github: https://github.com/MSzgy/Retrieval-Optimization-From-Tokenization-to-Vector-Quantization
Introduction
本篇课程讲了tokenizer技术,研究了不同tokenizer技术带来的效果。
同时利用量化技术来减少vector存储的占用, 以及如何提高search速度,主要有三种量化技术,1 product quantization 2 scalar quantization 3 binary quantization
Embedding models
tokenizer分类
字符粒度的分词

word粒度的分词

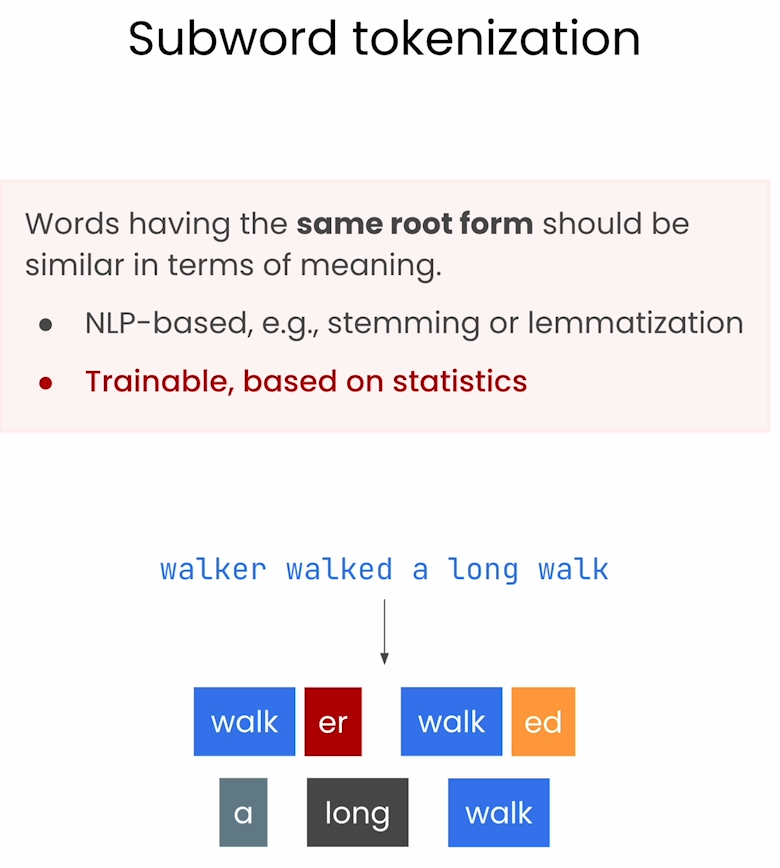
sub word粒度的分词
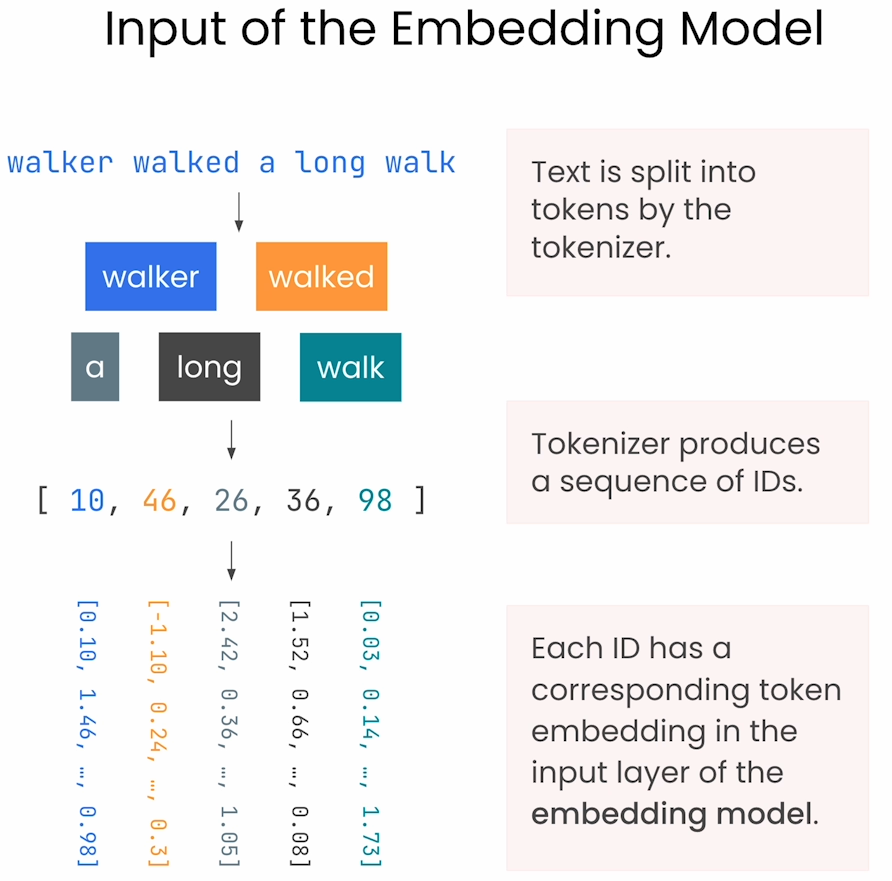
文本向量化过程
word embeddings
embeddings = first_module.auto_model.embeddings
# embeddings output
BertEmbeddings(
(word_embeddings): Embedding(30522, 384, padding_idx=0)
(position_embeddings): Embedding(512, 384)
(token_type_embeddings): Embedding(2, 384)
(LayerNorm): LayerNorm((384,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
# The word embeddings are all same for the same word
The word embeddings are all identical for same word.
 下面这张图是将高维的word embeddings降到二维形成的图,其中绿色代表了一些表示语义的词语,占绝大多数; 蓝色代表了英语中的一些表示状态的后缀词(##ing, ##ed, ##tion),由此可见,这里采用的是subword分词方式;红色代表了不是英语的词语,如中文,日文单词,这是由于本embedding model是在因为语料上训练得到的。
下面这张图是将高维的word embeddings降到二维形成的图,其中绿色代表了一些表示语义的词语,占绝大多数; 蓝色代表了英语中的一些表示状态的后缀词(##ing, ##ed, ##tion),由此可见,这里采用的是subword分词方式;红色代表了不是英语的词语,如中文,日文单词,这是由于本embedding model是在因为语料上训练得到的。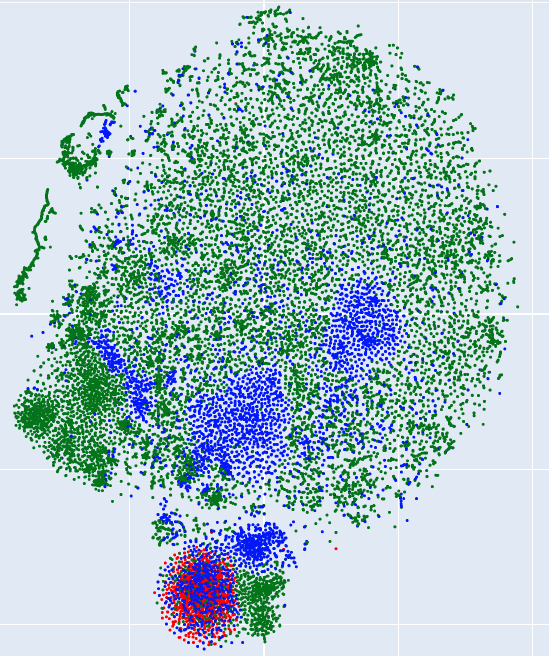
token embeddings
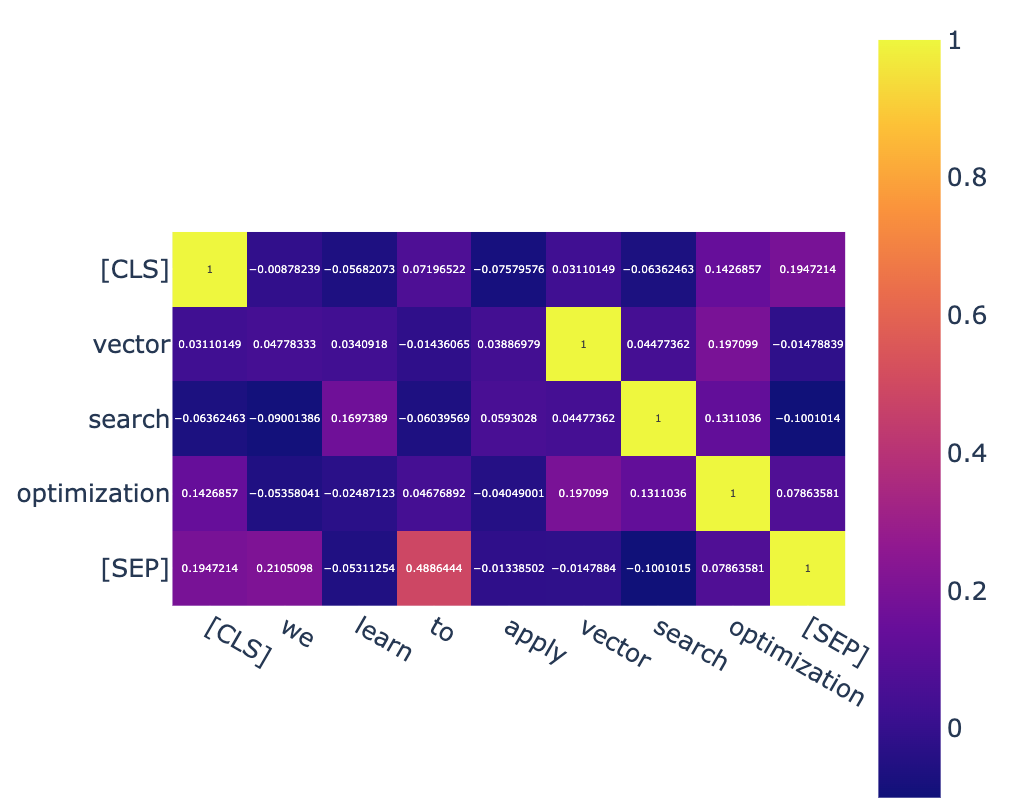
上面的代码仅仅代表word embeddings,但是每个word在context中都有不同的含义,因此需要加入position信息。
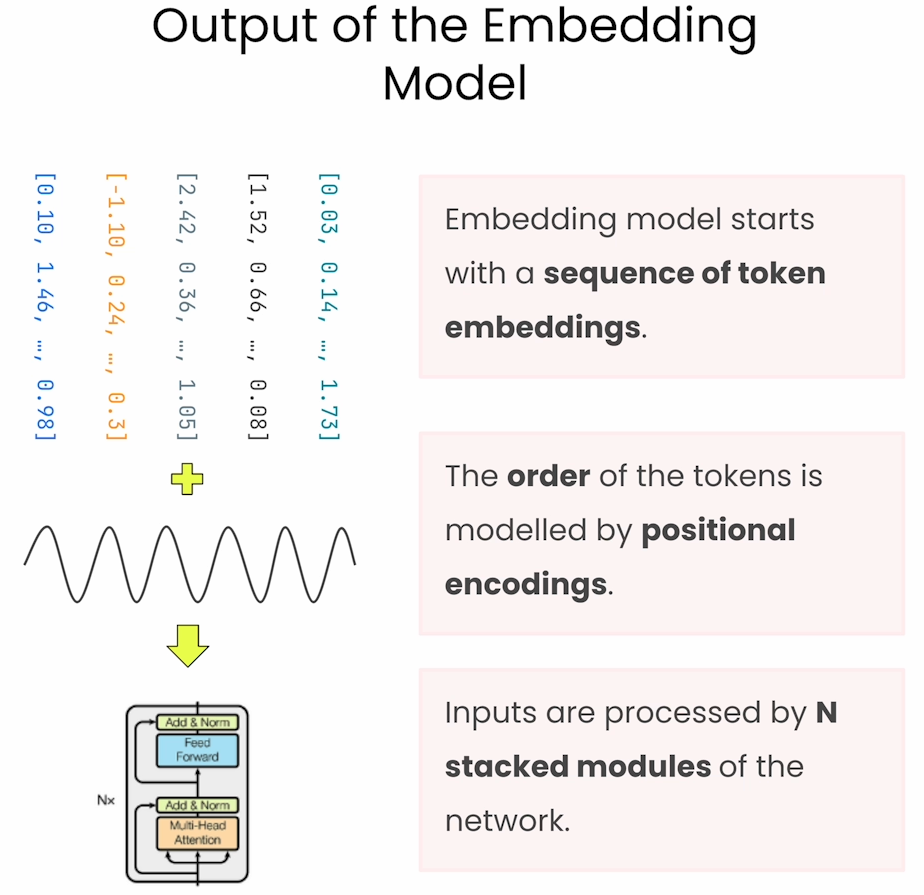
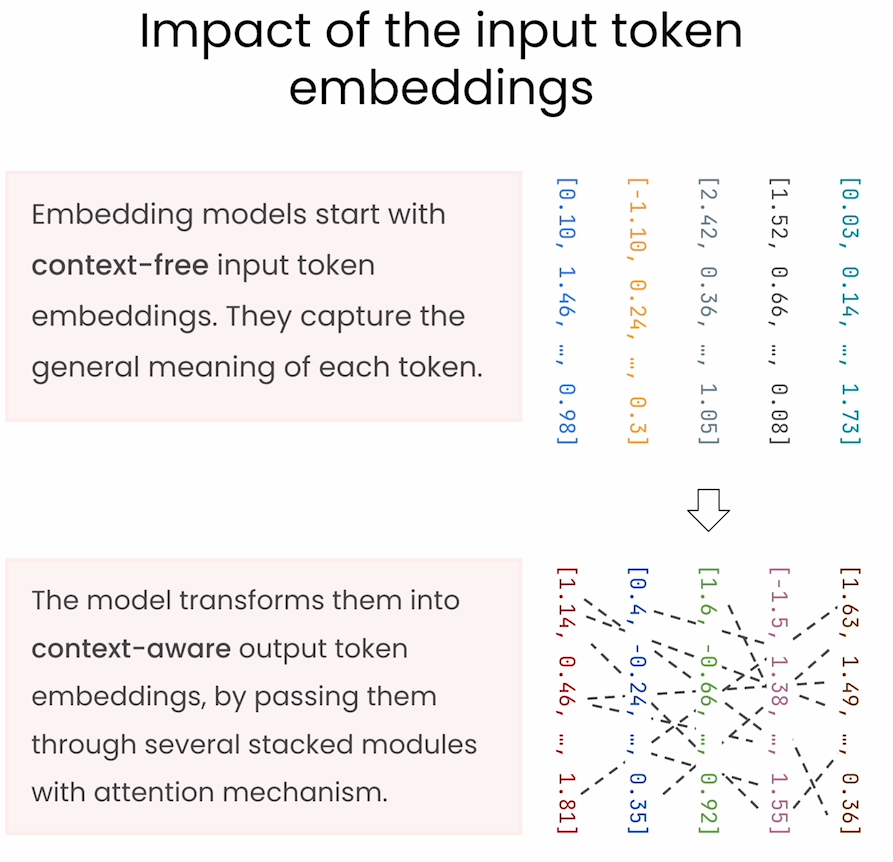
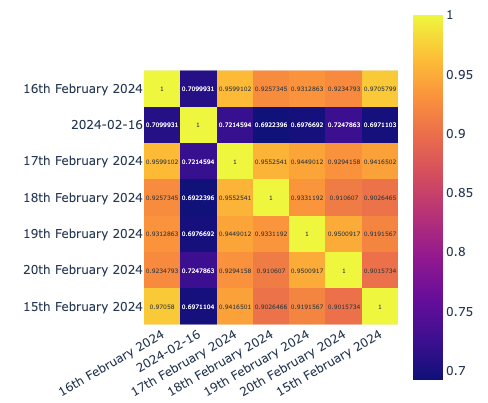
下面是对加入position的词向量之间的关系图,可见相同的单词相关性不为1了,而是各个不同的值。

Role of the tokenizers
几种tokenzier方法

BPE


将上文的byte继续merge,例如w al 会形成新词wal,并添加到vocabulary set中这样的过程会一直持续下去,直到满足vocabulary se数量要求。


Wordpiece
这种tokenizer方式是考虑单词有某些后缀,单词的前面几个字母代表单词意思,后缀代表状态,例如walk walking walked 意思应该相近,所以这里会把后缀加上 “##” 方式来记录,具体可以看下面的图片。


Unigram


SetencePiece

区别与联系
BPE (Byte-Pair Encoding)、WordPiece、Unigram、SentencePiece 是常见的分词算法,用于将句子或文本分割成较小的单元(如子词或字符),并将其转换为模型能够理解的表示。它们的主要区别在于分词策略和处理方法上。
1. BPE (Byte-Pair Encoding)
• 基本概念: BPE 是一种基于统计的分词方法,最早用于数据压缩。它通过合并频率最高的字符或子词来逐步构建词汇表。
• 工作原理:
1. 首先将文本分解为字符。
2. 找出在文本中最常出现的字符对,合并它们作为新的子词单元。
3. 重复此过程,直到构建出指定大小的词汇表。
• 优点:
• 通过逐步合并,可以动态选择子词的长度,能够处理未见过的单词。
• 应用: OpenAI 的 GPT-2、GPT-3 使用 BPE 作为分词器。
2. WordPiece
• 基本概念: WordPiece 是由 Google 开发的一种分词方法,最早用于训练 BERT 模型。与 BPE 类似,WordPiece 也通过统计分析构建词汇表,但它会更关注最大化语言模型的概率。
• 工作原理:
1. 与 BPE 类似,最初也是将词分解为字符。
2. 逐步合并频率高的字符或子词,但在选择哪些子词合并时,WordPiece 更倾向于选择那些能够提高语言模型预测能力的子词。
• 优点:
• 更加注重生成的子词如何提高模型的预测性能,能更好地处理语言多样性。
• 应用: BERT、ALBERT 等模型使用了 WordPiece。
3. Unigram
• 基本概念: Unigram 分词法是一种概率分词模型,由 SentencePiece 引入。与 BPE 和 WordPiece 不同,Unigram 分词不依赖频率合并,而是从一个较大的候选词汇表中选择最优的子词集合。
• 工作原理:
1. 从大量候选子词开始,包括完整的词和较小的子词。
2. 通过最大化给定文本的概率来逐步删除低频率、不重要的子词,从而保留最重要的子词集合。
• 优点:
• 可以为同一个词生成多个子词分割方案,从而允许更灵活的分词选择。
• 应用: T5、XLNet 使用 Unigram。
4. SentencePiece
• 基本概念: SentencePiece 是 Google 开发的一种分词方法,它实现了 BPE 和 Unigram 算法的结合,并且可以处理不依赖于空格的分词,即无需预先进行空格标记。
• 工作原理:
1. SentencePiece 不要求对输入文本进行预处理(如去掉空格),这使得它能处理各种语言,不仅限于空格分隔的语言(如英语)。
2. 它可以使用 BPE 或 Unigram 作为其分词策略,依据具体需求选择。
• 优点:
• 不需要对输入进行空格标记处理,能够灵活应用于多种语言,尤其是对形态复杂的语言(如中文、日语、韩语)非常友好。
• 应用: T5、ALBERT、BART、mT5 等模型使用了 SentencePiece。
总结对比:
• BPE: 基于频率的逐步合并字符对,生成子词单元。
• WordPiece: 类似于 BPE,但更加关注子词对语言模型的贡献。
• Unigram: 从候选子词中选择最优的子词集,不依赖频率合并。
• SentencePiece: 一种框架,既支持 BPE 又支持 Unigram 分词,并能处理没有空格的文本。
它们在不同场景下有不同的应用,但目标都是为了以更细粒度处理语言,尤其是当遇到未知词汇或跨语言任务时。
Practical Implications of the tokenization
本节举了几个特殊的例子,说明了,有时embedding model并不是可靠的,并没有想象中的那么理解语义:
由于某些词语在vocabulary list 没有,有可能会把两个完全相反的词识别到[UNK](unkonwn),就会导致两个文本词向量相似甚至一样。
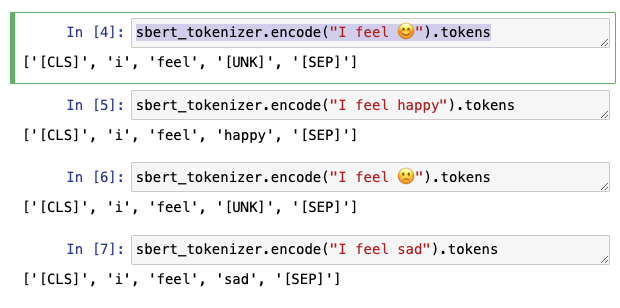
从下面图可以看出两个完全相反的表情,相关性是1
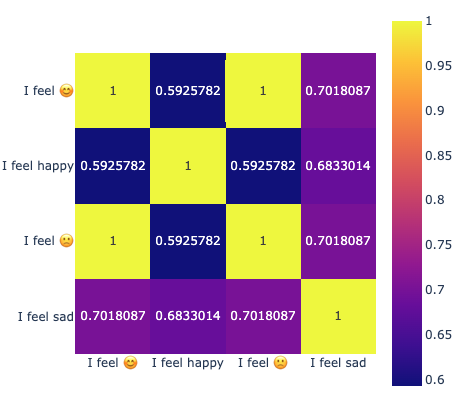
对于一些特殊名词,会将词拆开,从而改变原有意思
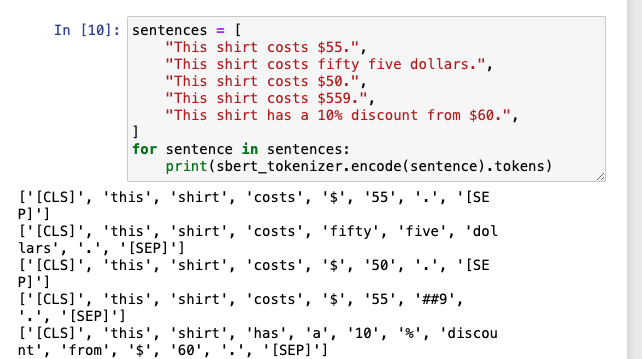
对于数字表示,不同tokenizer方式,会把数字拆分成不同形式
对于同义词的不同表达方式,词向量也会出现完全不同的含义

代码中对于不同的模型做了比较,相对来讲openai的方式效果较好。
Measuring Search Relevance
在建立一个robust的RAG app时,需要衡量搜索相关性,所以需要build ground truth.

代码中举了使用Qdrant数据库的例子,类似之前的mongodb课程https://halo.mosuyang.org/archives/prompt-compression-and-query-optimization,采用的最近邻算法(KNN)去查找。
下面介绍了几种Qualtiy评判标准。

Relevancy based metrics
准确率与召回率作为评判标准

Ranking related metrics

Score related metrics
同时考虑了relevance以及relvevance中的相关性排名


封装好的python package
ranx

Optimizing HNSW search
HNSW(Hierarchical Navigable Small World)是一种高效的近似最近邻搜索(Approximate Nearest Neighbor, ANN)算法。它基于图(Graph)的数据结构,通过构建分层的小世界图来快速查找高维空间中的最近邻点。HNSW 的核心思想是通过建立多个层次,每个层次上的节点彼此连接,形成一个分层图,从而在高维向量空间中加速搜索。
HNSW 的工作原理:
1. 分层图结构:HNSW 构建了一系列层次图,底层图包含所有数据点,越高层的图包含的数据点越少。每一层之间的节点通过边相连,形成一个分层的小世界图。
2. 搜索过程:在进行查询时,算法从最高层开始搜索最近邻,然后逐层向下。在较高的层次上,数据密度低,可以快速跳跃到接近目标的区域;在较低的层次上,搜索范围更小,可以更精确地找到最近邻。
3. 动态插入:HNSW 允许在图中动态插入新的数据点,并自动调整图结构,从而适应不断变化的数据集。
优点:
• 高效查询:通过分层搜索结构,可以快速找到近似最近邻,尤其在高维数据空间中表现优异。
• 可扩展性:HNSW 能够动态调整图结构,支持增量式地添加数据。
• 精度和速度权衡:HNSW 可以在搜索精度和搜索速度之间进行调整,适应不同的应用场景需求。
应用场景:
HNSW 广泛应用于向量检索、推荐系统、图像搜索、自然语言处理(NLP)等领域,尤其适合用于大规模的高维数据集,如图像特征向量、文本嵌入向量等。
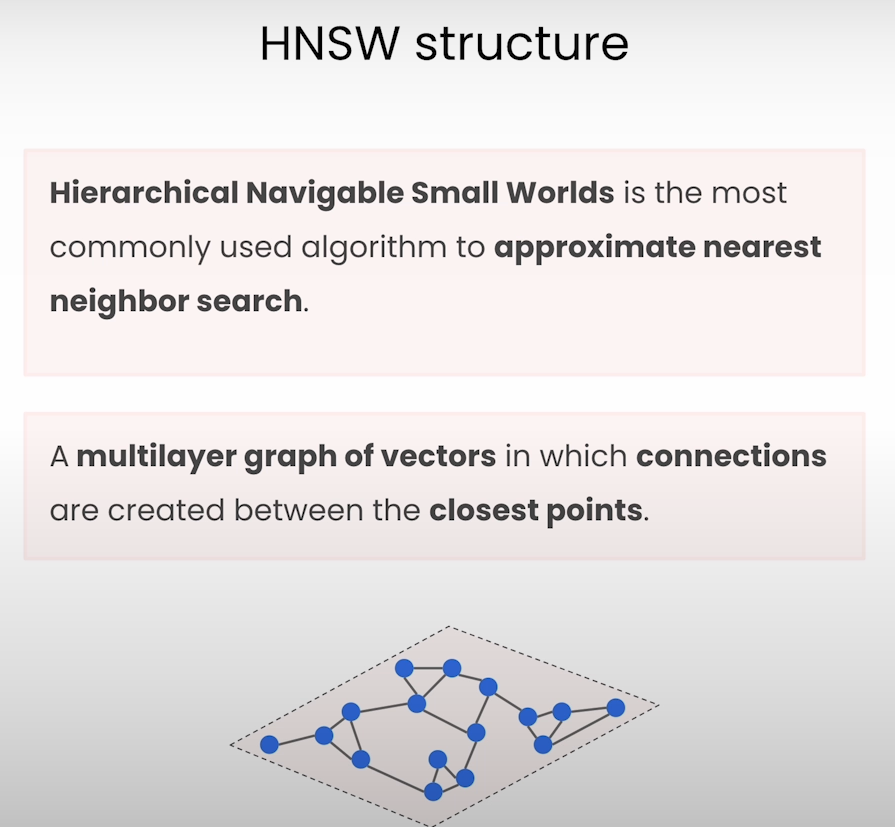
HNSW(Hierarchical Navigable Small World)的主要参数影响到其搜索精度、速度和内存使用。这些参数通常可以在构建索引和查询时进行调整,以适应不同的应用需求。以下是一些关键参数:
1. M(邻居数量)
• 作用:决定图中每个节点(向量)可以连接的最大邻居数量。
• 影响:较大的 M 值会增加图的密度,从而提升搜索的精度,但也会导致内存使用的增加和索引构建时间的上升。
• 推荐值:通常在 5 到 48 之间选择,常用值为 16。
2. efConstruction(构建时的搜索宽度)
• 作用:在构建图时用于搜索的宽度,控制候选邻居数量的上限。
• 影响:较大的 efConstruction 值通常可以提升索引质量,进而提高查询精度,但会增加索引构建时间。
• 推荐值:常用的取值在 100 到 200 之间。
3. ef(查询时的搜索宽度)
• 作用:控制查询时的搜索范围宽度,决定了搜索时的节点扩展范围。
• 影响:较大的 ef 值可以提高查询精度,但会增加查询时间。
• 推荐值:通常在 10 到 200 之间,取值越大精度越高,但速度较慢。对于精确性要求较高的查询,可以设置较大的 ef 值。
4. 层级最大高度(max level)
• 作用:HNSW 构建分层图时的最大层级深度。
• 影响:一般不需要手动设置,因为通常由节点数自动确定。如果手动调整,层级增加可以提高搜索速度,但会增加索引构建的复杂度和内存使用。
• 推荐设置:一般保持默认,由算法自动确定。
5. 索引的随机种子(random seed)
• 作用:HNSW 的随机性影响图的构建,这个参数决定了初始的随机种子。
• 影响:不同的种子会产生略微不同的索引结构。对于相同的数据和参数配置,不同的种子可能会导致轻微的搜索效果差异。
• 推荐设置:通常设置为固定值以确保可重复性。
参数调优建议:
• 精度优先:如果应用需要较高的查询精度,可以将 M、efConstruction 和 ef 设置较高。高 M 和 ef 可以增加图的连接性和查询覆盖面,从而提高找到真实最近邻的概率。
• 速度优先:如果应用对查询速度要求较高,可以适当降低 ef 和 efConstruction 值,同时选择适合的 M 值。这样可以减少查询时的计算量和索引构建时间。
• 内存优先:如果内存限制较大,可以选择较小的 M 值,以减少节点连接数量,但可能需要权衡搜索精度。
调整这些参数可以让 HNSW 在精度、速度和内存占用上找到平衡,以满足具体的应用需求。
Vector quantization
本节课程讲了可以使得向量搜索提高效率并且减少存储占用的方法。
可以采用量化的方法在牺牲少量搜索质量的情况下减少向量精度。
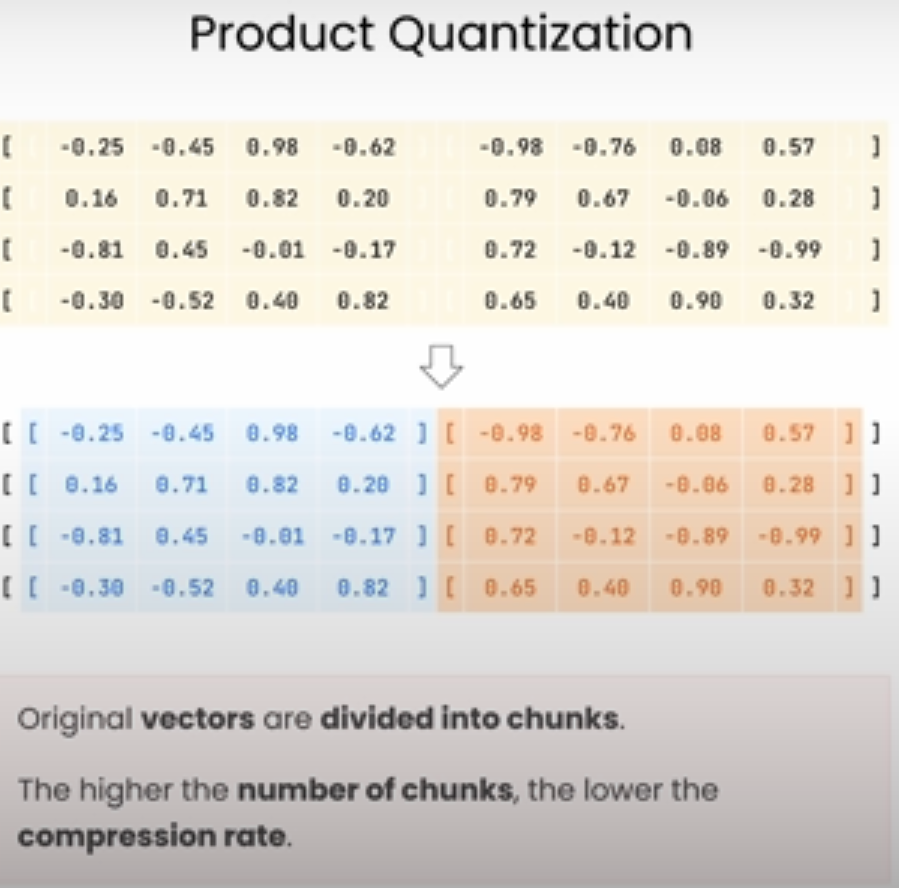
Product Quantization (PQ)
是一种用于加速高维向量相似性搜索的技术,通过将向量划分为多个子向量并对每个子向量进行量化,从而有效降低内存使用和计算成本。这种方法特别适用于大规模近似最近邻(Approximate Nearest Neighbor, ANN)搜索,是在处理图像特征、文本嵌入等高维数据时的常用方法。
基本原理
1. 向量分块:
• 将高维向量划分为多个低维子向量。比如,对于一个 128 维的向量,可以分成 4 个 32 维的子向量。
2. 子量化(Sub-Quantization):
• 为每个子向量独立地构建量化码本(codebook),即使用 k-means 聚类等算法,为每个子空间的向量找到其最佳代表中心。
• 通过这些中心点,计算每个子向量的量化表示,从而把一个高维向量转换成多个子空间的索引编码(而不是直接存储浮点数向量)。
3. 量化表示:
• 使用子量化后的索引来表示原向量。原始向量就变成了各个子空间的“离散”编码,每个编码对应一个量化中心的索引。
• 在查询时可以用“查表”的方式来近似计算原始向量之间的距离。
Product Quantization 的优点
• 存储效率:PQ 通过使用少量的量化码本索引代替浮点数存储,大幅降低了存储空间需求。
• 查询加速:由于向量之间的距离计算通过查找量化中心的距离来近似完成,可以显著加速计算。
• 精度与速度的平衡:PQ 在允许精度损失的前提下,能加快计算和减少存储成本,是一种精度与效率之间的折中。
应用场景
• 图像检索:在图像特征向量的检索中,PQ 可以有效加快搜索速度,使得在大规模图像库中找到相似图像成为可能。
• 推荐系统:推荐系统通常需要在高维空间中进行相似性搜索,通过 PQ 可以加速推荐候选的生成。
• 自然语言处理(NLP):用于加速词嵌入和句嵌入的近似检索,特别是在聊天机器人、问答系统中,通过 PQ 能提升实时性。
例子
让我们来看一个使用 Product Quantization (PQ) 进行近似最近邻搜索的例子,假设我们有一个包含许多电影描述向量的大数据库,我们想通过 PQ 来找到和某个新电影描述最相似的电影。
场景说明
• 数据库中有 1 百万部电影,每部电影的描述向量是 128 维。
• 假设用户上传了一个新的电影描述,我们将其向量化,并想找到与之最相似的电影描述。
实现步骤
1. 将向量划分成子向量:
• 首先,将 128 维向量分成 4 个子向量,每个子向量为 32 维。
• 假设对于第 1 部电影描述,向量为 [v1, v2, v3, ..., v128]。我们把它分成 4 部分,比如 [v1...v32], [v33...v64], [v65...v96], [v97...v128]。
2. 对每个子向量进行量化:
• 对每个子向量部分,使用 k-means 聚类来创建一个量化码本。假设每个码本有 256 个中心点,每个中心点表示一个可能的“量化值”。
• 对于第一个子向量 [v1...v32],找到最接近的码本中心点,然后用该中心点的索引来代替这个子向量部分。
• 重复该过程,将 128 维的原始向量转换为 4 个量化索引,例如 [7, 3, 250, 44],表示每个子向量最接近的码本中心点的索引。
3. 存储量化表示:
• 把所有电影描述向量都以类似 [7, 3, 250, 44] 的量化索引方式存储,而不是保存原始的 128 维向量。这大幅降低了存储空间。
4. 查询时的相似性搜索:
• 用户上传了一部新电影描述,将其向量化为 128 维向量,然后分成 4 个 32 维的子向量。
• 对新电影描述的每个子向量查找最接近的码本中心点,得到一个类似 [6, 2, 245, 42] 的量化索引。
• 通过查找数据库中与这个量化索引最接近的索引组合,即可找到最相似的电影。
• 相似性计算通过查表方式来完成,快速找到量化索引相近的电影描述,而不需要直接在高维空间中计算距离。
总结
通过 Product Quantization,将每部电影的 128 维描述向量转换为几个量化索引,实现了在大数据量下的近似查询。相比于直接存储和计算 128 维浮点数,这种方法存储更高效,查询速度也快得多,非常适合大规模数据的相似性搜索。

Product Quantization
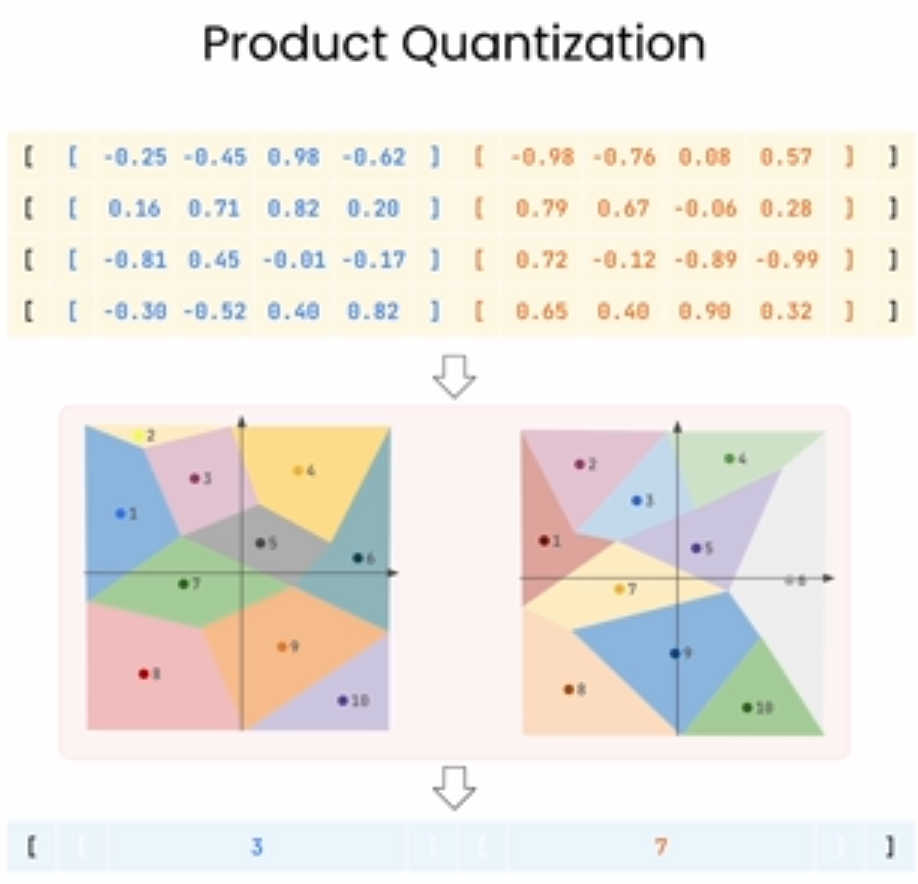
下图则是对列同时也做了量化,为了找到某个聚类的中心点。
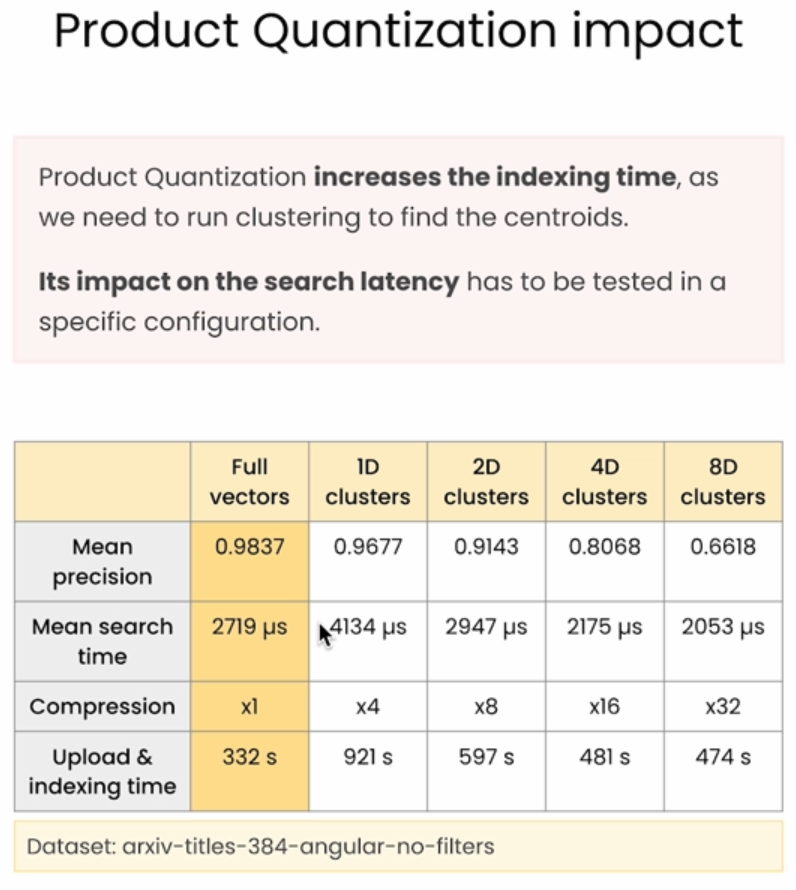
影响
图表展示了 Product Quantization (PQ) 对索引时间、搜索精度、搜索时间和压缩率的影响。以下是各个指标的总结:
1. Mean Precision(平均精度):
• 随着聚类维度增加,平均精度下降。
• 原始向量(Full vectors)具有最高的精度 0.9837,而 8D 聚类的精度降到 0.6618。
• 这说明在 PQ 中,增加压缩会导致精度的损失,因为每个向量的近似度下降。
2. Mean Search Time(平均搜索时间):
• 搜索时间随着聚类维度的增加而减少。
• 原始向量的平均搜索时间为 2719 微秒,1D 聚类增加到了 4134 微秒,但从 2D 开始,搜索时间逐渐降低,到 8D 聚类时降到 2053 微秒。
• 这是因为较高的压缩率可以减少计算量,但初始的 1D 聚类增加了搜索负担,导致搜索时间略增。
3. Compression(压缩率):
• 压缩率随着聚类维度的增加而显著提升。
• 原始向量的压缩率为 x1,而 8D 聚类达到了 x32。
• 这表示使用更多的子空间可以大幅减少存储需求,使 PQ 适用于大规模数据集。
4. Upload & Indexing Time(上传和索引时间):
• 随着聚类维度增加,索引时间逐渐减少。
• 原始向量索引时间为 332 秒,1D 聚类索引时间较高,为 921 秒。随着聚类维度增加到 8D,索引时间降到 474 秒。
• 这表明构建低维的量化码本在初始阶段较为耗时,但更高的压缩比会降低索引时间和存储成本。
总结
• 精度:原始向量精度最高,随着聚类维度增加,精度下降。
• 搜索时间:1D 聚类的搜索时间较慢,但从 2D 开始搜索时间逐渐减少。
• 压缩率:聚类维度越高,压缩率越高,存储效率越高。
• 索引时间:低维度的聚类索引时间较高,但聚类维度增加后索引时间下降。
这表明 Product Quantization 可以在搜索速度、精度和存储效率之间找到平衡,但需要根据具体需求来选择合适的聚类维度。
下面提出了一种可以恢复精度的方式,通过原本量化后的向量找到原本同一类的文本向量,然后逐一比较。

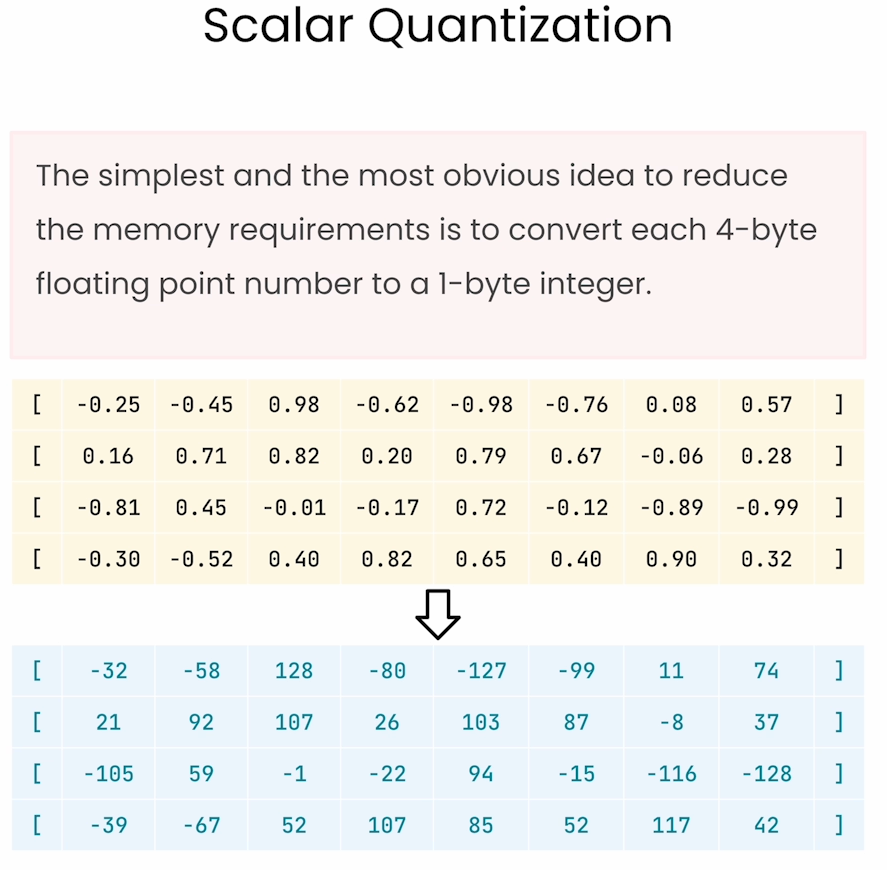
Scalar Quantization
Scalar Quantization 是一种简单的量化方法,通过将连续的数值数据映射到一组有限的离散值中,以达到数据压缩或加速计算的目的。在量化过程中,原始的浮点数值被替换为一个离散的整数值,表示最接近的量化级别。
基本原理
1. 定义量化级别(Quantization Levels):
• 将连续的数值范围划分为多个区间,每个区间代表一个离散的量化级别。例如,将数值范围 [-1, 1] 划分成 8 个区间,分别用离散值 q1, q2, ..., q8 表示。
2. 量化过程:
• 对每个输入数据,找到它所属的区间,将该数据替换为对应的量化级别。
• 例如,假设有一个输入值 0.25,如果它位于区间 q4,就将它替换为该区间的量化值 q4,从而实现数据的压缩或离散化。
3. 去量化(可选):
• 在需要还原数据时,可以使用每个量化级别的中心值来近似原始数据。这样可以保留部分原始数据的特性,但会带来一定的信息损失。
Scalar Quantization 的应用场景
• 数据压缩:在图像、音频等信号处理领域,通过量化来减少数据表示所需的存储空间。
• 加速计算:在神经网络推理和向量搜索中,通过量化可以减少计算复杂度,加速模型运行。
• 信号传输:在通信系统中,量化用于将连续信号转换为离散信号,以便在数字系统中传输。
例子
假设有一组浮点数 [0.12, 0.54, -0.33, 0.76],我们希望对它们进行量化,将范围 [-1, 1] 分成 4 个区间,分别是 [-1, -0.5]、[-0.5, 0]、[0, 0.5]、[0.5, 1],量化值为 q1, q2, q3, q4。
• 0.12 在区间 [0, 0.5],量化值为 q3
• 0.54 在区间 [0.5, 1],量化值为 q4
• -0.33 在区间 [-0.5, 0],量化值为 q2
• 0.76 在区间 [0.5, 1],量化值为 q4
最终得到量化后的结果是 [q3, q4, q2, q4]。
影响
• 优点:实现简单,计算开销小,适合用于低复杂度和实时处理的场景。
• 缺点:量化误差较大,容易丢失信息,尤其在高精度要求的应用中,可能不如更复杂的量化方法(如 Product Quantization 或 Vector Quantization)。
总结
Scalar Quantization 是一种基础的量化技术,通过将连续值映射到有限的离散值来实现数据压缩或加速计算。它在不需要高精度的场景中应用广泛,如信号处理、简单的机器学习模型等。

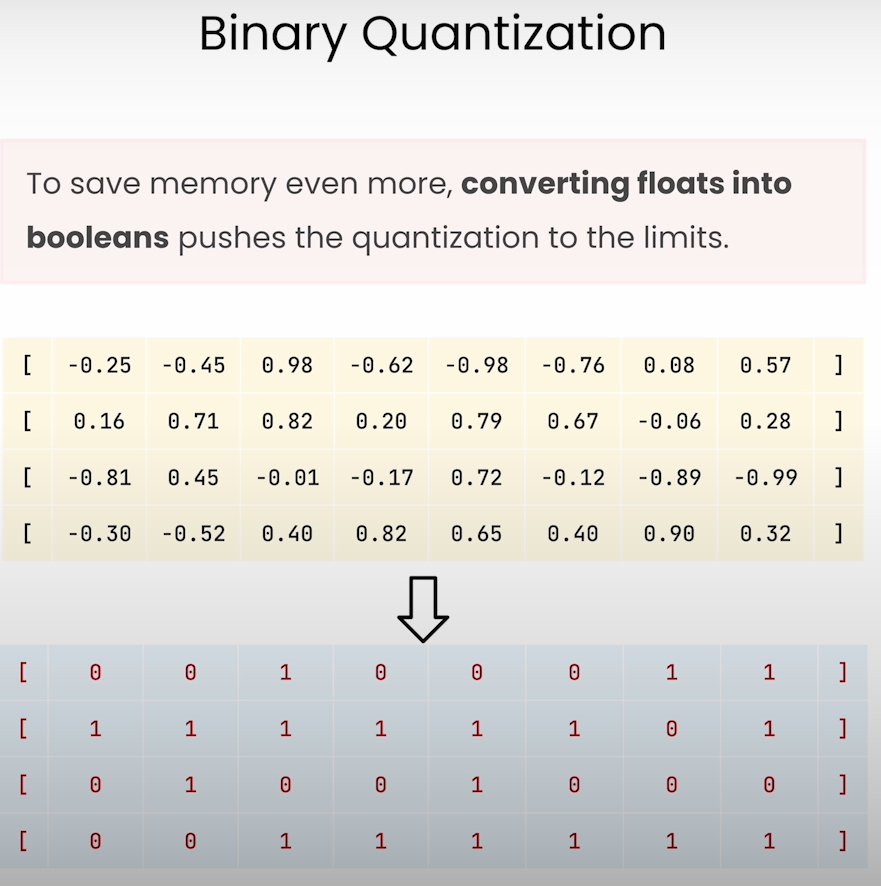
Binary Quantization