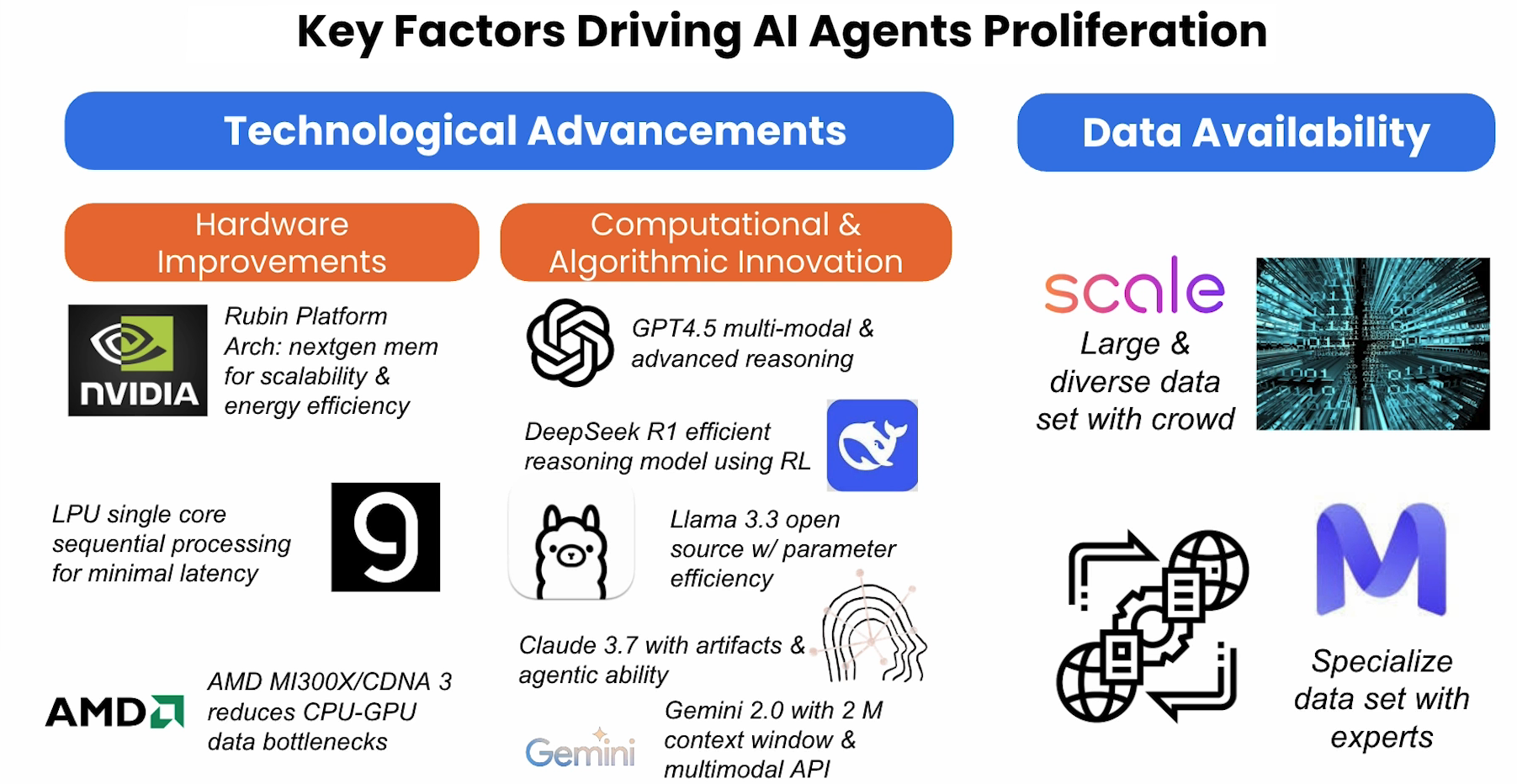
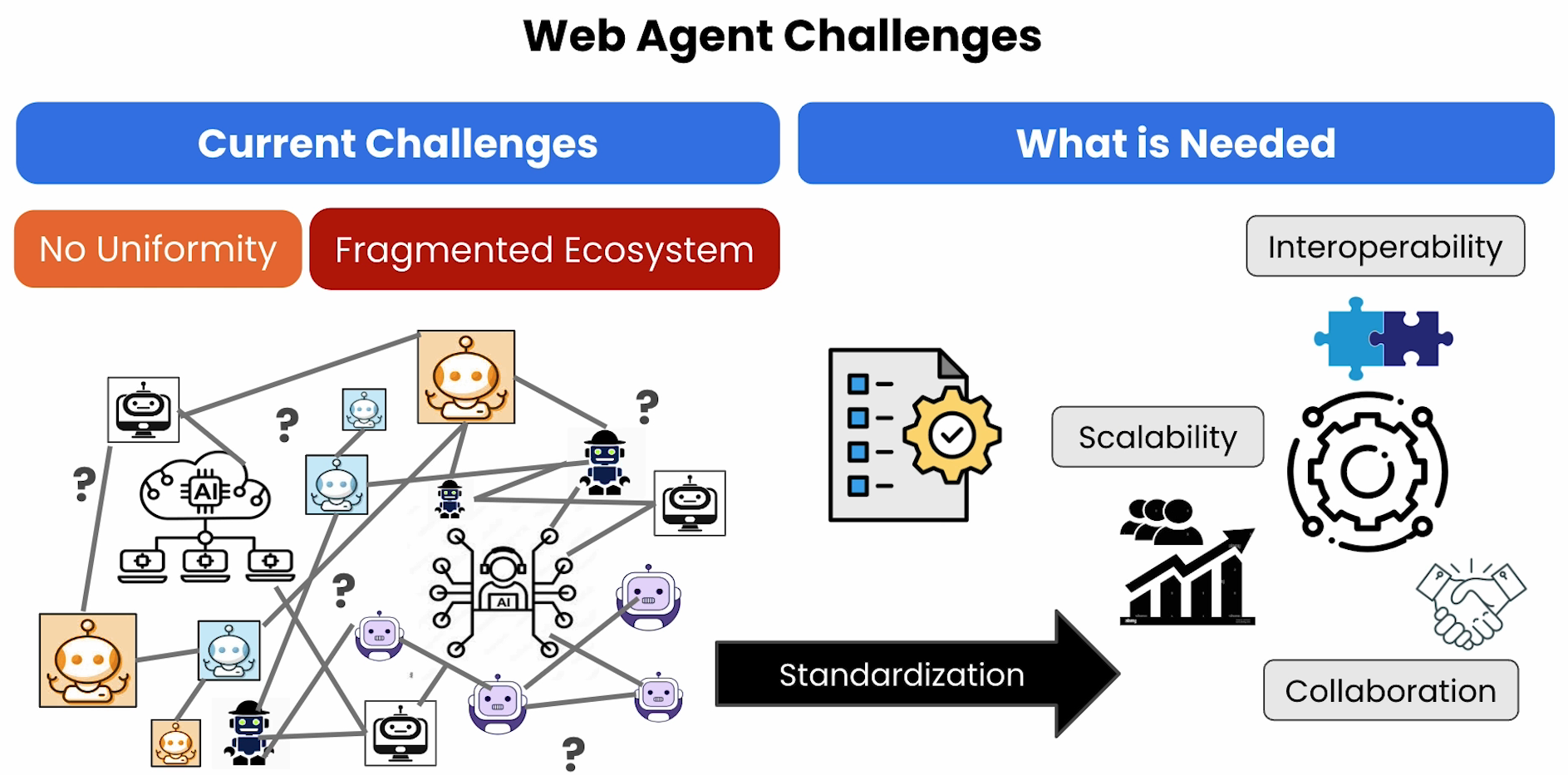
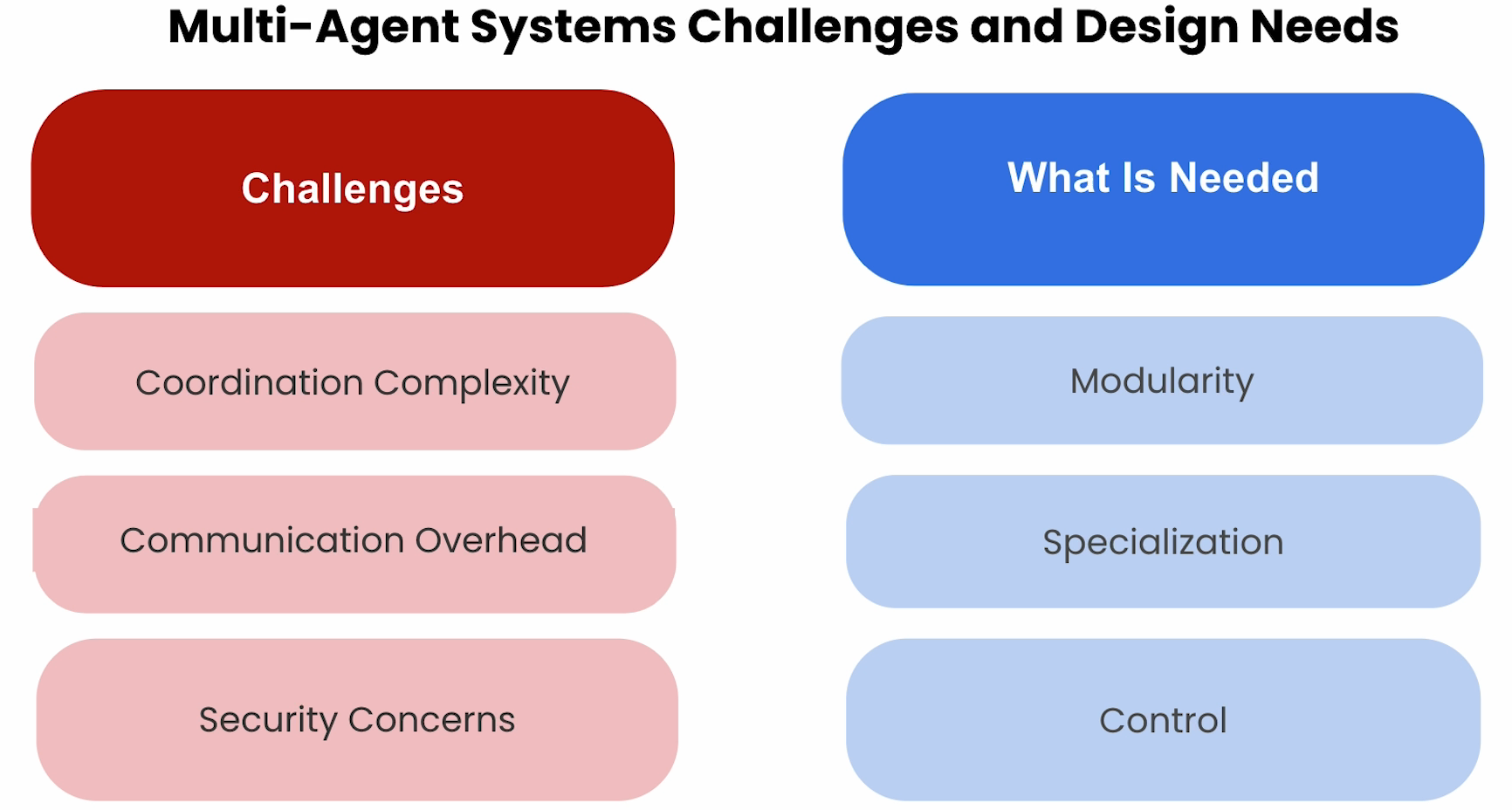
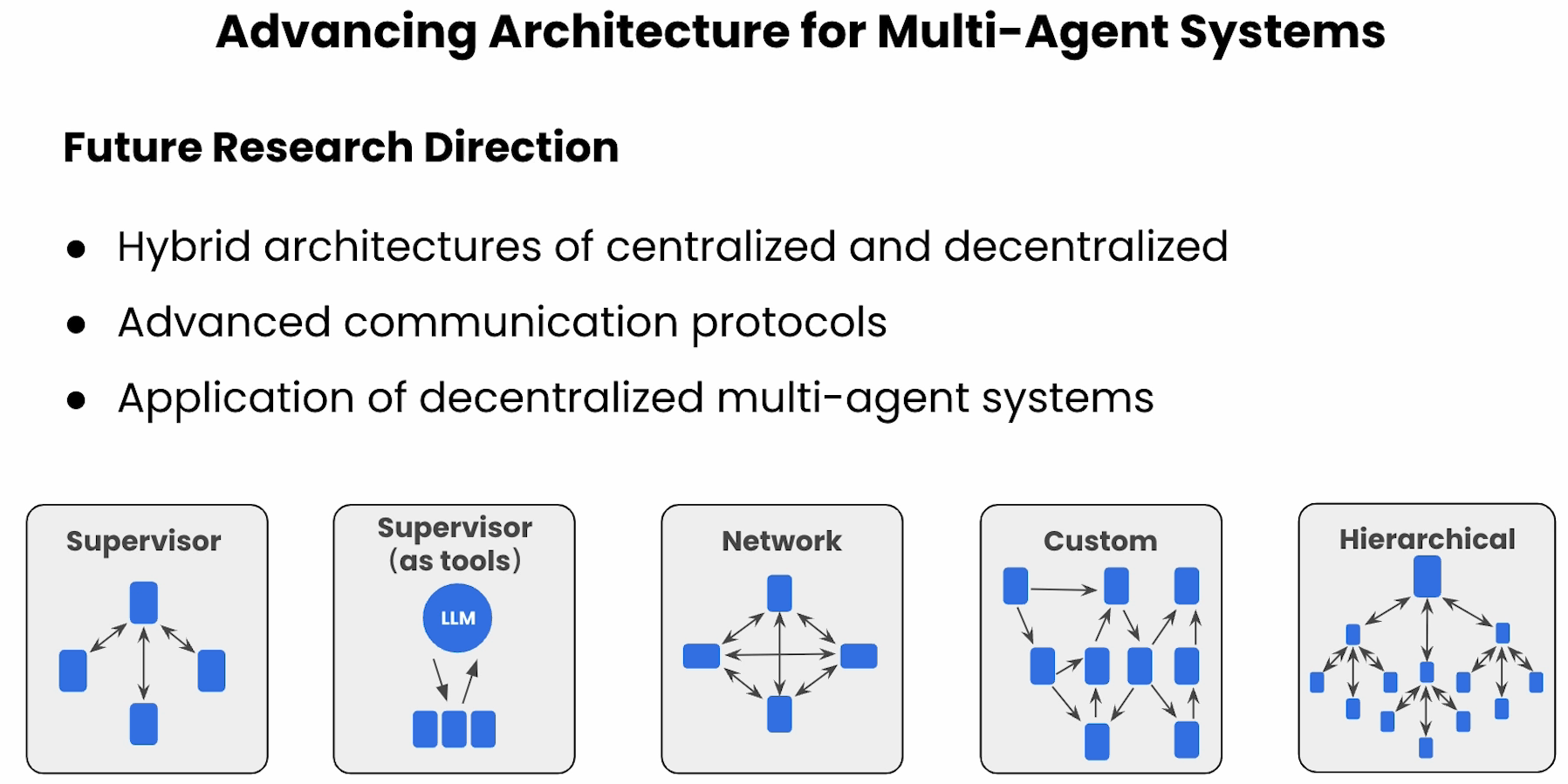
Introduction
本课程是由MultiOn带来的关于web agent的课程,操作web浏览器进行自动化网页浏览。
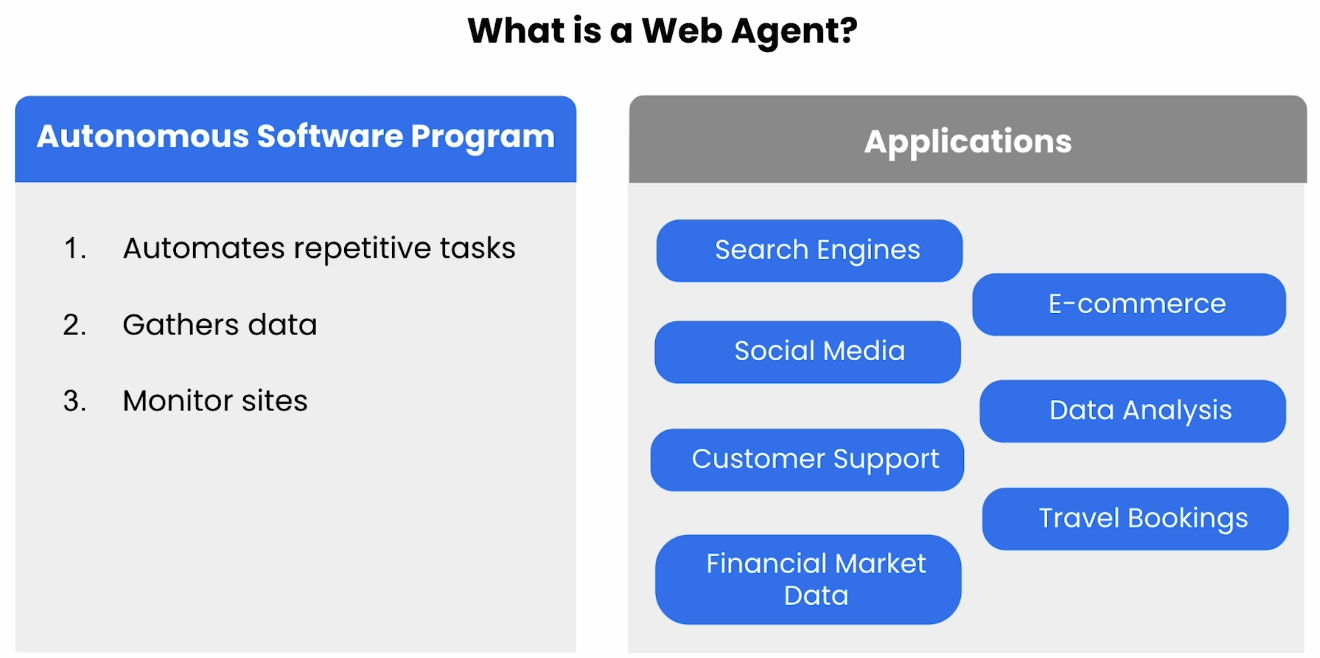
Intro to Web Agents
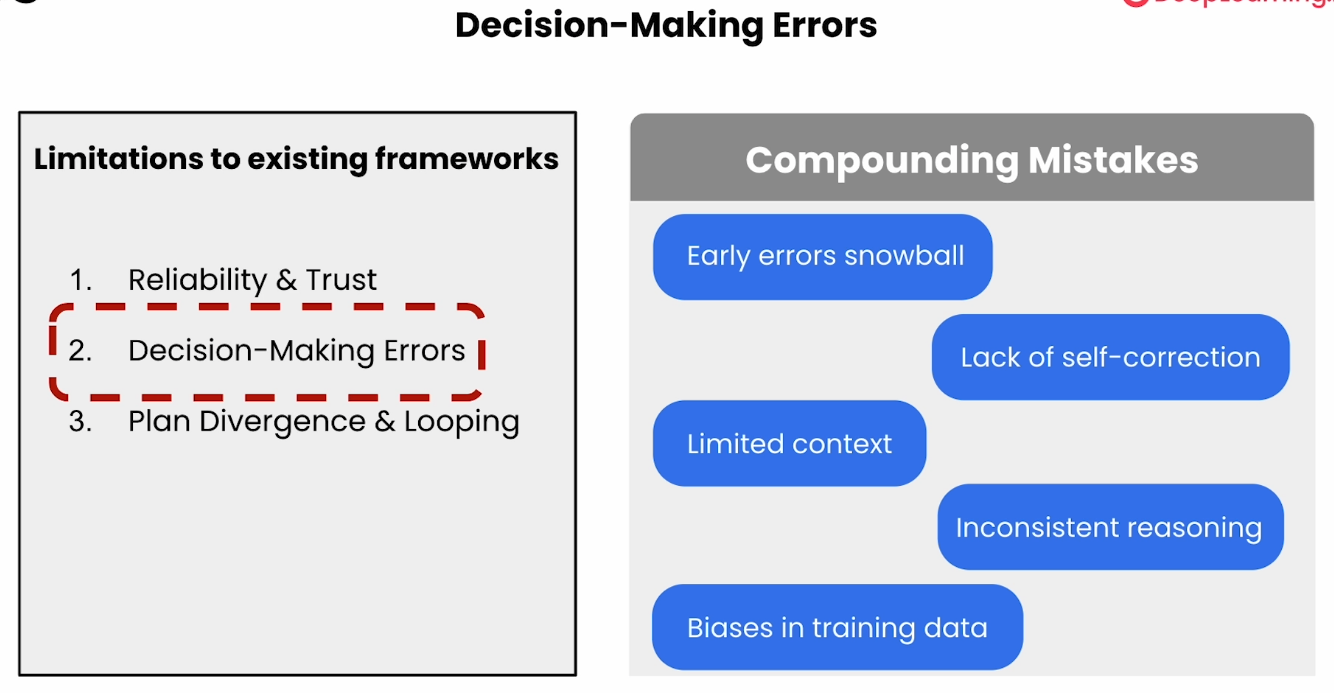
在本节举了个利用Agent自动购物的例子,并主要讲了一些挑战:1 稳定性 2 错误处理 3 agents 死循环


Challenges
Reliabilitiy and Trust
因为整个过程是复杂的,且必须要获得用户的权限与信任,有安全风险。
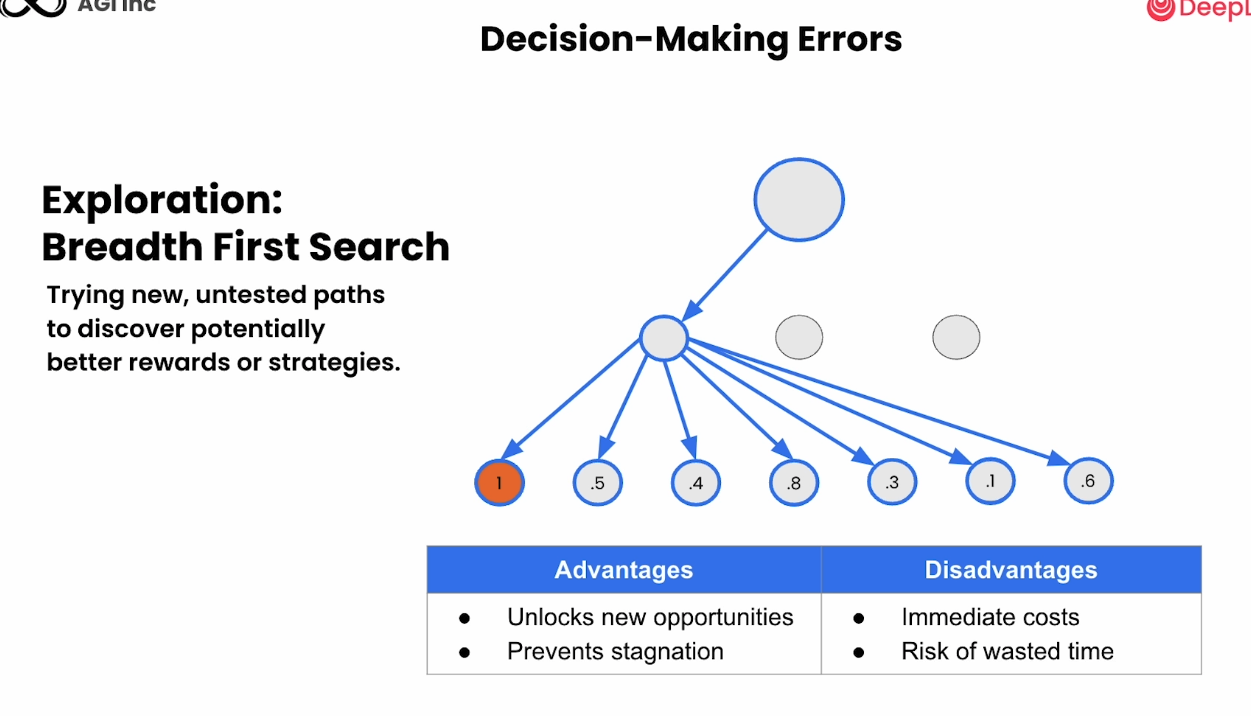
Decision-Making Errors
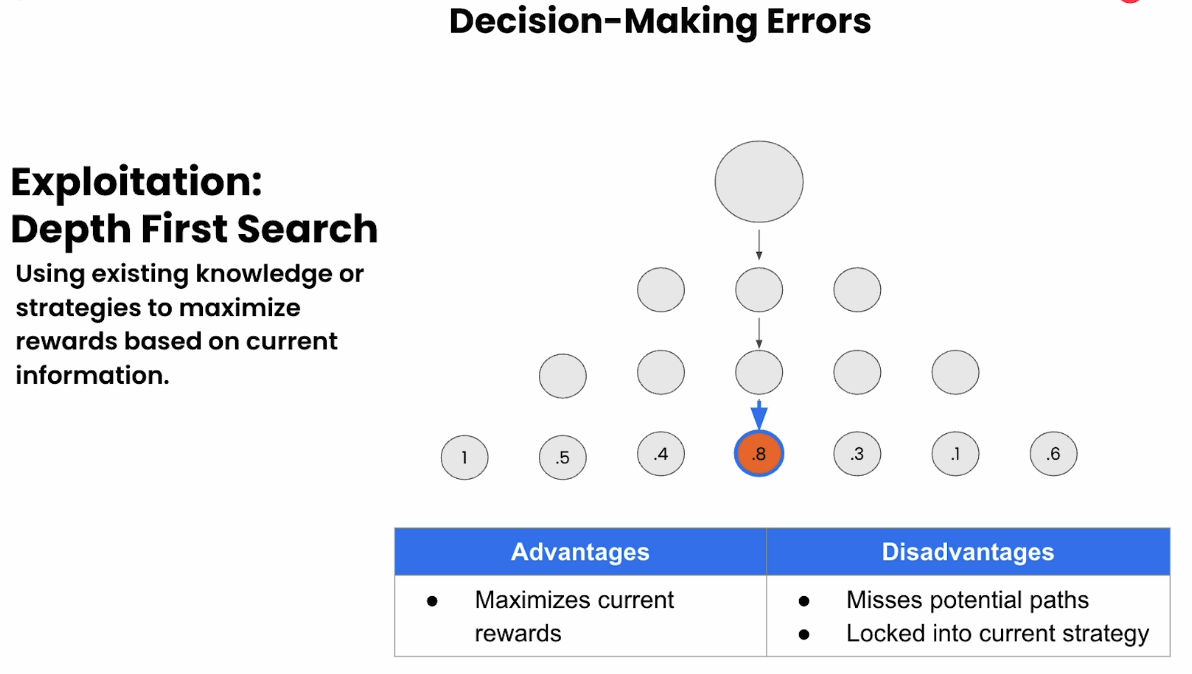
深度优先搜索
广度优先搜索
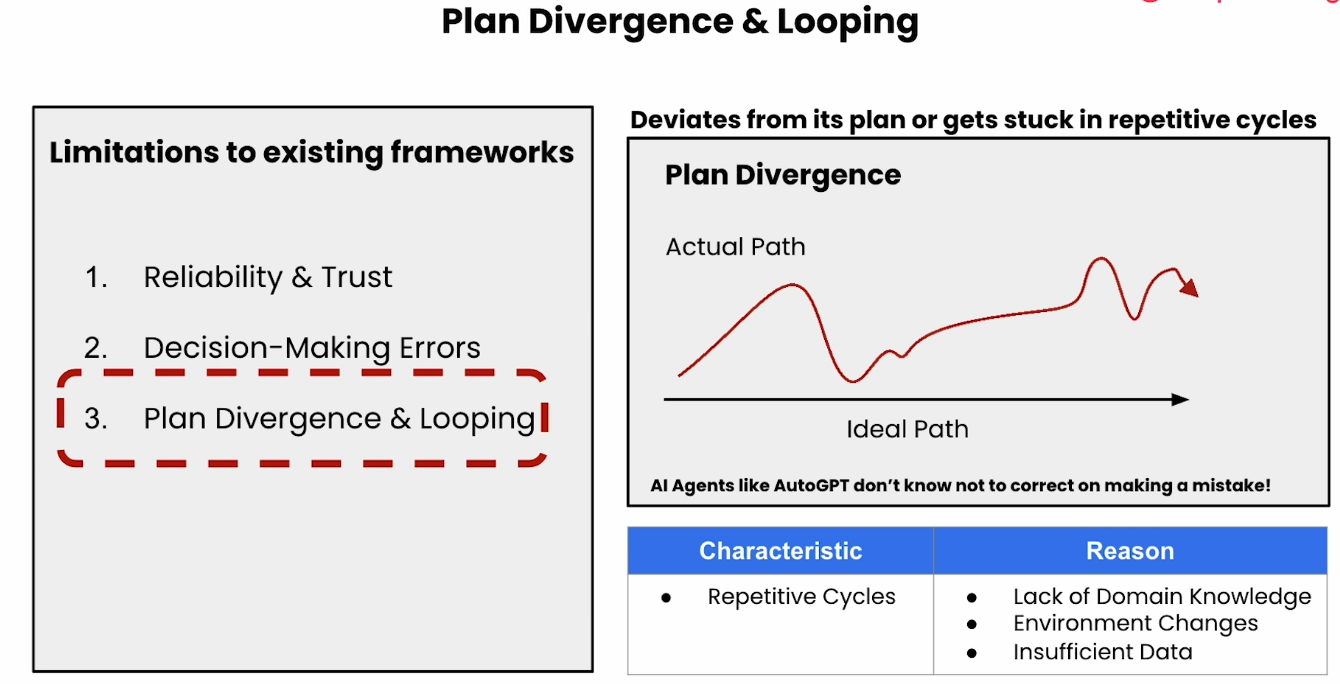
Plan Divergence & Looping
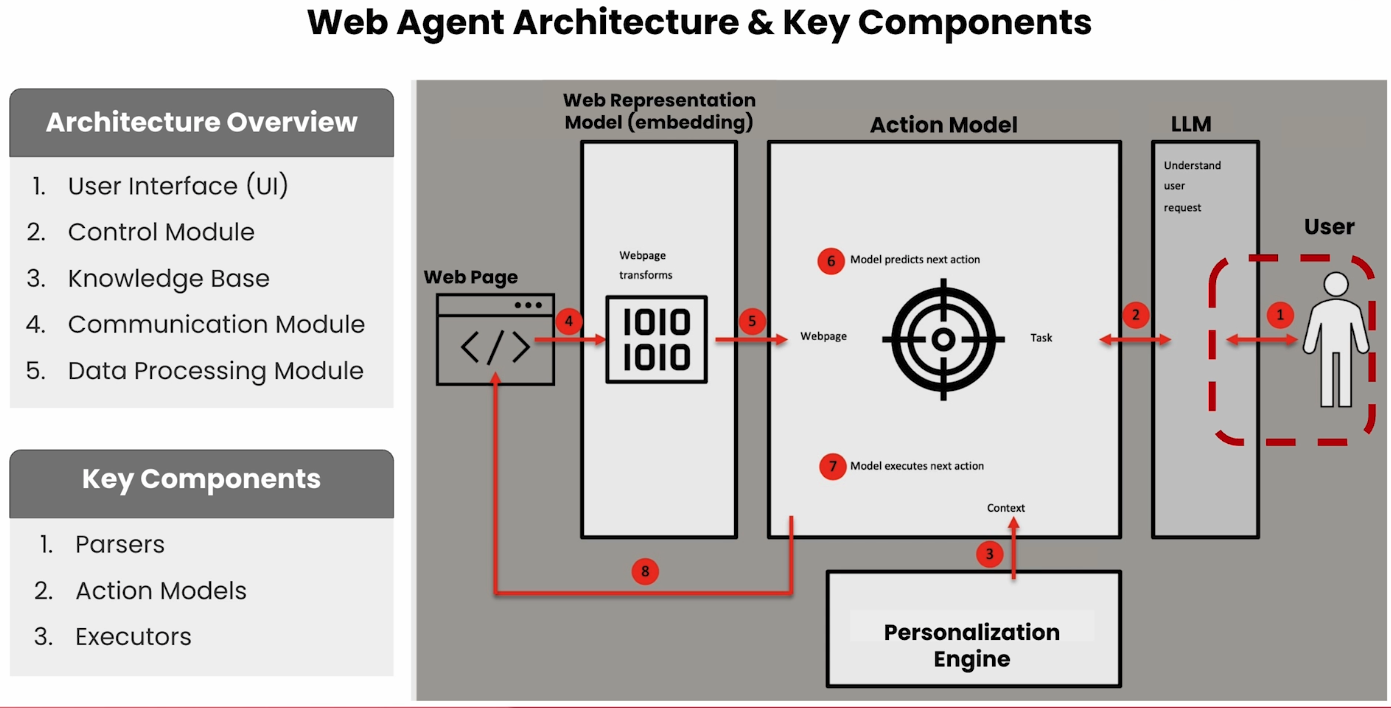
 Building a Simple Web Agent
Building a Simple Web Agent
Building an Autonomous Web Agent
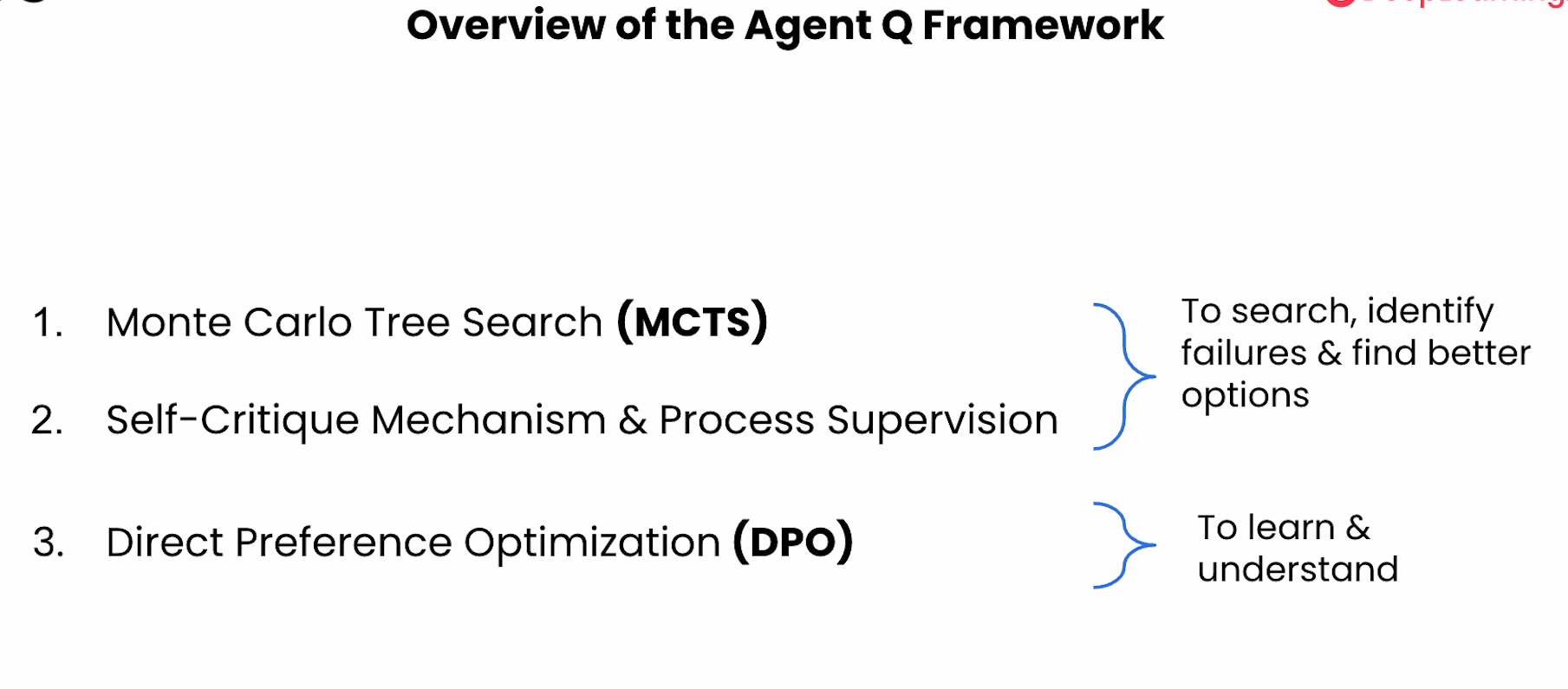
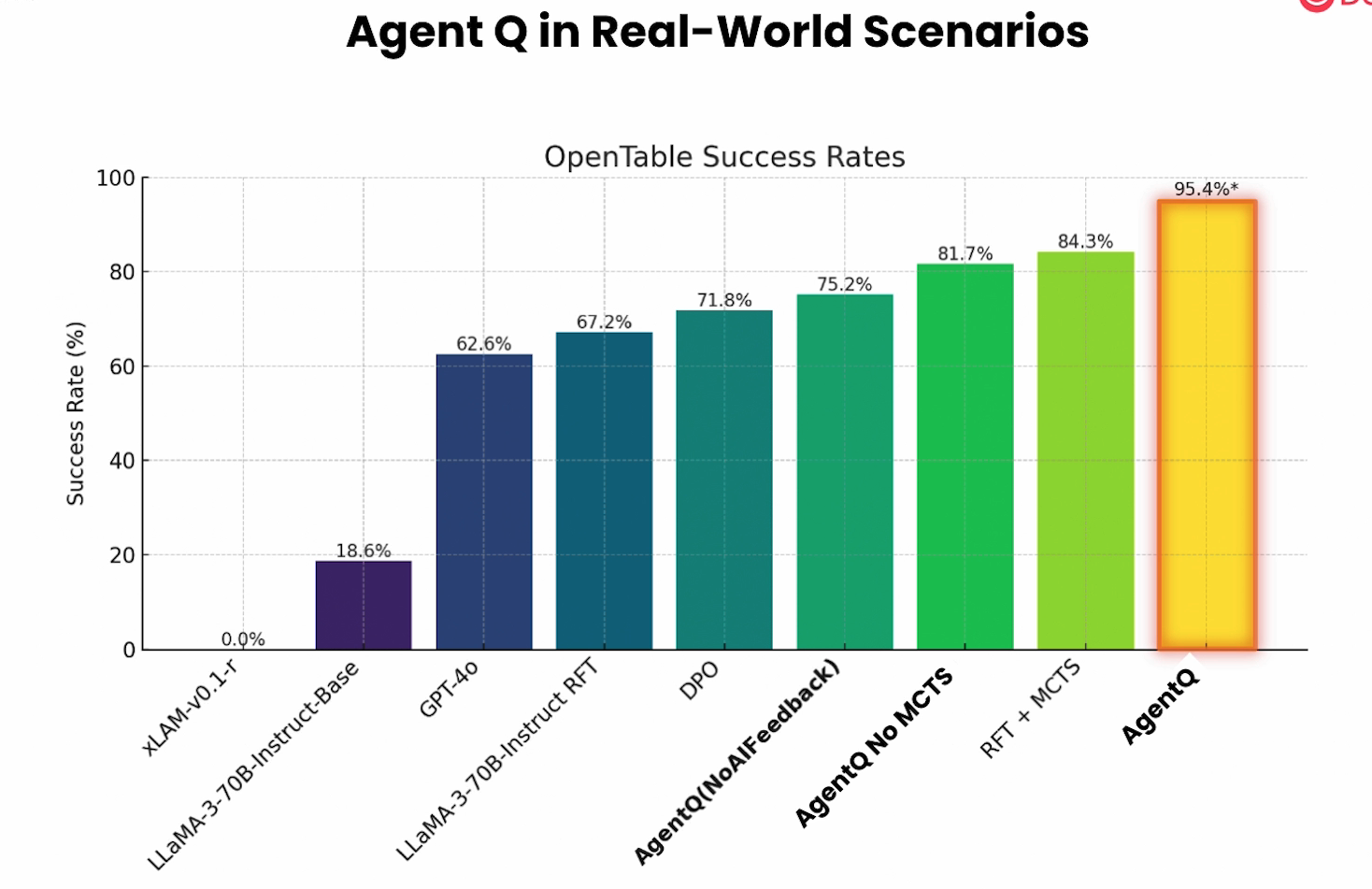
AgentQ

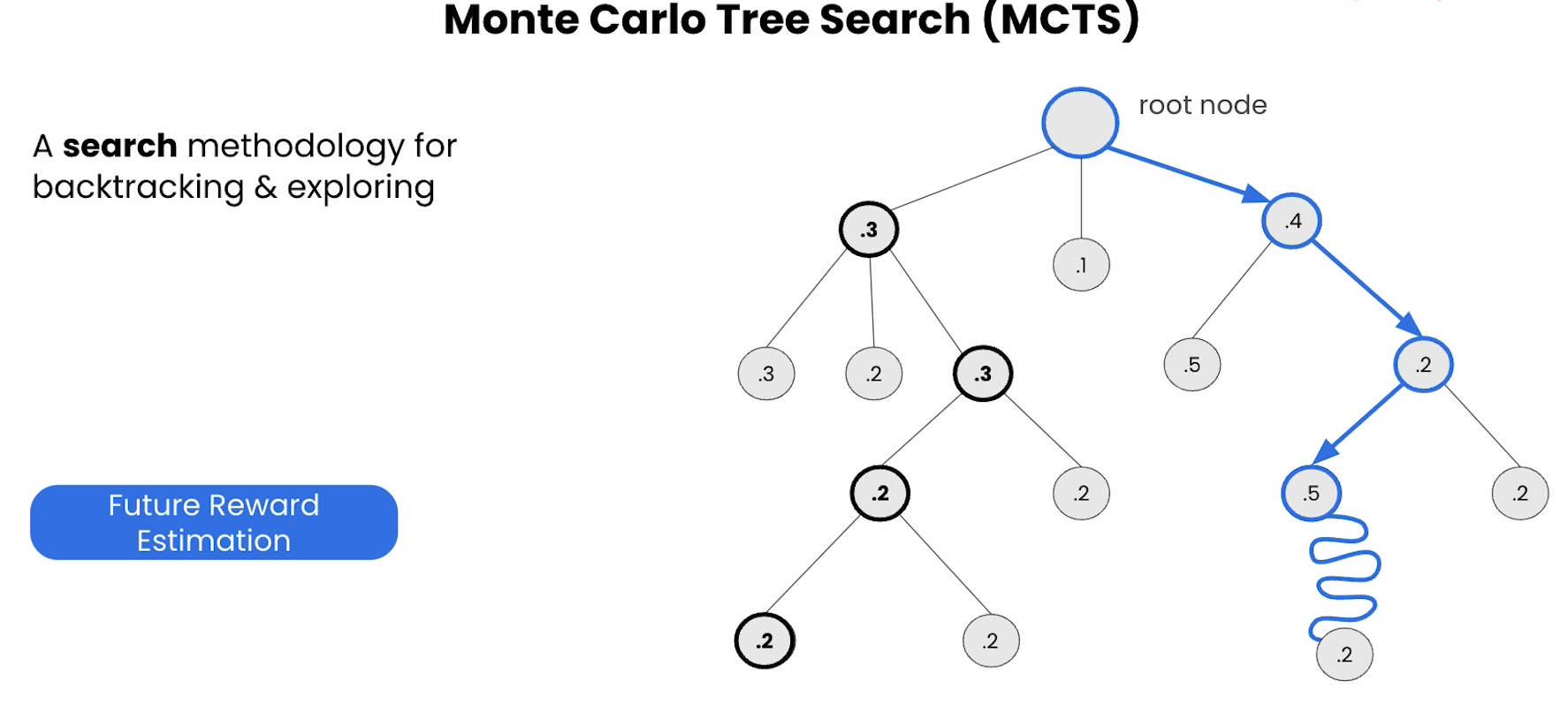
MCTS
蒙特卡洛树搜索(Monte Carlo Tree Search,简称MCTS)是一种用于决策过程中的启发式搜索算法,特别适用于搜索空间巨大且对手信息不完全的情况。MCTS在各种游戏AI(如围棋、国际象棋、棋牌游戏等)和强化学习中得到广泛应用。它结合了随机采样和树搜索的优点,能够在有限的时间内有效探索决策空间,从而找到近似最优解。
---
## 一、MCTS基本概念
MCTS通过构建一个搜索树,对决策过程进行反复模拟,然后根据模拟结果调整树的结构和选择策略。其核心思想是通过大量随机模拟来评估每个动作的潜在价值,从而逐步逼近最优策略。
---
## 二、MCTS的基本流程
MCTS由四个主要步骤组成,迭代执行直到满足停止条件(如计算时间、模拟次数等):
1. 选择(Selection)
从根节点开始,根据某种策略(通常是UCB1公式)沿着树向下选择子节点,直到达到尚未完全展开的节点或叶子节点。选择策略旨在平衡**探索**(尝试不常访问的节点)与**利用**(选择历史表现好的节点)之间的权衡。
2. 扩展(Expansion)
如果所选择的节点不是终止状态,则从该节点扩展一个或多个新的子节点,代表从当前状态可采取的具体动作。
3. 模拟(Simulation)
从新扩展的节点开始,随机(或利用简单策略)模拟走完后续决策过程,直到达到游戏终结(胜负、平局等)或深度限制。模拟的结果将反映当前节点的潜在价值。
4. 回传(Backpropagation)
将模拟结果更新回路径上的所有节点,调整对应节点的访问次数和累积奖励值,从而影响未来的选择决策。
---
## 三、MCTS的核心技术
### 1. 选择策略——UCB1公式
最常用的选择策略是UCB1(Upper Confidence Bound 1),定义为:
\[
UCB1 = \frac{w_i}{n_i} + c \sqrt{\frac{\ln N}{n_i}}
\]
- \( w_i \):节点i的累计获胜次数(或奖励)
- \( n_i \):节点i被访问的次数
- \( N \):父节点被访问的次数
- \( c \):探索参数,控制探索与利用的平衡
其中第一项表示平均收益(利用),第二项表示不确定性(探索)。通过选择UCB1值最大的节点,MCTS能够有效兼顾开拓新策略和利用已有策略。
### 2. 模拟策略
模拟阶段通常采用纯随机走子,也可以结合启发式规则提高效果。模拟策略的质量直接影响MCTS的性能。
### 3. 节点扩展策略
扩展新节点时,可以选择一次扩展一个动作,也可以同时扩展多个动作,根据具体应用调整。
---
## 四、MCTS的优缺点
### 优点
- 不需要全面的游戏规则或评估函数,仅通过模拟和统计即可
- 可在有限时间内动态调整搜索策略,适应复杂环境
- 应用广泛,特别适合具有巨大状态空间和不确定性的决策问题
### 缺点
- 对模拟策略和次数较敏感,模拟质量直接影响效果
- 在某些确定性且状态空间有限的环境下效率不一定优于传统搜索
- 计算资源需求大,尤其是在高复杂性任务中
---
## 五、MCTS的应用实例
- 围棋AI:AlphaGo将MCTS与深度神经网络相结合,极大提升了围棋AI水平
- 棋牌游戏:国际象棋、将棋等在搜索对策方面使用MCTS
- 一般决策问题:机器人路径规划、自动控制、多智能体系统
---
## 六、总结
蒙特卡洛树搜索是近年来游戏AI和强化学习领域的重要算法,通过不断采样和更新策略,实现了在复杂决策空间中的高效搜索。其理论基础扎实,实践效果显著,是当前AI研究的基础工具之一。
---
如果你需要,我可以进一步为你详细讲解MCTS的数学原理、代码实现示例或者在某个具体领域的应用情况。
LLM Critique
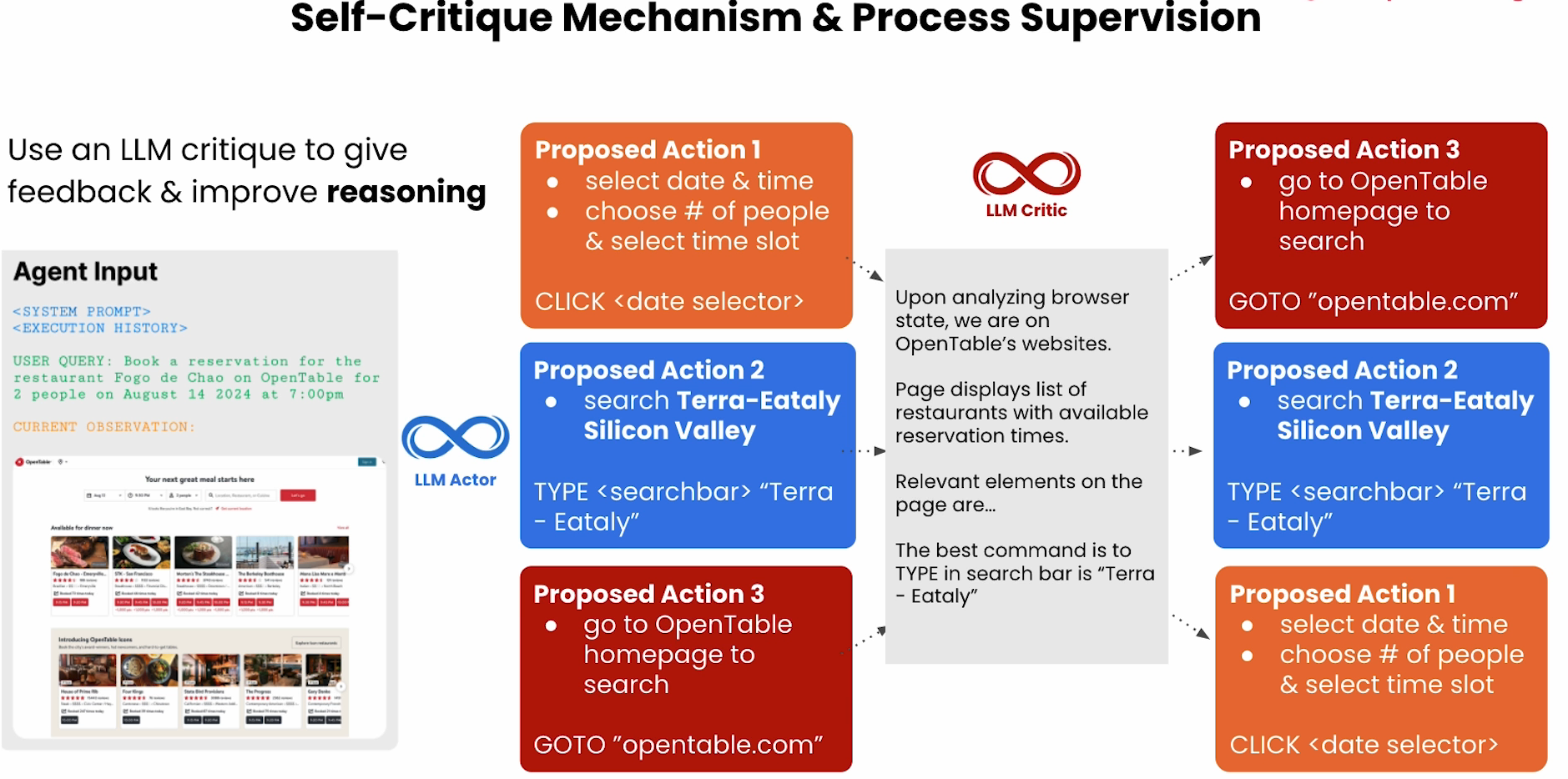
这张图讲述了“大模型自我批判机制与流程监督”(Self-Critique Mechanism & Process Supervision)的流程,目的是让大语言模型(LLM)自己评估自己的推理步骤并优化反馈。
具体内容包括:
1. Agent Input(左侧)
- 输入包括系统提示、执行历史和用户查询(例如用户希望在OpenTable预定餐厅)。
- 下方有当前浏览器页面的截图,反映OpenTable的实际页面状态。
2. LLM Actor(中间)
- LLM Actor根据当前观测和任务,提出可能的下一步操作(Proposed Actions),如点击日期选择器、在搜索栏输入餐厅名或回到OpenTable首页等。
3. LLM Critic(右上)
- 旁边的LLM Critic对这些建议的操作进行分析,评判哪些操作最合适,并提供推理理由。
- 例如,LLM Critic会分析页面状态、可用的操作项,然后建议“在搜索栏输入‘Terra - Eataly’”作为最优命令。
4. 总结
- 该流程利用LLM自我反馈能力,对提出的行动方案进行评判和改进,从而优化推理过程。
- 图左侧说明“利用LLM自我批判,提高推理能力”。
要点总结:
- 输入用户任务和页面状态,LLM Actor提出多个备选动作。
- LLM Critic结合页面结构等信息,批判性评估动作,建议最优方案。
- 注重自我反馈和推理能力提升。
这张图展示了一种利用大模型自身监督和反馈增强决策流程的智能Agent设计方式。
DPO
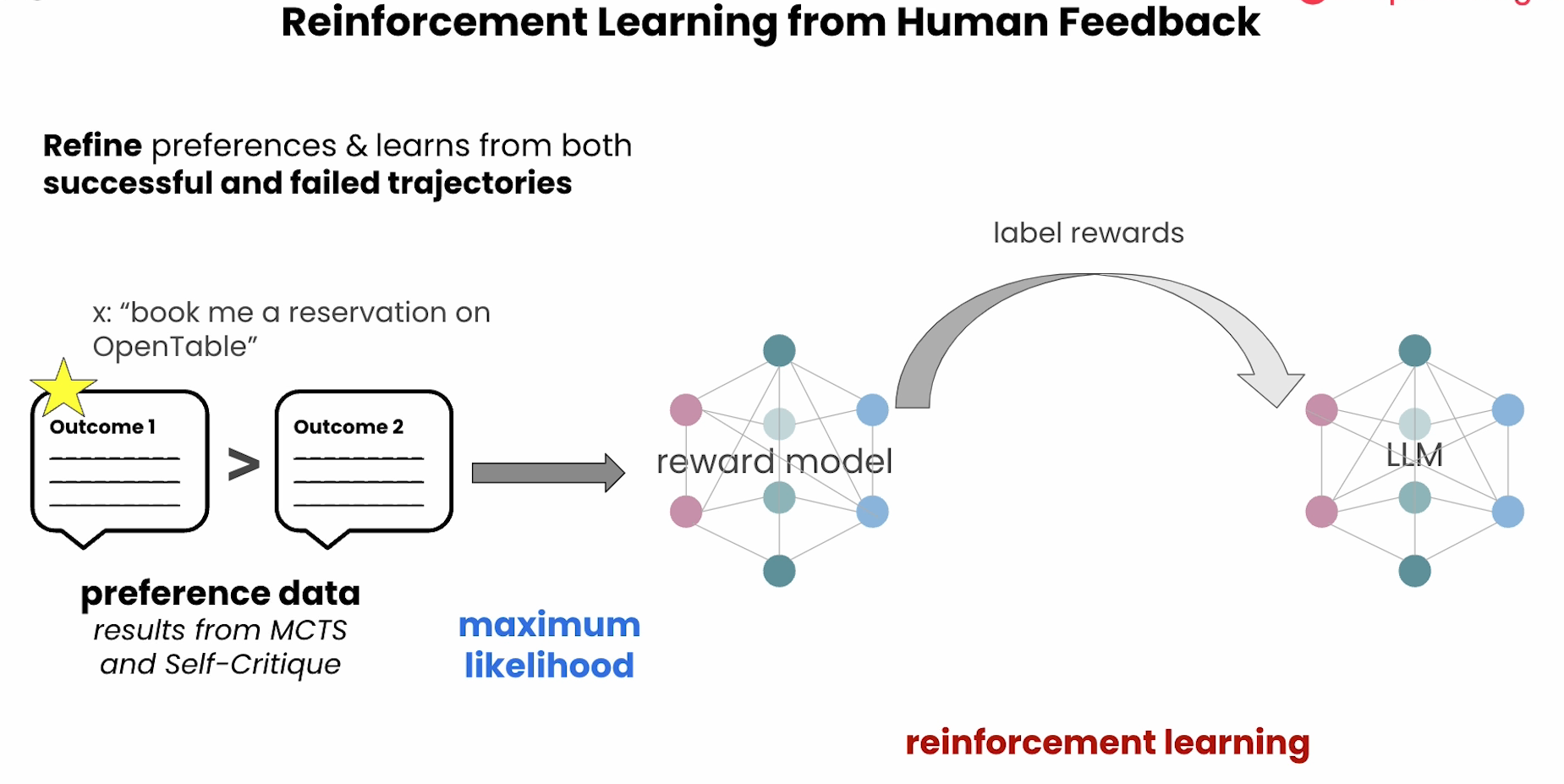
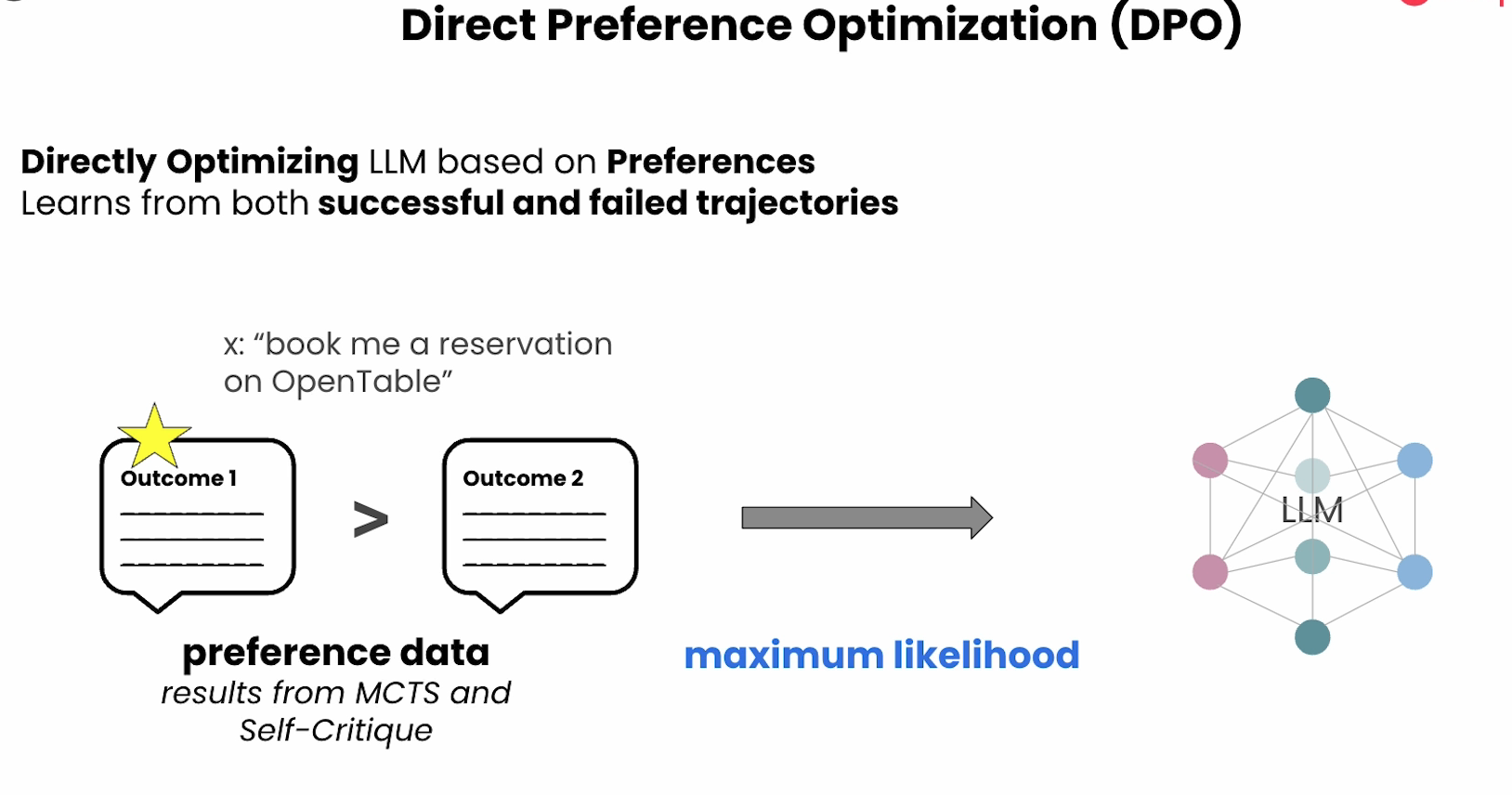
Deep Dive into AgentQ and MCTS

Future of AI Agents