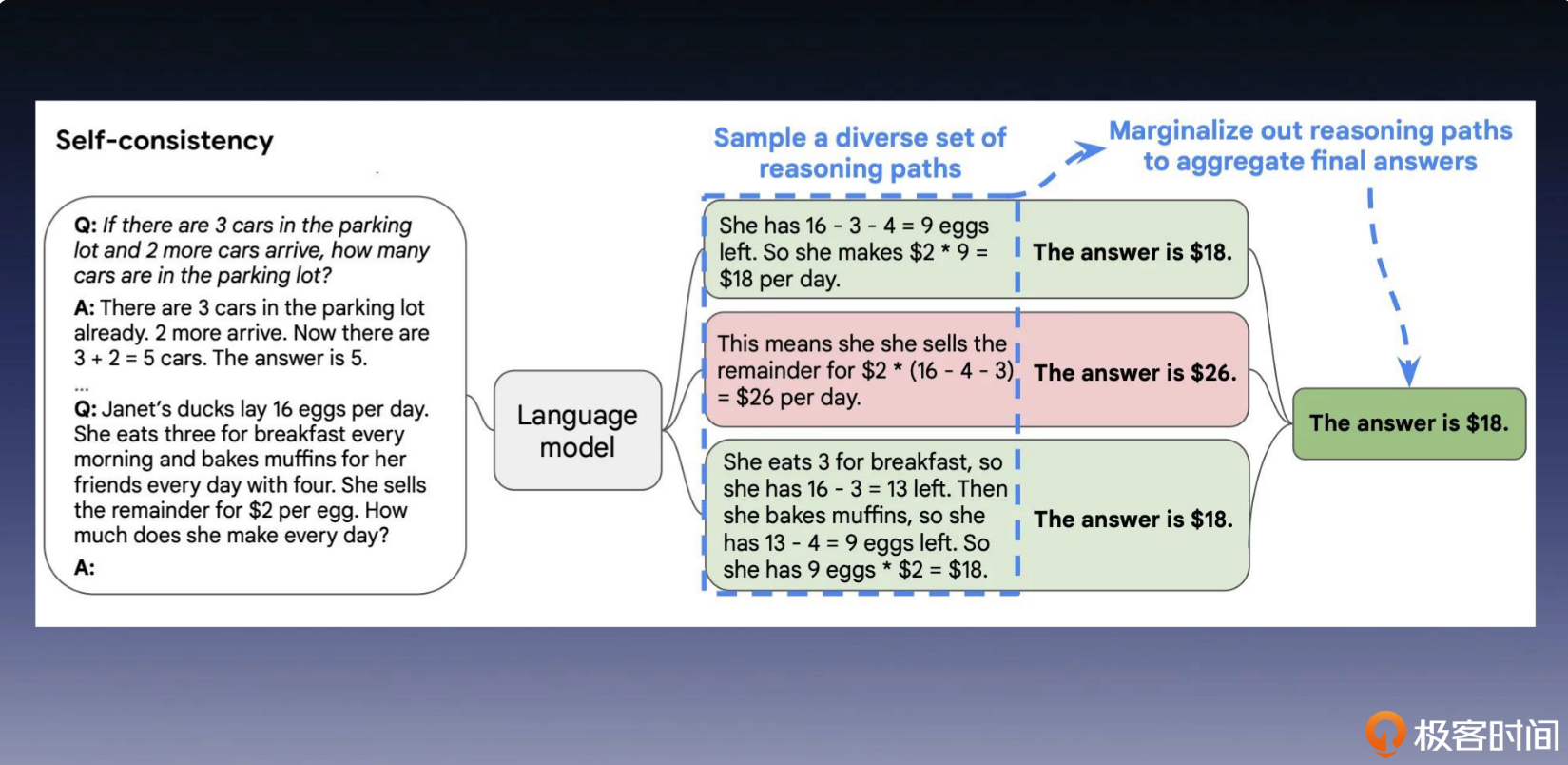
自一致采样方法包括以下三个步骤。
使用思维链(CoT)提示语言模型,分步骤地解决给定问题。
从语言模型的解码器中随机采样,生成一组不同的推理路径。
在众多最终答案中,选择最一致的答案,作为最终的推理结果。 这个思想,和我们在数学考试中,通过“一题多解”来验证答案的正确性,其实是一样的。它通过让 LLM 从多个不同的推理路径中生成答案,并根据答案的自洽性来选择最优的结果。
挖掘LLM深层记忆
帮助模型,去唤醒一些它的“深度记忆”,让它知道该用这些学过的知识来,回答问题。 需要注意的是,这里的“记忆”是指模型在训练过程中获得的记忆,而不是提示词提供的外部记忆。这个方法的具体步骤是先让大语言模型生成一些,跟问题内容相关的“知识”,然后再把这个知识做为输入示例样本反哺给大语言模型,辅助回答目标问题。
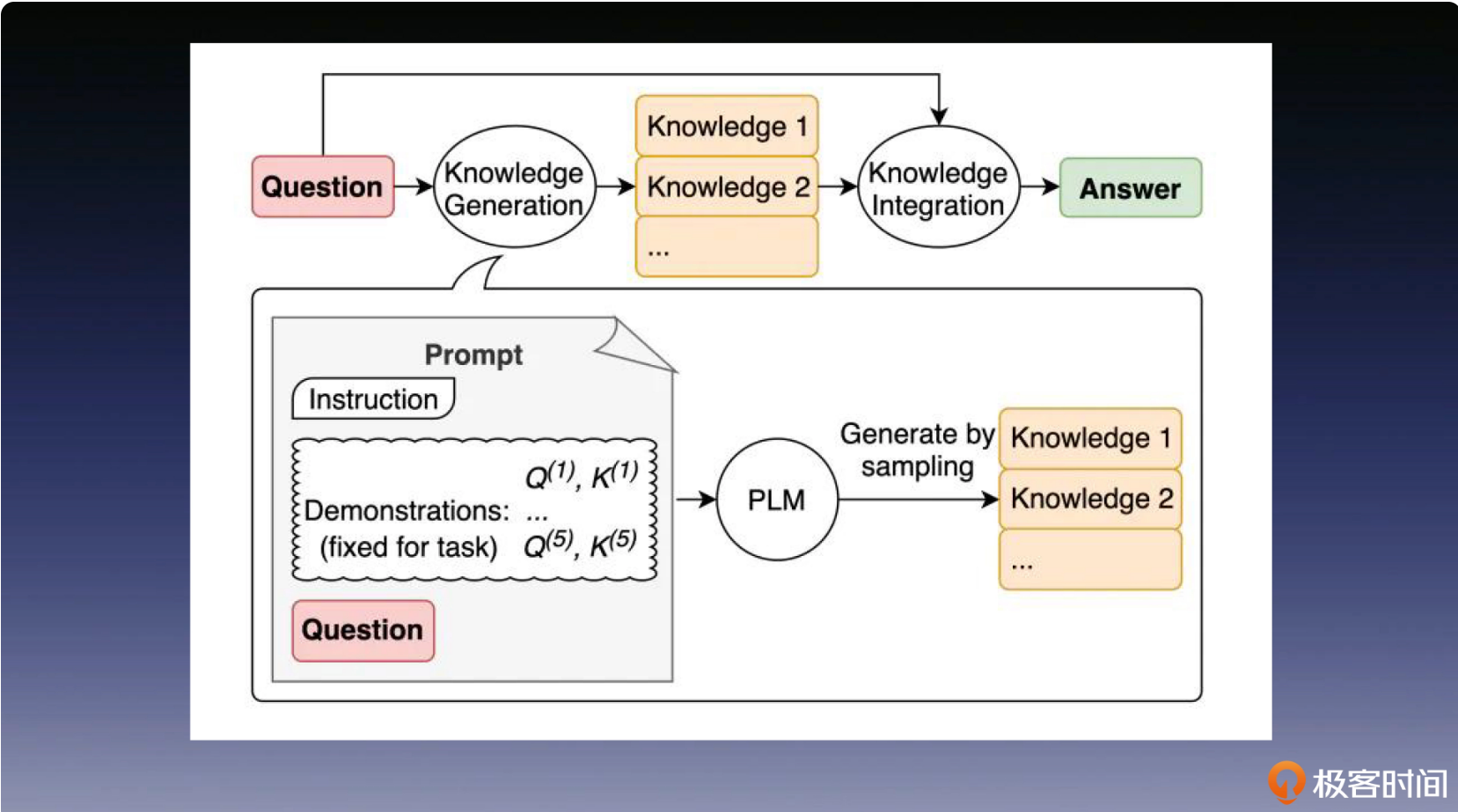
让LLM主动寻求外部记忆

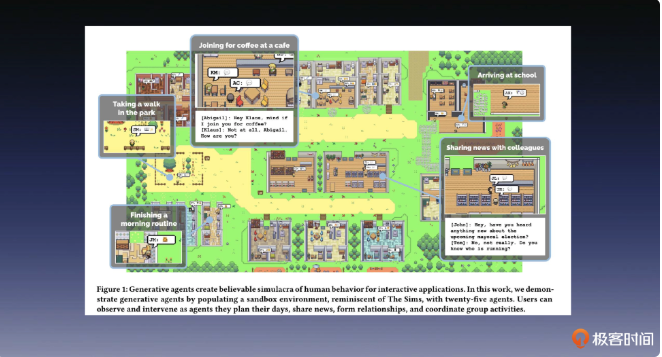
斯坦福智能小镇讲解
斯坦福大学做了个游戏,在游戏中,有多为AI角色,他们被内置了记忆种子,AI与AI之间会有各种交互,类似于《西部世界》。
在这场社会实验中,研究人员会观测自己设计的“生命”,观察它们是否拥有稳定的“人格”,是否有能力应对社会上的各种问题。
下面是一个记忆的例子:
记忆能力
这里第一个关键的问题是如何让你创造的生命拥有“记忆”。 大语言模型作为智能体的最大的问题在于它本身是一个无状态的“生物”,也就是说它记不得历史上发生了什么。一切关于它的历史都需要一个外部记忆来辅助记录,这样智能体之间对话时,才不会彼此玩“失忆”。 当然,这个外部记忆的实现是很有讲究的。比如,在问智能体 Isabella “你这些天都在热衷于哪件事?”时,最直接的实现方法是把它这些天的种种活动都放入到大语言模型的提示语中,让模型作答。 不过,这时我们大概率会得到一个没什么信息量的答复,因为它根本不知道哪些发生过的事情才是重点。 为了解决这个问题,论文中提出了一种叫做记忆流的方案。记忆流保存了智能体的完整经历,是一个记忆对象的列表,每个对象包含自然语言的描述、创建的时间戳以及最近访问的时间戳。记忆流中最基本的元素是记忆事件,这是每个智能体直接感知到的事件,你可以理解成这是智能体的生活日记。 记忆流的检索方法将时近性、重要性和相关性三个因素作为记忆对象的得分,并加权求和作为最终得分。 我把这三个因素的意思稍微给你解释一下。 时近性:为最近访问的记忆对象分配一个更高的分,这和人类的记忆习惯一样,能让刚才或今早发生的事情留在智能体的意识内。 重要性:为智能体觉得重要的记忆对象赋予更高的得分,将关键记忆和普通记忆区分开。 相关性:为与当前情况紧密相关的记忆对象分配一个更高的得分,具体方案可以是用当前情况和记忆事件的高维空间距离来描述其相似性。 下图里描述的是记忆流的存储内容和检索方法。实现代码

反思能力
通过反思可以不断地度对已有地记忆做总结,并提炼出重点,继续放在记忆list中,为之后Agent的各种action做参考。
规划能力
通过前面的记忆以及反思操作,agent可以为下一步行动做规划。
外部记忆检索
这里介绍了三种方式:
倒排索引
使用ElasticSearch来做倒排索引。
嵌入表征
使用代表语义信息的高维向量来搜索相似信息。著名的算法有KNN(找到与查询向量最相似的 K 个向量)以及牺牲少量精确度提高速度的算法ANN(近似最近邻算法)。
常用的检索算法包括后面这三类。
空间划分法:将数据空间划分为多个子空间,然后在子空间内进行检索。常见的空间划分方法有 KD-Tree、聚类检索等。
空间编码和转换法:将高维数据映射到低维空间进行检索。常见的空间编码和转换方法有 p-Stable LSH、PQ 等。
邻居图法:构建数据之间的邻居关系,然后在邻居图上进行检索。常见的邻居图法有 HNSW、SPTAG、ONNG 等。
问题:
大规模索引的精度和效率问题。随着数据量的不断增加,在亿级、甚至十亿级时,向量索引的构建和检索成本也会随之增加,这可能会影响向量检索的性能和准确性。
另一个挑战是高维数据的处理问题。随着维度的增加,向量检索的计算复杂度也会呈指数级增长,这可能会导致查询效率下降、存储成本升高。
模型训练
数据从何而来
Self-Instruct
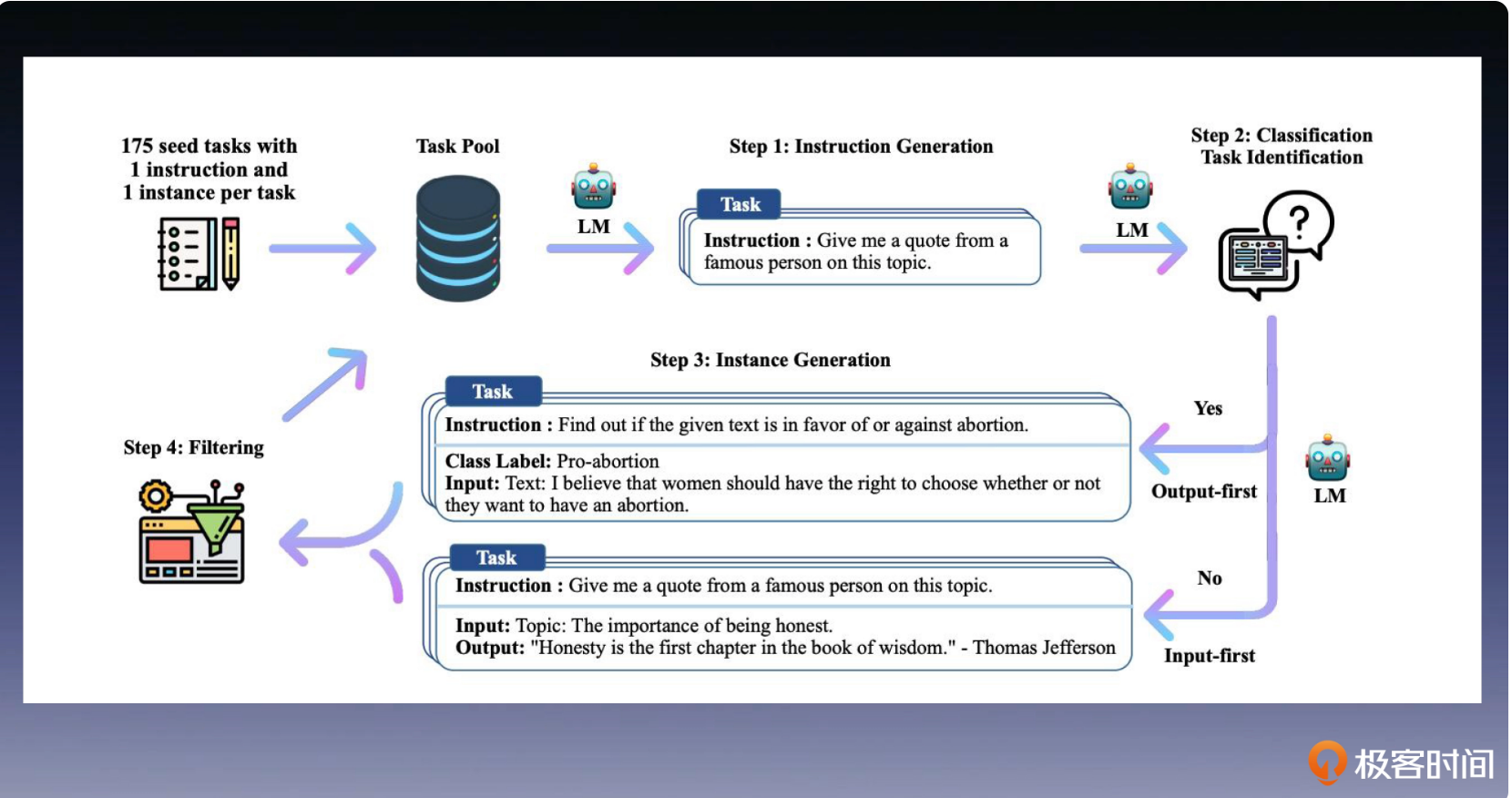
Self-Instruct 从一组初始示例样本开始,以 LLM 的自我引导方式生成新的指令和示例。
第一步,准备种子数据。我们需要创建一个种子数据集,这一步,是唯一需要标注人员的参与环节。我们需要为每个任务准备一条指令和一个示例,同时在这里我们需要明确这些指令是用于分类,还是其他的用途。以下提供了指令的示例。
示例 #1 通过构造指令,让大语言模型给出早餐建议的示例样例。
{
"id": "seed_task_0",
"name": "breakfast_suggestion",
"instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?",
"instances": [{"input": "", "output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."}],
"is_classification": false
}示例 #2 通过构造指令,让大语言模型给出两个词之间关系的示例样例。
{
"id": "seed_task_1",
"name": "antonym_relation",
"instruction": "What is the relation between the given pairs?",
"instances": [{"input": "Night : Day :: Right : Left", "output": "The relation between the given pairs is that they are opposites."}], "is_classification": false
}第二步,生成提示指令,也就是利用大型预训练语言模型(LLM)来生成新的指令。
就像之前提到的,每个任务都包含一条指令和一个示例。在每一轮的数据生成中,我们都从这个任务池里面,随机选择 8 个任务指令作为上下文示例。这 8 个指令中包含了 6 个人工编写的样本和 2 个来自前一轮模型生成的样本,这可以有效地提高生成指令的多样性。
以下是一些生成新指令的示例提示(生成提示指令,用于后续示例样本的生成)。
Come up with a series of tasks:
Task1: {instruction for existing task 1}
Task2: {instruction for existing task 2}
...
Task8: {instruction for existing task 8}
Task9:第三步,判断任务类型。我们要判断生成的指令是否属于分类任务。为什么需要这一步呢?因为这两类任务后续的处理方法和生成步骤是不同的,要区分处理。
Can the following task be regarded as a classification task with finite output labels?
Task: Given my personality and the job, tell me if I would be suitable.
Is it classification? Yes
...
Task: Given a set of numbers, find all possible subsets that sum to a given number.
Is it classification? No
Task: {instruction for the target task}接下来是生成示例样本的步骤。完成上一步后,我们继续为这两类任务,采用不同的生成方法。
在非分类任务上,我们使用输入优先的方法,这是一种直观和自然的方法,我们首先根据指令生成输入字段,然后生成输出。
以下是非分类任务的示例提示。
task doesn’t require additional input, you can generate the output directly.Task: Which exercises are best for reducing belly fat at home?
Output:
- Lying Leg Raises
- Leg In And Out
- Plank
- Side Plank
- Sit-upsTask: Sort the given list ascendingly.
Example 1
List: [10, 92, 2, 5, -4, 92, 5, 101]
Output: [-4, 2, 5, 5, 10, 92, 92, 101]
Example 2
Input 2 - List: [9.99, 10, -5, -1000, 5e6, 999]
Output: [-1000, -5, 9.99, 10, 999, 5e6]但这种方法不适用于分类任务。对于分类任务,更适合使用输出优先方法。这种方法会首先生成分类标签,然后根据分类标签生成输入。以下是分类任务的示例提示。
Given the classification task definition and the class labels, generate an input that corresponds to each of the class labels. If the task doesn’t require input, just generate the correct class label.Task: Classify the sentiment of the sentence into positive, negative, or mixed.
Class label: mixed
Sentence: I enjoy the flavor of the restaurant but their service is too slow.
Class label: Positive
Sentence: I had a great day today. The weather was beautiful and I spent time with friends.
Class label: Negative
Sentence: I was really disappointed by the latest superhero movie. I would not recommend it.第四步,我们会过滤生成内容,完成数据过滤和后处理这些任务。为了确保生成数据的质量,只有当新生成的指令与现有指令的 ROUGE-L 重叠小于 0.7 时,才会将其添加到任务池中,以确保指令的这质量和多样性。同时,这一步还会排除包含“图片”和“图表”这些关键词的指令,并过滤掉完全相同的,或具有相同输入、但输出不同的示例。
最后,在获得足够的指令和示例后,算法就会停止生成任务。
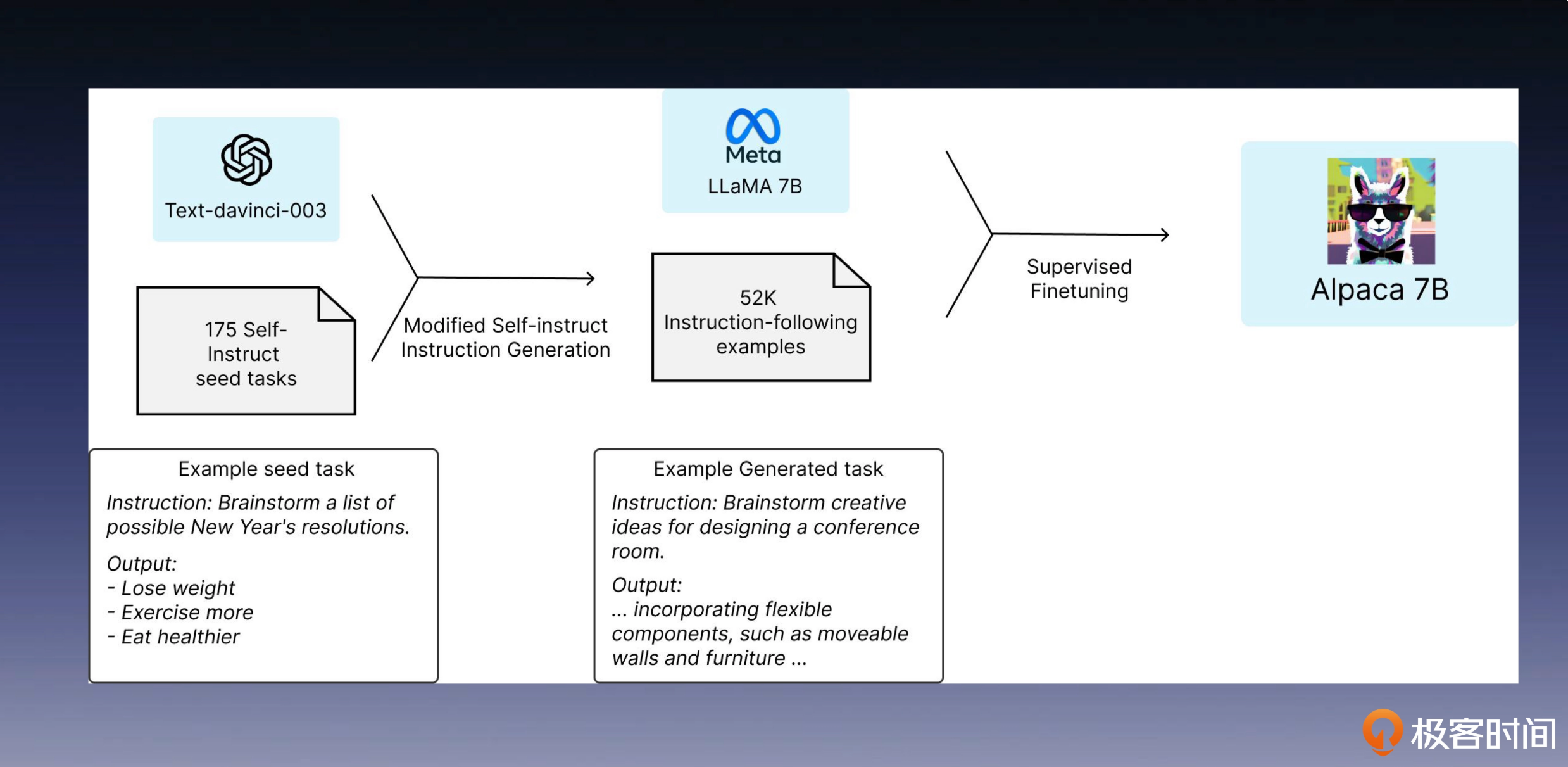
Alpaca
Alpaca 是 LLaMA-7B 的微调版本,它采用了 Self-Instruct 方式生成的数据进行了指令微调。
下面是它使用的prompt:
You are asked to come up with a set of 20 diverse task instructions. These task instructions will be given to a GPT model and we will evaluate the GPT model for completing the instructions.
Here are the requirements:
1. Try not to repeat the verb for each instruction to maximize diversity.
2. The language used for the instruction also should be diverse. For example, you should combine questions with imperative instrucitons.
3. The type of instructions should be diverse. The list should include diverse types of tasks like open-ended generation, classification, editing, etc.
2. A GPT language model should be able to complete the instruction. For example, do not ask the assistant to create any visual or audio output. For another example, do not ask the assistant to wake you up at 5pm or set a reminder because it cannot perform any action.
3. The instructions should be in English.
4. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a question is permitted.
5. You should generate an appropriate input to the instruction. The input field should contain a specific example provided for the instruction. It should involve realistic data and should not contain simple placeholders. The input should provide substantial content to make the instruction challenging but should ideally not exceed 100 words.
6. Not all instructions require input. For example, when a instruction asks about some general information, "what is the highest peak in the world", it is not necssary to provide a specific context. In this case, we simply put "<noinput>" in the input field.
7. The output should be an appropriate response to the instruction and the input. Make sure the output is less than 100 words.
List of 20 tasks:
###
1. Instruction: Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?
1. Inputs: <noinput>
1. Output: Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup water, totalling about 550 calories. The 4 strips of bacon contains about 200 calories.
###
2. Instruction: Generate an appropriate subjective title for the following email:
2. Inputs: Hi [person name],I'm writing to ask you if you are happy to be a panelist of our workshop on multimodality at CVPR. The workshop will be held on June 20, 2023. \n\nBest,\n[my name]
2. Output: Invitition to be a panelist for CVPR 2023 workshop on Multimodality
###
3. Instruction: 总结
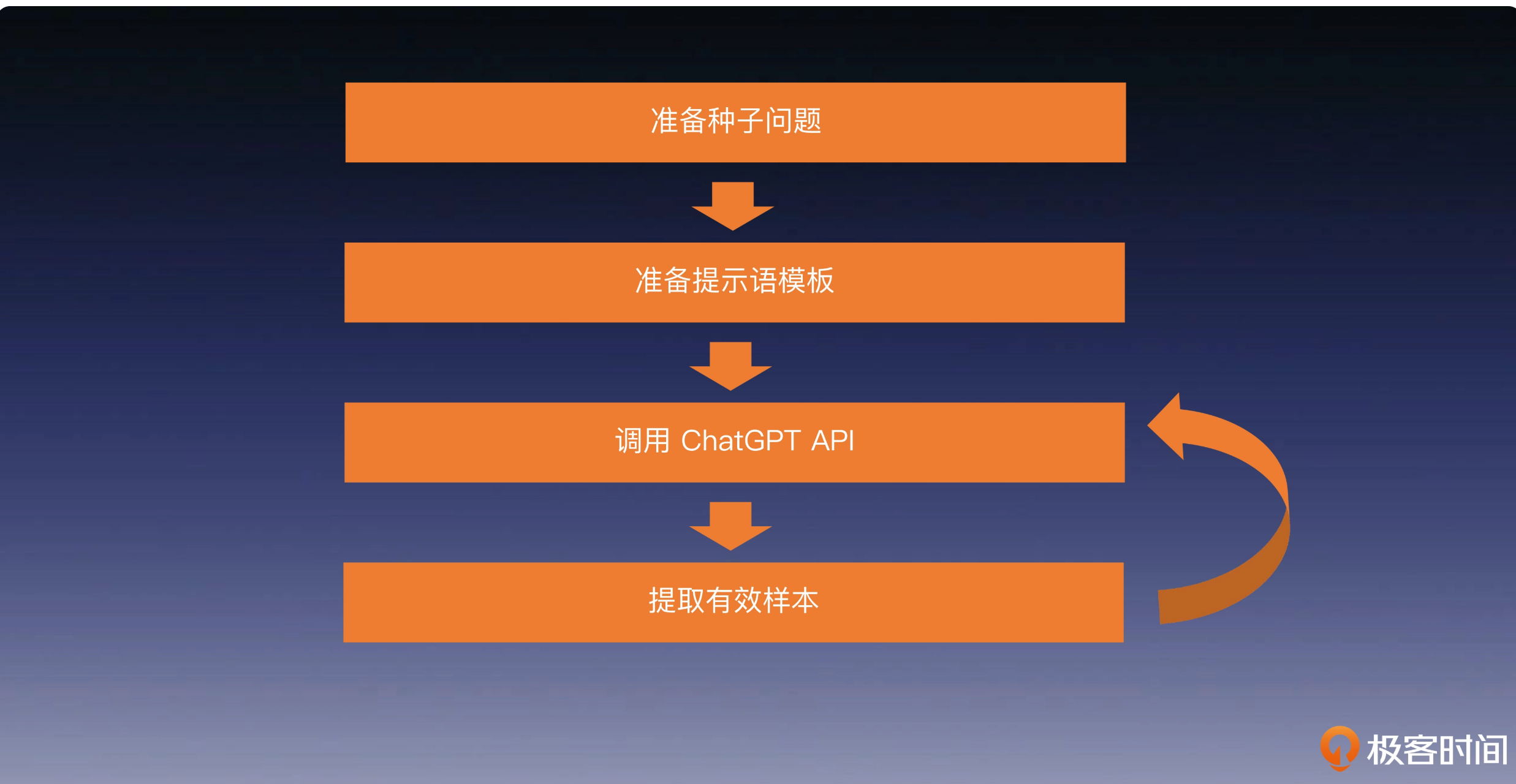
使用一组人工编写的指令(本例中为 175 条)来初始化任务池,并随机选择一些指令。
利用预训练的大型语言模型(如 GPT-3)来确定任务的类别。
给定新的指令,让预训练的语言模型生成回应。
在将回应添加到任务池之前,进行回应的收集、修剪和过滤。
模型算力
LORA
LoRA 技术的核心观点是,预训练的大语言模型在适应特定任务时,可能仅仅依赖于较低的“内在维度”。即使将其权重投射到较小的子空间,模型仍然可以有效地学习,这一观点构成了 LoRA 技术的理论基础。
通过下面这张图,LoRA 的实现思想很直观:我们首先冻结一个预训练模型的矩阵参数,然后选择使用 A 和 B 矩阵来代替这些参数。在下游任务的训练中,我们只对 A 和 B 进行更新即可。
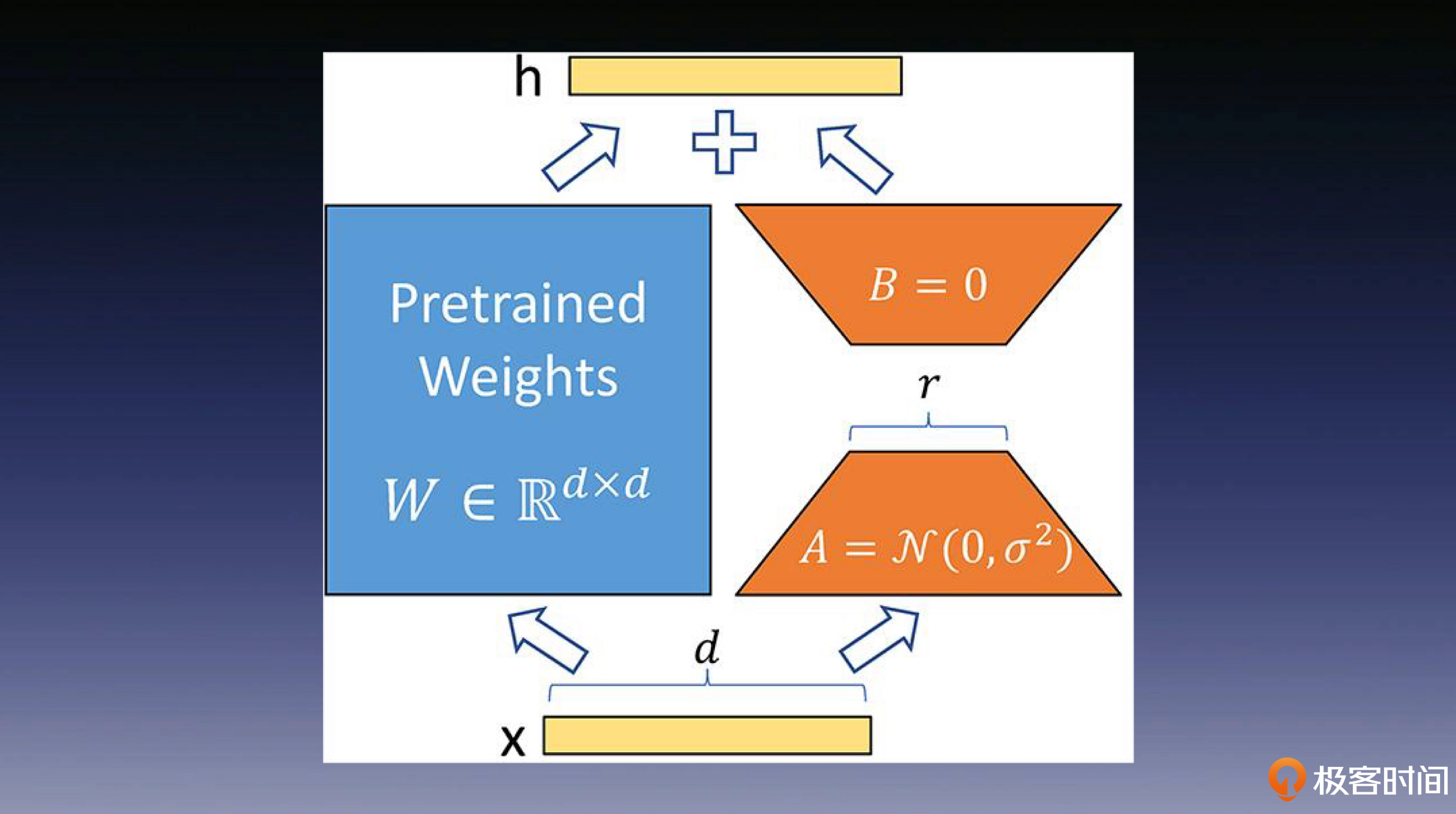
该方法会在原始的预训练模型右侧添加一个侧通道,进行降维和升维的操作,以模拟内在维度的概念。在训练的过程中,需要保持预训练模型的参数不变,只对降维矩阵 A 和升维矩阵 B 进行训练。模型的输入输出维度保持不变,在输出时,将 BA 矩阵与预训练的参数相叠加即可。在初始化时,使用随机高斯分布来初始化矩阵 A,同时使用零矩阵初始化矩阵 B,确保在训练开始时,这个侧通道矩阵是一个零矩阵。
下面是来自AI的总结:
LoRA技术是一种用于加速大语言模型训练的方法,通过低秩适应实现了对计算资源的高效利用。相比传统的微调方法,LoRA技术在模型适应特定任务时,仅依赖于较低的“内在维度”,从而有效降低了模型训练的成本。具体而言,LoRA使用低秩分解的方法来表示预训练的权重矩阵的更新,通过在微调过程中,使用全连接层的秩分解矩阵,间接训练神经网络中的一些全连接层,同时保持预先训练的权重不变。这种方法使得模型可以在消费级显卡上进行训练,并且甚至可以在树莓派上运行,非常适合用于小型的研究团队。LoRA技术的应用范围广泛,可以帮助以更低的成本完成模型训练,为算力受限的情况提供了解决方案。
LoRA技术让我们在充分利用了预训练模型的知识的前提下,大幅降低了微调训练的计算和内存开销,是一种高效的方法。 当然,LoRA技术并不仅仅适用于大语言模型,它可以应用在深度模型的各个模块,通过减少可训练参数的数量来提高效率。 举个例子,比如在 Transformer 模型中的在 Self-attention(自关注) 模块中通常包含四个权重矩阵(wq、wk、wv、wo),而在 MLP 模块(多层的神经网络)中通常包含两个权重矩阵。 LoRA技术允许将适应下游任务的注意力权重限制在自关注 Self-attention模块中,并冻结MLP模块,以简化和提高参数效率。
LoRA技术的另一个优点是,它可以在部署时以更低的成本切换任务。只需要交换LoRA权重即可。与完全微调相比,GPT-3 175B训练速度提高了25%,这是因为LoRA技术不需要计算绝大部分参数的梯度。
总的来说,LoRA技术通过精简信息更新参数,极大地减少了计算和内存的开销,提高了训练效率,同时在切换任务时的成本也很低。虽然在推理上会带来一定的开销增长,但在微调中带来了极大的算力节省。
实战训练
介绍了Huggingface的finetuning, 关于这一块,需要单独拎出来写篇博客。
工业级大模型回顾

风控策略
可以采用PromptBatch来实现风控策略。
样本制备
可以采用前面的self-instruct来制作语料
模型制备
对于小公司来讲,可以考虑LORA来微调成熟的大模型
大模型新机遇
下面是信通院发布的大模型AIGC产业图谱:
不擅长的地方
千万不要用大模型做你之前就已经能做得很好的事情
例如正则表达式
不要使用大模型做一些因果推断的核心任务
落地能力
那作为大型科技公司,应该如何在产业应用碎片化如此严重的情况下,以相对可控的成本,尽量完成尽量高的行业渗透呢?想清楚这个问题非常重要,因为甚至会影响你业务的生死存亡。要知道在这个过程中,稍有不慎,就会走入两个极端。
第一个极端是,我觉得我技术领先,所以所有的产业都应该来被我赋能、被我改造,天天坐在办公室中幻想。
另一个极端则是专家下工厂,无休止地派出自己的 AI 专家,到各个行业去整合方案,做定制开发,费时费力,费人费钱,到最后发现虽然声势浩大,但算了账以后却一点钱都没有赚到。
所以现在 AI 大模型技术相关的企业都在回归理智,虽然嘴上还在坚持之前所奉行的“数实融合”,但所做的工作都还是在“回归互联网”。而真正有能力“数实融合”的传统大型企业,其实都在构建自己的技术团队,自顶向下进行彻底的改革,很少让大型科技公司有插手的机会。
所以,各大科技公司索性回到自己 MaaS(模型即服务)的定位,通过互联网行业的数据和人才积累,训练出一个大模型作为护城河,解决好自己的任务,并且通过建立自己的人才和技术壁垒,让产业搞不定大模型这件事的时候,再来找你谈合作。
这样对产业的渗透速度和力度远没有之前妄想的那样多。不过这其实也是一个彼此价值回归的过程,到头发现谁也改造不了对方。如果你也是相关行业的参与者,或者即将加入这个战场,请一定要小心陷入这种“改造”或者“赋能”他人的陷阱。
一些问题及思考
预训练模型和大模型之间的关系是什么?
预训练模型(pre-training model)首先通过一批语料进行训练,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。为了最大化模型复用的效果,往往使用参数量较大的模型作为预训练模型的网络结构。
我们学习了如何给 LSTM 增加 Attention 机制,你可以思考一下,如果要给上节课学到的 CNN 增加这个机制,该如何做呢?
SE-Net: Squeeze-and-Excitation Networks
既然 BERT 的模型使用了大数据和大参数模型进行训练,那它是否属于大语言模型(LLM)呢?
BERT 属于大模型。它兼顾了参数量大(大型模型),训练数据量大(大量数据大规模训练)和迁移学习能力强(适应多种下游任务)几点,所以是一个大语言模型。
请你想一想,我们的模型里是否可以去掉位置编码?
是可以的。实际上,许多视觉模型已经这么做了,因为去掉固定的位置编码可以使模型更加通用,不需要根据输入数据的长度来调整模型。然而,在自然语言处理领域,通常会保留位置编码,因为目前还没有找到更高性价比的方法。
你觉得 GPT-3 和你目前所使用的 ChatGPT 之间最大的区别是什么?
GPT-3 只使用通用数据进行训练,可以应用于多种不同的 NLP 任务,例如文本生成、文本分类、文本摘要等,但没有针对对话语料进行输入对齐。ChatGPT 则是基于 RLHF 技术和人类的对话习惯进行了对齐,可以让大模型在与人类对话过程中发挥更多潜力。
由于 RLHF 只是单纯地根据已有的回答进行排序,是否会出现“自己吃自己”的循环,也就是用来训练模型的数据来自于模型自己生成的,“近亲繁殖”训练的模型水平是否会受影响?
会受影响。因此,OpenAI 一直没有停止使用 SFT 进行增量训练。
RLHF 和 SFT 的关系是什么?
SFT 后的模型可以生成多个答案作为 RLHF 的输入,RLHF 使回答更符合人的预期。其中更重要的是 SFT,因为如果没有 SFT,RLHF 将成为无源之水。
在构建 AI 系统时,你会如何权衡模型规模和训练数据量,你会选择用更多的数据和小模型,还是更少的数据和大模型?
当前市面上大多数开放源代码的自然语言处理(NLP)模型通常具备相对适中的规模,在 70 亿到 130 亿个参数之间。虽然“大力出奇迹”是大模型技术快速发展的重要原因,但参数规模的增长不是大模型技术的银弹,各位同学还是要在训练数据,模型架构和大模型智能涌现原理的理解上多下功夫。
你认为涌现任务会如何影响人工智能的哪些应用领域?对于未来涌现任务的发展,你有哪些期待和疑虑?
涌现的最大价值是让机器在远超人类的知识容量下,总结并产生新知,这会让人类在智力型任务上成为工具使用者,而不再是工具本身。这将大幅降低很多智力型工作的人力需求。
如果各个领域的微调数据都汇聚到 OpenAI 是不是会形成强大的虹吸效应,让他们拥有众多的私域数据?
你或许以为 GPT-4 的目的是协助你进行模型训练,但实际上 GPT-4 需要的是你的数据。如果各家企业的相关业务负责人因业绩压力而不顾数据安全,大规模使用 GPT-4 进行所谓的微调,将导致数据流失,进一步巩固 OpenAI 的市场垄断地位,迫使你不得不依赖其服务,直至无法脱离。最后,微软再通过垄断获得的定价权收割各个客户。当然,这也需要监管和竞争政策来平衡,以确保数据和模型不被集中在某一家机构手中。
很多人认为提示语工程只是自说自话的试错游戏,你觉得他说得对吗?给出你认为正确或错误的原因。
首先,你需要明白大语言模型自 GPT-2 以来就一直具备的一种能力,那就是通过与用户交互和提示语进行上下文学习(In-context Learning)。
在 GPT-2 中,提示语主要被用来向模型传递“指令”信息,使模型了解其正在进行的任务。而在 GPT-3 之后,提示语的内容逐渐演变成为了包含“示例”和“指令”的形式。其中,“示例”部分负责为模型提供任务场景的相关样例,帮助其掌握其中的规律;而“指令”部分被沿用下来,目的仍然是让模型明确自己的任务目标。
因此,提示语工程的本质其实是一种试图充分利用大语言模型上下文学习能力的方法。通过最佳的格式和最有效的示例及指令为模型提供指导,使其能更好地理解和解决给定问题。在这个过程中,不仅需要考虑具体任务数据集的特性,而且也需要关注大语言模型本身的行为和表现。
为此,我们会运用一系列基于统计或基于监督学习的提示语工程技术,以提高模型的性能表现。所以提示语工程并不是自说自话的试错游戏,而是非常依赖于实际数据和模型特性的数据驱动工作。
如果只允许你为自己的大模型系统,添加一个这节课学到的提示语工程能力,你会选择哪个,为什么呢?
APE方法
如果让你用前几节课学到的提示语工程方法构建一个智能体,让它融入这个社会,你有什么思路吗?
智能体反思过去和规划未来的能力
结合我们课程里学过的知识,谈一下你对大语言模型外部记忆作用的理解。
大语言模型外部记忆主要有以下几个作用,第一是针对特定的任务提供优质的示例,第二则是存储大模型需要使用的海量外部知识,第三是帮助大模型存储能用到的外部工具,第四是记录大模型的会话信息或者智能体的记忆。
根据这节课学习的知识,你认为使用 Alpaca 增强数据微调模型的上限是什么?
Alpaca 或者说 self-instruct 的各种变种,本质上是在做模型对齐,如果你使用 GPT-4 来生成增强语料,则是在对齐目标任务领域上,你的模型与 GPT-4 之间的能力,所以上限就是你所选择对齐的那个模型。
通过你对 LoRA 的学习,分析一下在使用 LoRA 微调的过程中,可能会存在哪些问题?
可能存在 LoRA 的参数空间过大,无法完全测试,所以要引入一些超参数搜索的方法,比如 AutoML 的策略。
请通过 AutoML 的方法自动化 LoRA 的调参过程。
可以使用 Amazon 论文的方法,或者用到了 LoRA 和 AutoML 技术都是合理的。
结合你对前面学习的知识,辨析一下 LoRA 方法和向量检索中的经典 ANN 算法 PQ 之间有何联系?(这是一道我曾面试 AI 大模型相关业务候选人的题目)
两个方法都是低维映射的矩阵来近似替代原矩阵,来提高工作效率。
根据前面学习的 GPT 系列原理的知识,想一想构建一个规模达到 100B 及以上的模型需要怎么做。
GPT-3 是在 GPT-2 的基础上进行了参数量和训练数据规模的提升,所以一定程度上 GPT-2 是一个小型的 GPT-3。同时,GPT-2 也是 OpenAI 最后一次完整公开的 GPT 系列代码开源工作,之后已经渐渐成为 CloseAI 了。