课程链接:https://b.geekbang.org/member/course/intro/100541001
github: https://github.com/MSzgy/AI-model-Beauty (只有部分章节代码)
介绍
课程共分为 3 个模块(下面内容来自于课程的抄录)。共32讲
基础知识篇。带你探究大型语言模型的基本能力。通过提示语(Prompt)和嵌入式表示(Embedding)这两个核心功能,看看大模型能帮我们解决哪些常见的任务。通过这一部分,你会熟悉 OpenAI 的 API,以及常见的分类、聚类、文本摘要、聊天机器人等功能,能够怎么实现。
实战提高篇。开始进入真实的应用场景。要让 AI 有用,不是它能简单和我们闲聊几句就可以的。我们希望能够把自己系统里面的信息,和 AI 系统结合到一起去,以解决和优化实际的业务问题。比如优化传统的搜索、推荐;或者进一步让 AI 辅助我们读书读文章;乃至于让 AI 自动根据我们的代码撰写单元测试;最后,我们还能够让 AI 去决策应用调用什么样的外部系统,来帮助客户解决问题。
语音与视觉篇。光有文本对话的能力是不够的,这部分会进一步让你体验语音识别、语音合成,以及唇形能够配合语音内容的数字人。还会教会你如何利用现在最流行的 Stable Diffusion 这样的开源模型,去生成你所需要的图片。并在最后,把聊天和画图结合到一起去,为你提供一个“美工助理”。
注意:本文文字内容较多
基础知识篇
涉及到以下内容:
代码环境的配置
举情感分析的例子,将LLM与传统的机器学习做对比,并说明利用LLM可以不用自己筛选特征,可以直接利用LLM做分析。通过利用embedding model 将文本转为向量,利用向量余弦距离做比较。 同时文中举了个利用embedding model做文本分类(5讲),文本聚类的的例子(7讲)。(2,3,5,7讲)
from openai import OpenAI
import numpy as np
import os
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
EMBEDDING_MODEL = "text-embedding-ada-002"
def get_embedding(text, model=EMBEDDING_MODEL):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
def cosine_similarity(vector_a, vector_b):
dot_product = np.dot(vector_a, vector_b)
norm_a = np.linalg.norm(vector_a)
norm_b = np.linalg.norm(vector_b)
epsilon = 1e-10
cosine_similarity = dot_product / (norm_a * norm_b + epsilon)
return cosine_similarity
positive_review = get_embedding("好评")
negative_review = get_embedding("差评")
positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质")
negative_example = get_embedding("随意降价,不予价保,服务态度差")
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("好评例子的评分 : %f" % (positive_score))
print("差评例子的评分 : %f" % (negative_score))将几个预训练模型通过零样本测试进行比较,包括Fasttext,T5-small,T5-base。结果:Fasttext只包含词向量信息(没有词序信息),因此效果较差,T5模型包含相关词序信息,效果稍好,最后的结果是当然是openai 模型效果最好。(4讲)
使用Gradio以及chatgpt api实现了包含context的聊天机器人,并教导如何部署到huggingface上(6讲)
关于LLM输出安全问题,本文提供了几个建议(8讲):
通过 logit_bias 参数精确控制内容
使用英文来减少 Token 的使用
成本控制,对于model的ltoken价格应该心中有数,采用合适的模型做不同的业务。
利用moderate接口做内容安全审核。
实战提高篇
让AI生成实验数据,作为之后的训练(9讲)
利用llamaIndex,langchain连接个人知识库 (10讲)
做RAG搜索 ,
相关文章的总结
图片识别
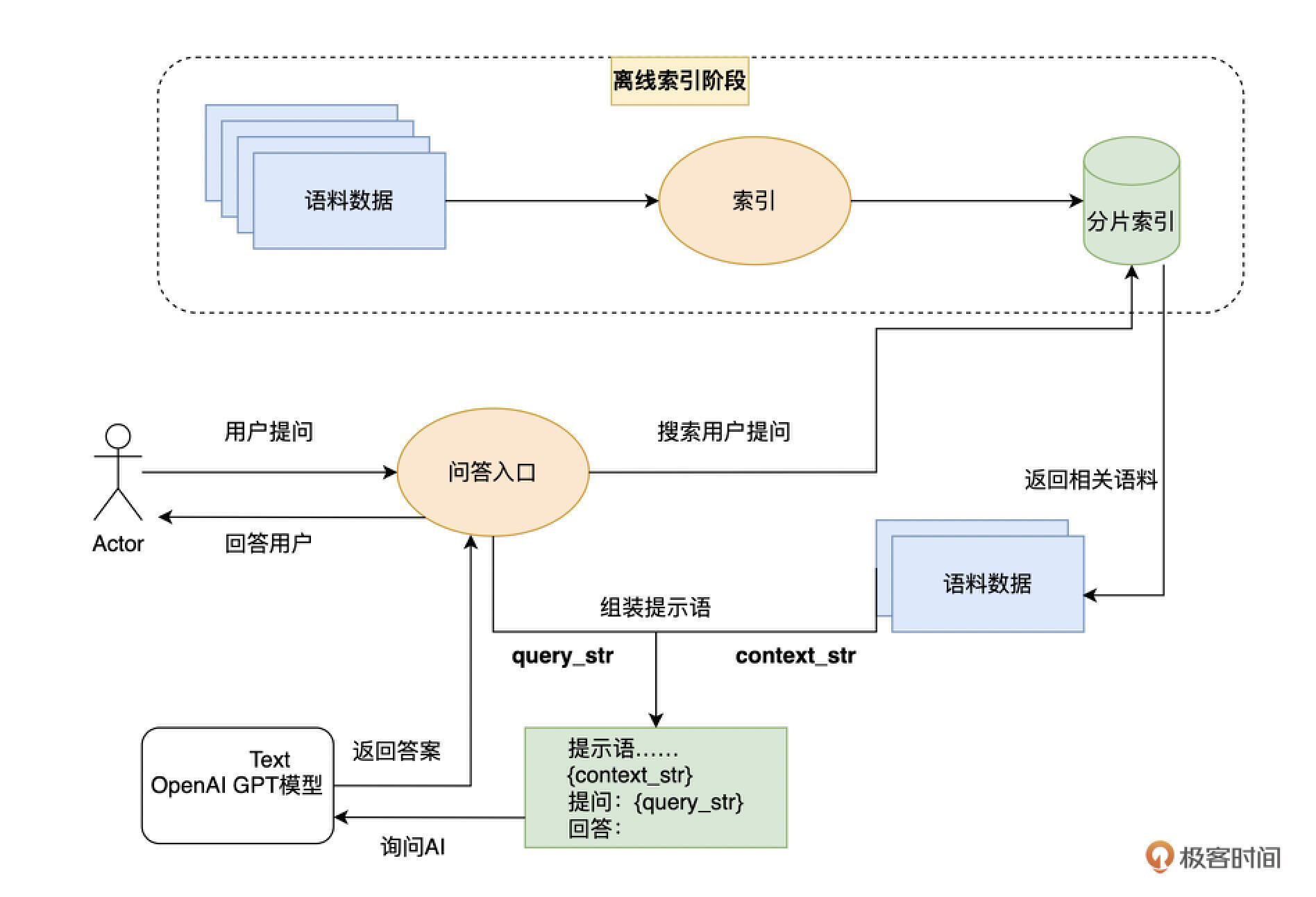
通过Huggingface平台使用开源模型来代替 ChatGPT。通过 sentence_transfomers 类型的模型,生成了文本分片的 Embedding,并且基于这个 Embedding 来进行语义检索。通过 ChatGLM 开源模型,实现了基于上下文提示语的问答 (11讲)
利用AI写个Excel插件 (12讲)
利用AI写UT code, 在本讲中,讲了提示语的技巧:将一个问题,拆分成多个提示语的步骤,循序渐进地让 AI 通过解释代码,构造测试用例,最后再根据代码的解释和设计的测试用例,生成最终的自动化测试。 多步提示语带来的一个好处,就是我们的内容是更加有条理、有逻辑的,也更符合我们平时写文字的方式,而不是一股脑地把各种要求都放在提示语的开头,这在解决复杂问题时往往效果不好。(13讲)
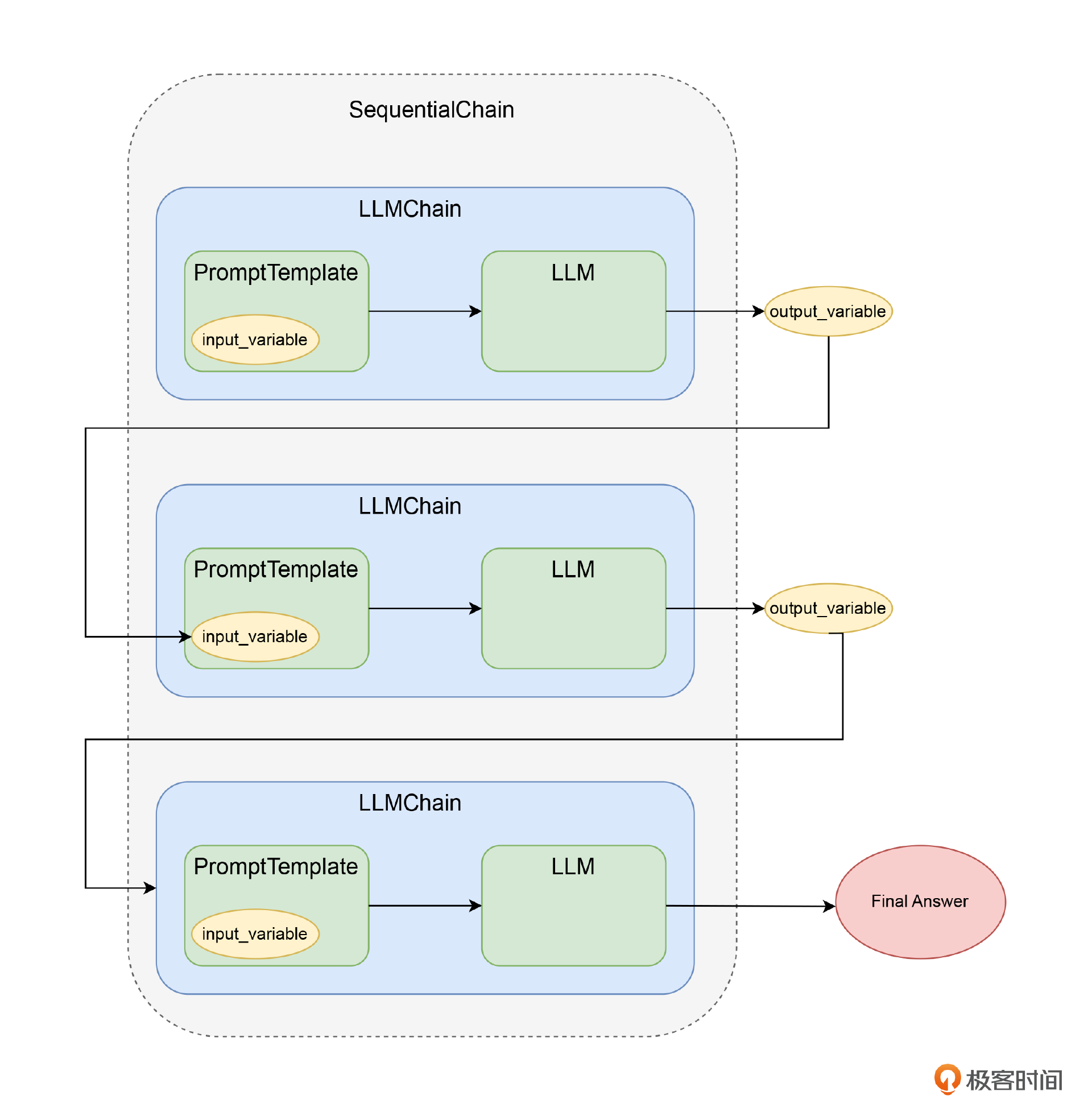
在多讲中介绍了langchain工具的使用
利用langchain中进行多步提示,将多条问答串联起来 (14讲)
利用langchain调用外部工具 (15讲)
介绍langchain中的各种memory机制(16讲)
BufferWindow,滑动窗口记忆
SummaryMemory,把小结作为历史记忆
前两个两者结合,使用 SummaryBufferMemory
利用save_context保存自定义memory
EntityMemory,只记忆某些实体信息
利用langchain做Agent,Langchain 让 AI 自动为我们选择合适的 Tool 去调用。我们可以把回答不同类型问题的 LLMChain 封装成不同的 Tool。 (17讲)
利用openai平台做模型微调,可以根据自己的提示按微调训练数据生成想要内容。(18讲)
多模态模型篇
利用Whisper语音识别模型或者开源模型将音频转为文字,做总结 (19讲)
利用Azure api或者PaddleSpeech进行语音合成,可以指定不同的人声(voice_name)、语气(style)还有角色(role)。(20讲)
制作数字播报员,通过 D-ID.com 这个 SaaS,提供了一个能够对上口型、有表情的数字人来回复问题,进一步尝试使用开源的 PaddleBobo 项目,来根据文本生成带口型的口播视频。(21讲)
利用huggface api在本地部署自己的大模型,如果本地硬件不够,可以利用Inference API来调用huggingface远程模型 (22讲)
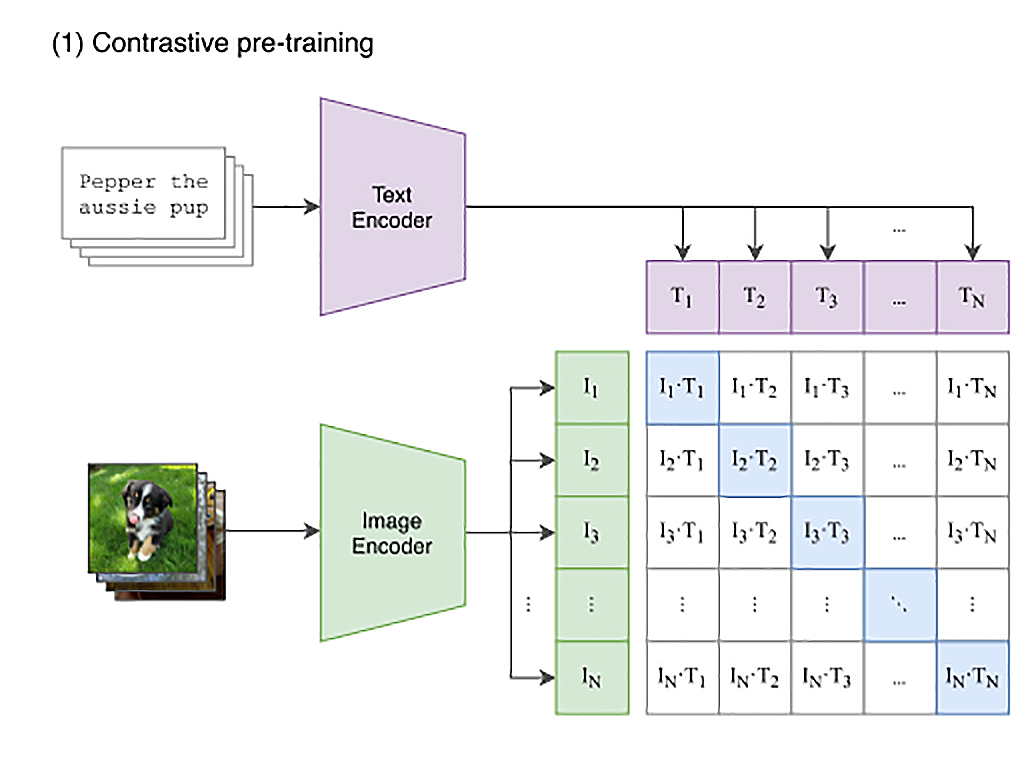
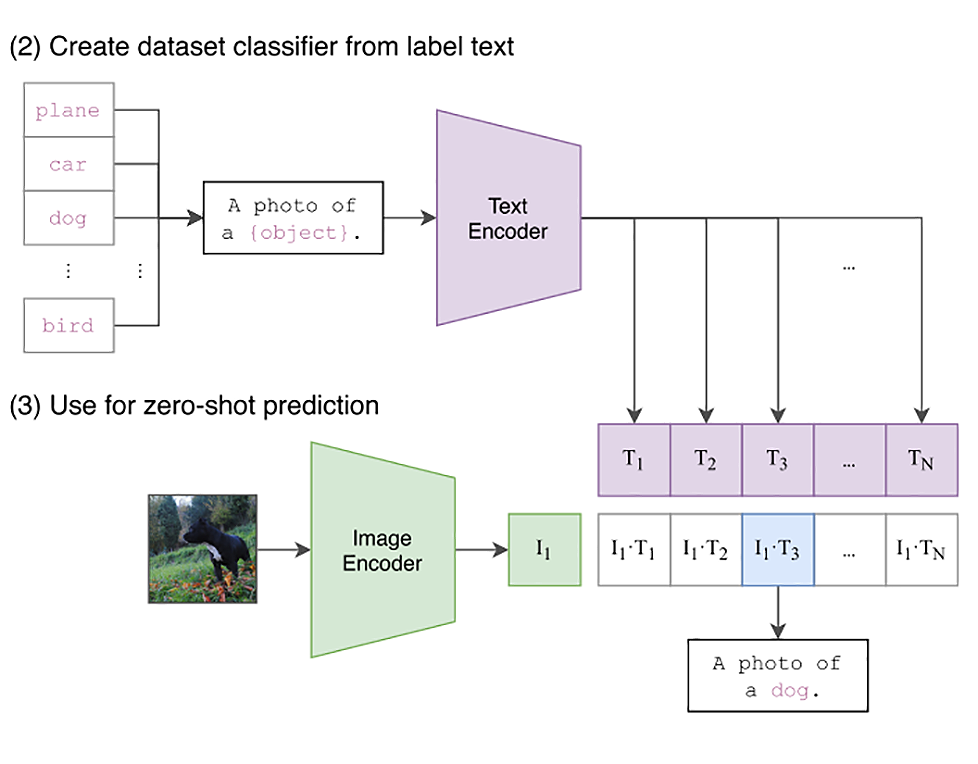
利用openai的CLIP模型做图片方面的工作,与文本分类类似,将图片利用CLIP模型转为向量做分类,除此以外,文中还利用CLIP模型结合openCV做目标检测。(23讲)
CLIP模型架构图
CLIP 的思路其实不复杂,就是互联网上已有的大量公开的图片数据。而且其中有很多已经通过 HTML 标签里面的 title 或者 alt 字段,提供了对图片的文本描述。那我们只要训练一个模型,将文本转换成一个向量,也将图片转换成一个向量。图片向量应该和自己的文本描述向量的距离尽量近,和其他的文本向量要尽量远。那么这个模型,就能够把图片和文本映射到同一个空间里。我们就能够通过向量同时理解图片和文本了。
利用CLIP模型结合huggingface package做文搜图以及图搜图
使用 Stable Diffusion 生成图片,使用的模型是stable-diffusion-v1-5 (24讲)
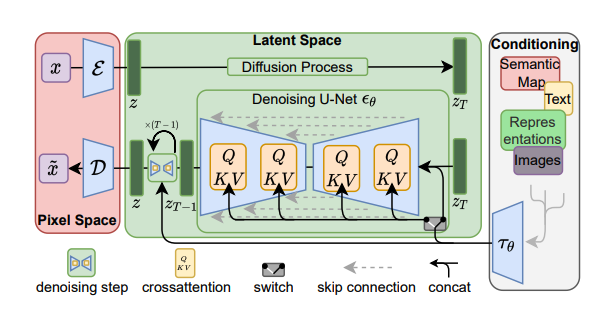
模型架构图,下面只是简单的介绍(代码库第24讲也有),在架构图中,其实涉及到多个模型。
这张图展示了扩散模型(Diffusion Model)的一种架构,通常用于生成图像的任务,比如图像生成、超分辨率或图像编辑。该架构结合了U-Net与跨注意力机制(cross-attention),并通过**条件输入(Conditioning)**来引导图像生成。图的不同部分表示模型从输入到输出的整个流程,包括从像素空间到潜在空间的映射,以及从噪声中逐步去噪的过程。 1. Pixel Space (像素空间) • 左侧的 x 和 x̃ 表示图像数据: • x 表示输入图像。 • x̃ 表示经过扩散过程后加入噪声的图像。 • Ε(编码器):将输入图像  从像素空间映射到潜在空间,生成潜在向量 ,表示高维的抽象特征。 • D(解码器):将扩散过程得到的潜在向量  映射回像素空间,生成最终输出的图像。 2. Latent Space (潜在空间) • 扩散过程(Diffusion Process):这是图像生成中的关键步骤。扩散模型逐步添加噪声,模拟一个向潜在空间转换的过程。扩散过程将输入数据逐渐转变为随机噪声,然后通过模型逐步去噪恢复。 •  表示加了最多噪声的潜在向量。 •  表示去噪的结果,逐步移除噪声。 3. Denoising U-Net (去噪U-Net网络) • U-Net 结构:去噪的核心网络是一个 U-Net,负责将噪声潜在变量逐步还原成没有噪声的表示。在每一个时间步骤 ,它会移除噪声。 • 中间的 U-Net 部分使用了跳跃连接(skip connections),将输入图像中的信息直接传递到解码器部分,使得模型在去噪的过程中能够更好地保留细节。 • 跨注意力机制(cross-attention):模型在去噪过程中使用跨注意力机制  来从条件输入(如文本、图像等)中提取相关的信息。 4. Conditioning (条件输入) • 右侧的 Conditioning 区域展示了条件输入。模型可以通过不同类型的信息进行条件化控制图像生成: • 文本:通过自然语言描述生成特定图像。 • 表示(Representations):其他图像特征或者信息可以作为条件输入,比如语义地图、草图等。 • 条件输入通过  传递给 U-Net,在去噪过程中通过跨注意力机制整合这些信息,帮助生成与条件输入匹配的图像。 5. 其他元素 • 去噪步骤(denoising step):每一个去噪步骤试图逐渐去除噪声,使得噪声潜在向量逐步还原为清晰的图像表示。 • 跳跃连接(skip connection):允许输入特征在多个层之间流动,避免信息丢失,帮助生成更高质量的图像。 总体流程总结 1. 图像  被编码为潜在向量 。 2. 在潜在空间中加入噪声,逐步扩散为 。 3. U-Net 在每个时间步骤中通过去噪从  逐渐恢复图像。 4. 去噪过程受到条件输入(文本、语义图等)的引导,通过跨注意力机制从条件中提取相关信息。 5. 最终生成去噪后的潜在表示 ,并通过解码器  还原回像素空间,生成清晰图像。 StableDiffusionPipeline { "_class_name": "StableDiffusionPipeline", "_diffusers_version": "0.15.1", "feature_extractor": [ "transformers", "CLIPFeatureExtractor" #这个就是在23讲介绍的CLIP模型,可以提取图片的特征 ], "requires_safety_checker": true, "safety_checker": [ "stable_diffusion", "StableDiffusionSafetyChecker" ], "scheduler": [ "diffusers", "PNDMScheduler" ], "text_encoder": [ "transformers", "CLIPTextModel" ], "tokenizer": [ "transformers", "CLIPTokenizer" ], "unet": [ "diffusers", "UNet2DConditionModel" ], "vae": [ "diffusers", "AutoencoderKL" ] }文生图,文章中举了一个详细的例子,从第1步一直到最后,展示了图片的生成过程。随着逐步降噪,图片越来越清晰。
step 0
step 5
Step 15
Step 25
图生图,给出草图,然后再结合prompt可以输出想要的风格
草图(输入)
宫崎骏风格
增强图片分辨率
介绍了通过开源的社区模型来产生自己想要风格图片,笔者在去年也玩过一些lora模型,网址:https://civitai.com/
利用huggingface的Diffusers库 以及 ControlNet控制人物姿势,状态 (25讲)
ControlNet 是在 Stable Diffusion 的基础上进行优化的一个开源项目,它既对原本的模型架构进行了修改,又在此基础上进行了进一步地训练,提供了一系列新的模型供你使用。
ControlNet 会对输入的图片进行人物姿势识别,然后应用到你想要的图片上
通过简笔画来画出好看的图片
利用Visual GPT实现边聊边画 (26讲)
本文中的Visual GPT按照介绍可以去huggingface公开的space中去体验,但笔者经过尝试,space中app报错,微软也没修复。
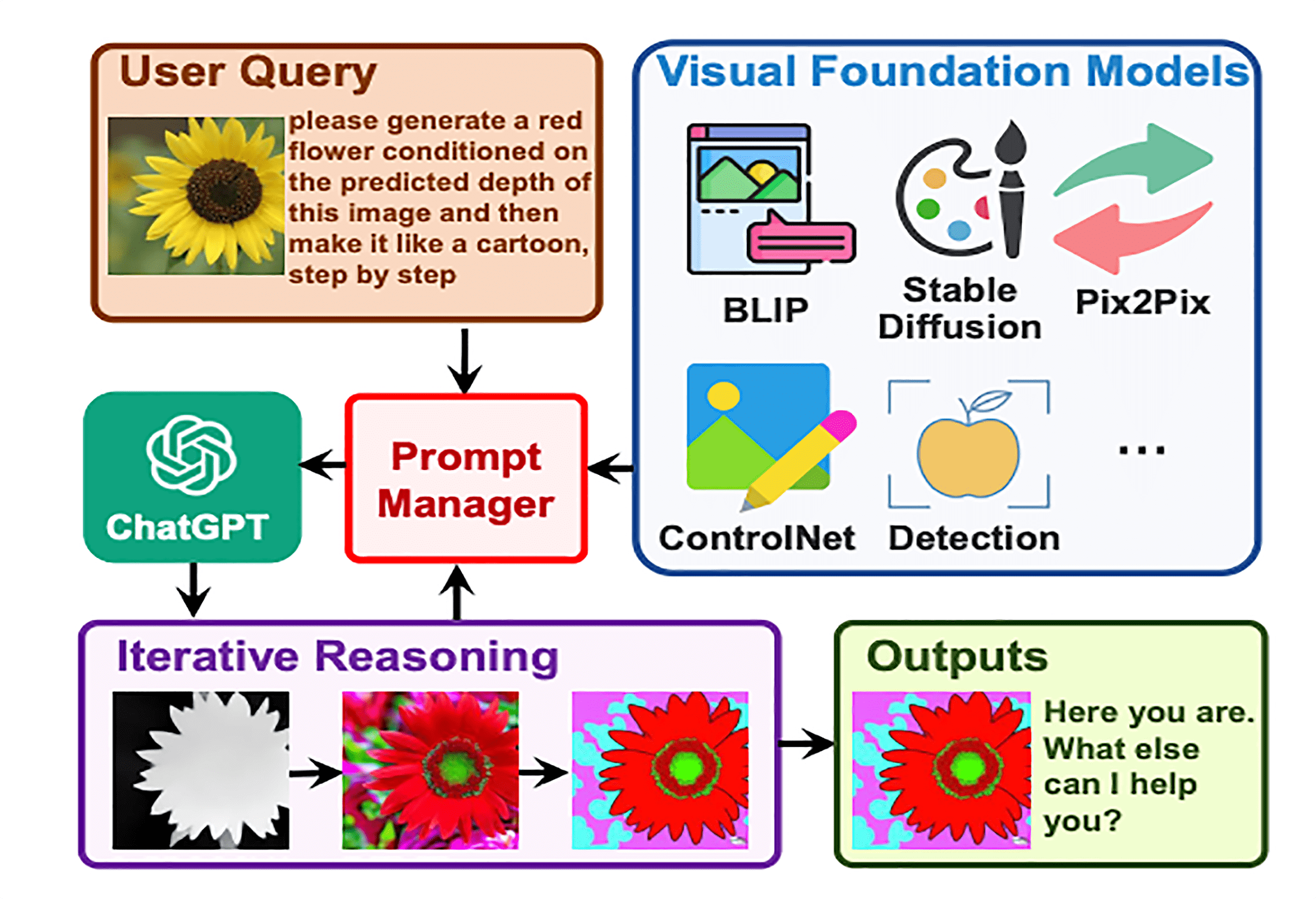
结构图
文章中对模型的描述:回顾整个 Visual ChatGPT 的代码,其实并不复杂。它就是将第 17 讲我们介绍过的 LangChain 的 Agent,和过去 3 讲我们介绍的各种视觉大模型组合起来,通过 ChatGPT 的语言和逻辑推理能力处理用户输入,通过 LangChain 的 Agent 机制来调度推理过程和工具的使用,通过视觉大模型实际来处理图片以及理解图片的内容。
模型所做的步骤:它把各种各样图像处理的视觉基础模型(Visual Foundation Model)都封装成了一个个 Tool。 然后,将这些 Tool 都交给了一个 conversation-react-description 类型的 Agent。每次你输入文本的时候,其实就是和这个 Agent 在交流。Agent 接收到你的文本,就要判断自己应该使用哪一个 Tool,还有应该从输入的内容里提取什么参数给到这个 Tool。这些输入参数中既包括需要修改哪一个图片,也包括使用什么样的提示语。这里的 Agent 背后使用的就是 ChatGPT。 最后,Agent 会实际去调用这个 Tool,生成一张新的图片返回给你。
探索AI产品体验,本文没有谈任何技术东西,只是通过Midjourney这个产品引发了一些思考。(27讲)
Midjourney团队只有几十个人,但是确做出了如此出色的产品
尽可能给客户提供简单的操作,给出一些prompt让客户去尝试,而不是在一开始就让客户做输入操作
在处理用户的请求时,可以同时多批次处理多个请求,避免让客户一个个等待
让用户反馈,如chatgpt的每次回答都有相应的按钮让客户对回答做反馈
Function calling (新加内容)
由于本课程是23年上半年的,function calling当时还没推在openai api推出,因此追加了此节,由此可见function calling的火热程度。(可以见本博客其他课程,或直接看本篇课程代码)