github链接:https://github.com/MSzgy/Reinforcement-Learning-From-Human-Feedback
Introduction
本课程讲解了RLHF,并用此对llama2 model进行微调。
How does RLHF work
拿一个summary task举例,比如下面两个summary,现在问题是这两个summary输出,哪个会更好?

与SFT(监督微调)不同的是,采用RLHF将会利用强化学习去判断。

下面是整个训练的过程:
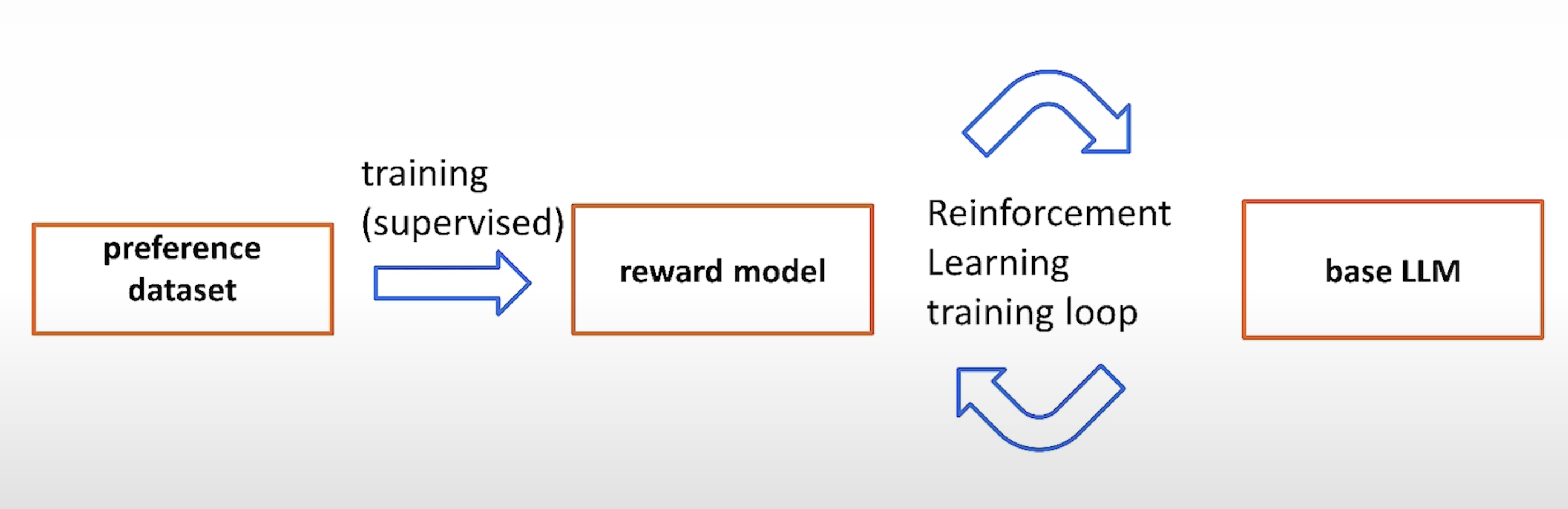
dataset

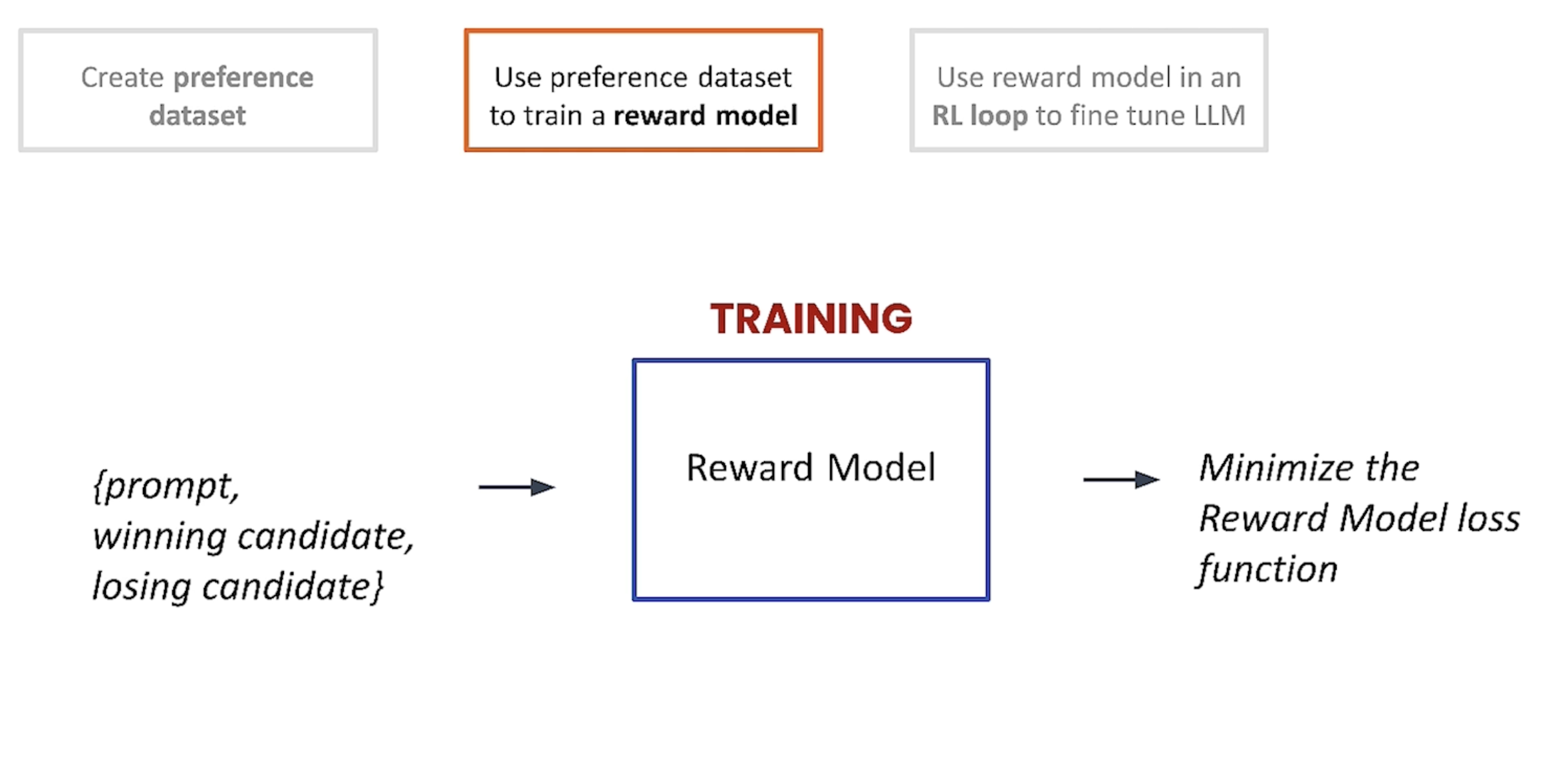
reward model
将{prompt, good summary, bad summary} 作为输入去训练一个reward model。
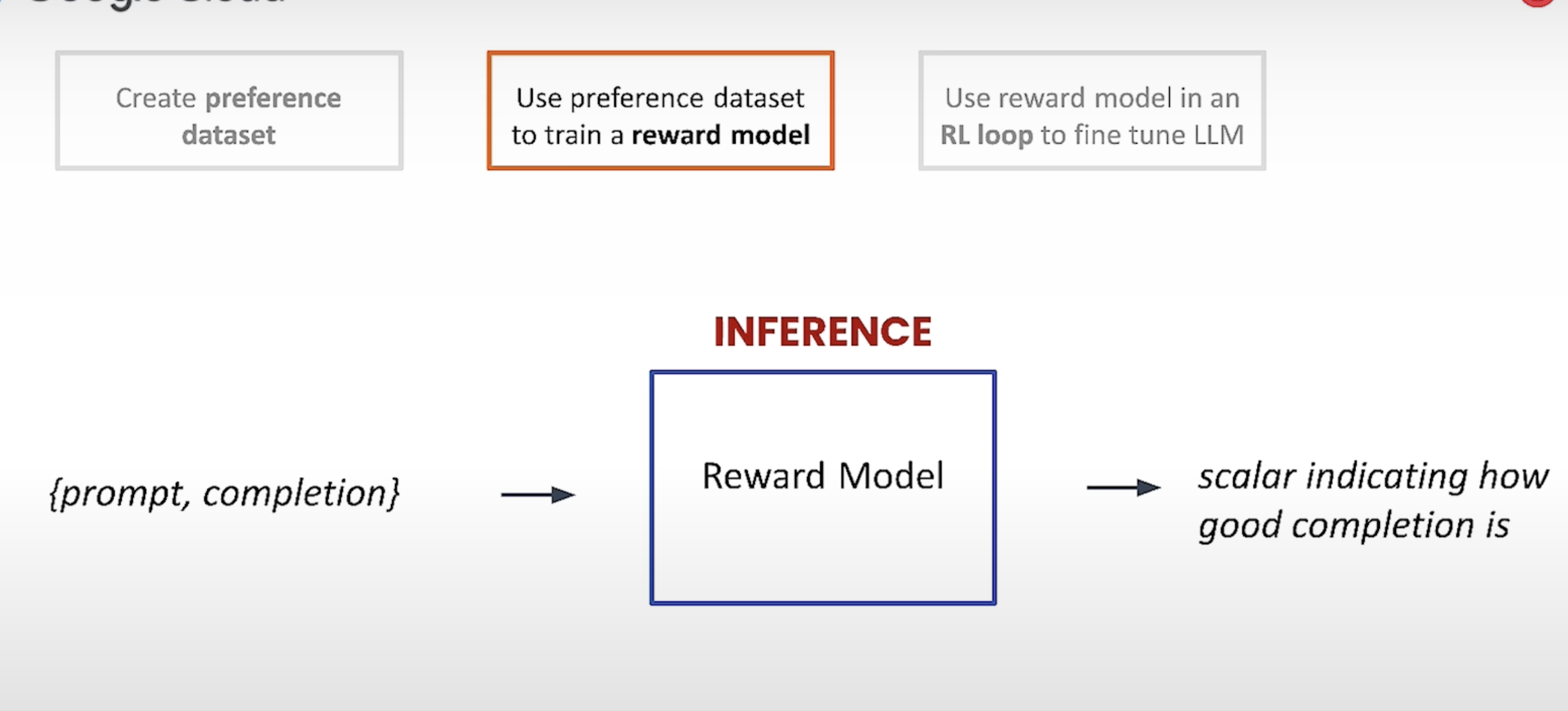
在做推理时,将prompt 以及LLM的completion作为输入,然后reward model会得到一个分值。
Fintune LLM
在下面的图中,简单介绍了RL的原理,通过Agent 采取行动与Environment交互,会产生一个reward 以及新的状态,目标是引导Agent产生reward最大化的action。
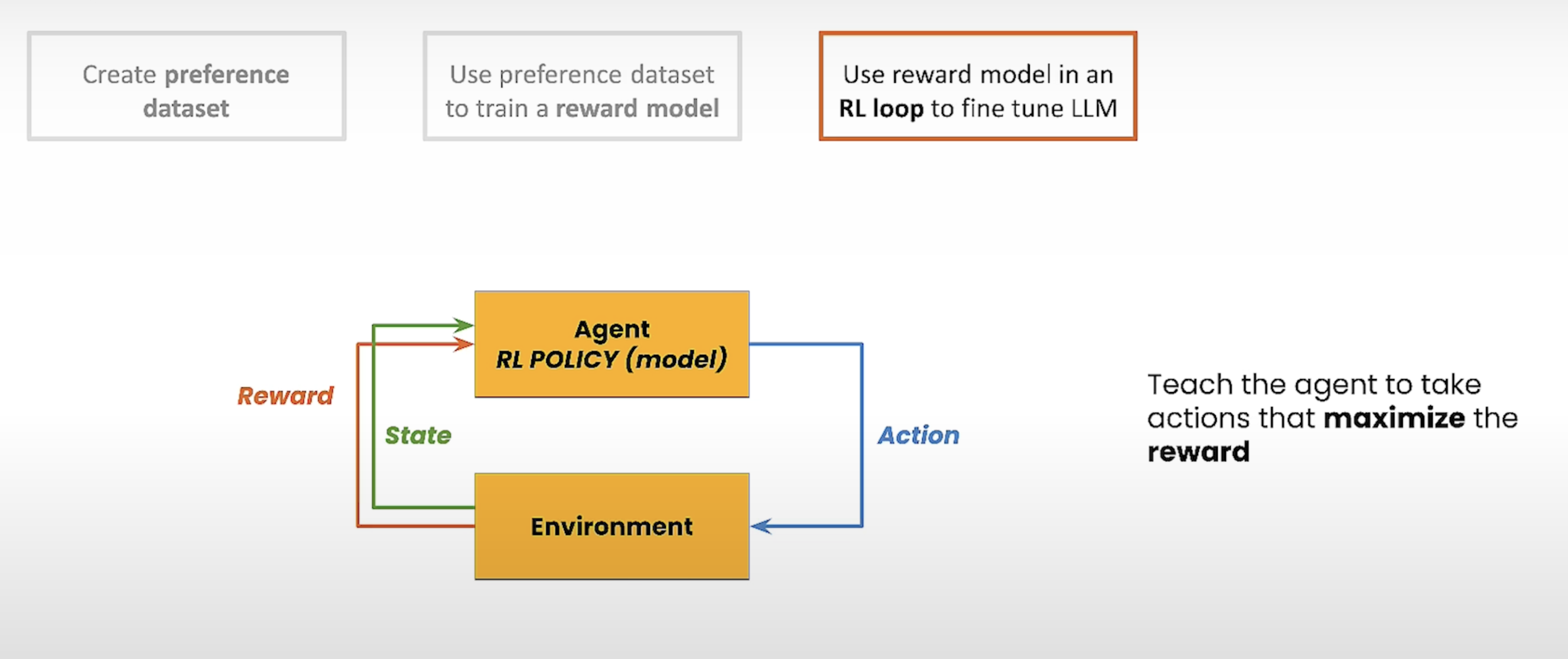
在RLHF中,Agent就是要训练的LLM,训练为了产生更好的输出
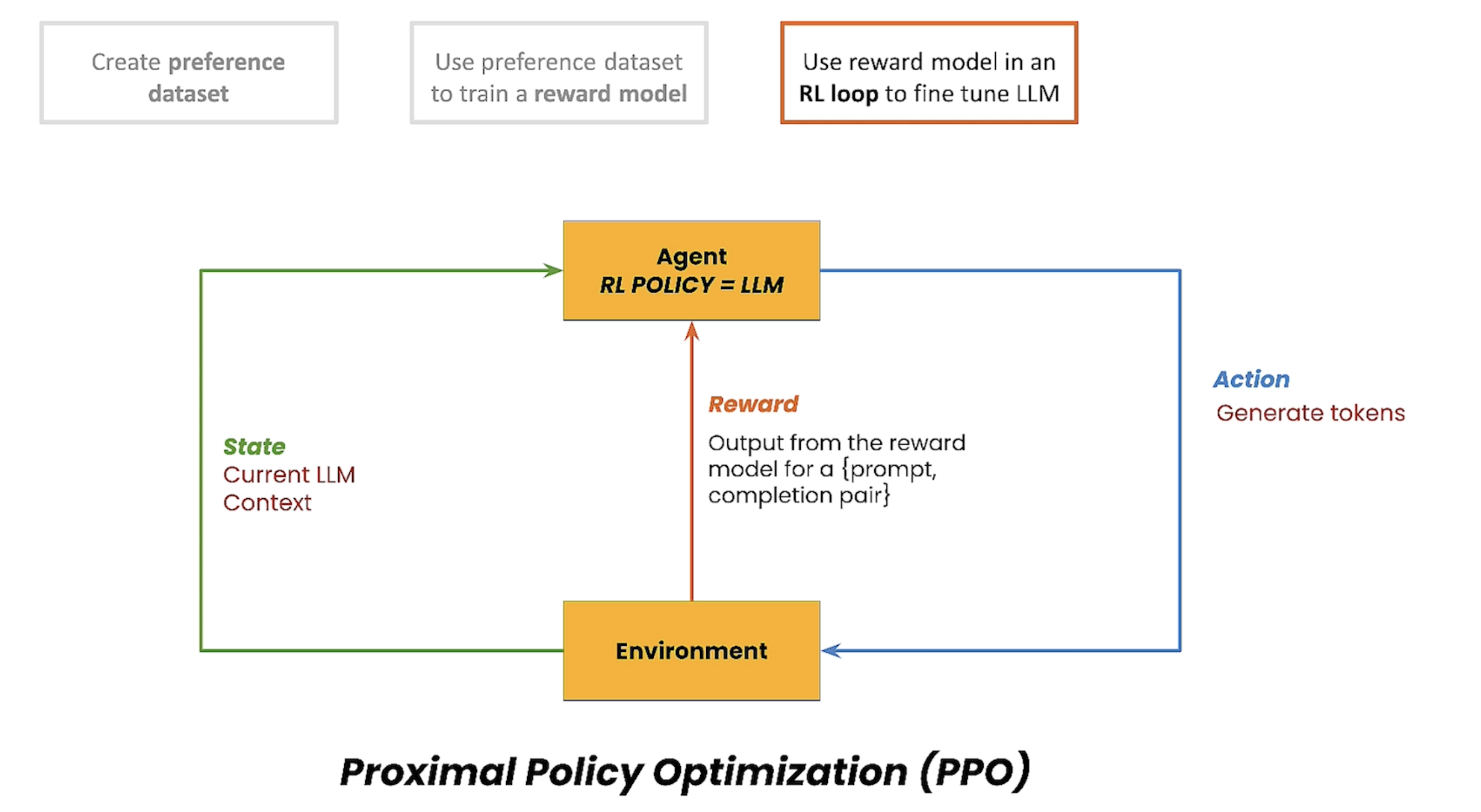
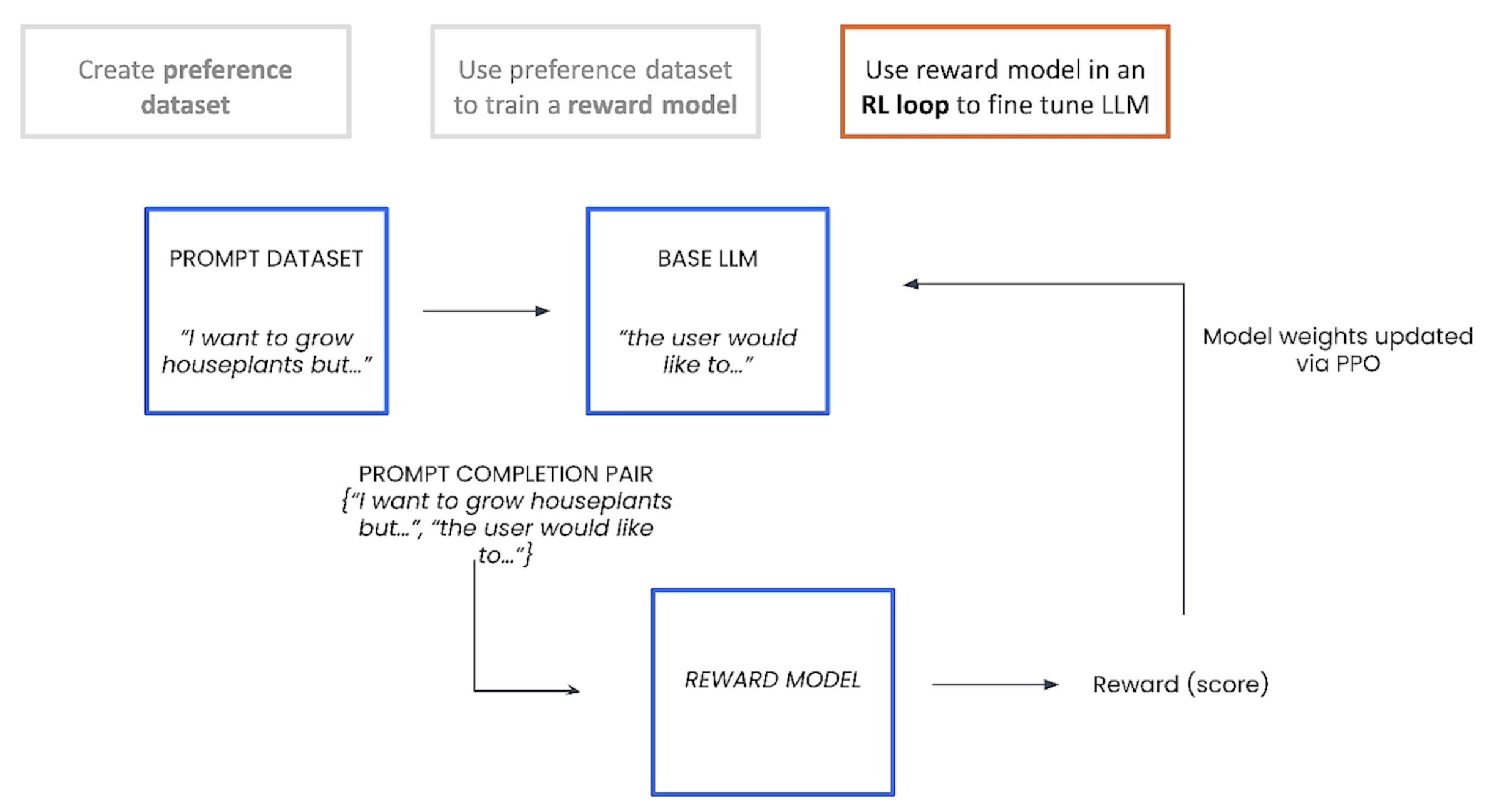
在本节中,将会采用PEFT方式去finetune。

Datasets for RL training
Reward Model train set
训练reward model的训练集中包含了candidate_0 以及candidate_1两个answer,然后有choice选择第0个或第1个,这样有利于把candidate_0与candidate_1都提供给model,然后让模型学到这两个candidate的不同之处。

prompt data set
对于prompt data来说,就只有相关的prompt训练集

Tune an LLM with RLHF
这里以Google cloud的 vertex AI作为训练平台进行训练。
下面是使用RLHF微调LLM的框架,原始LLM选的是llama-2-7b。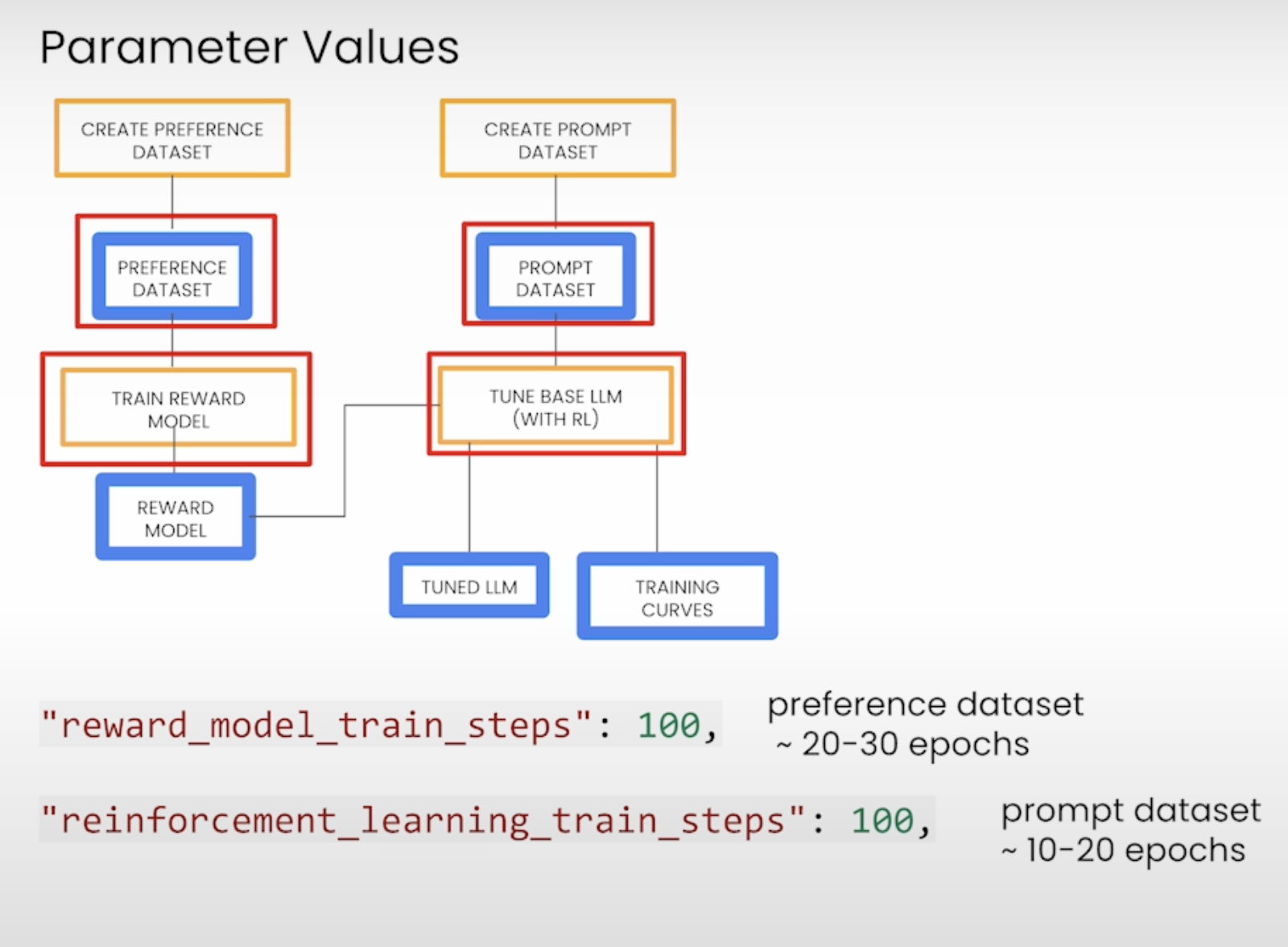
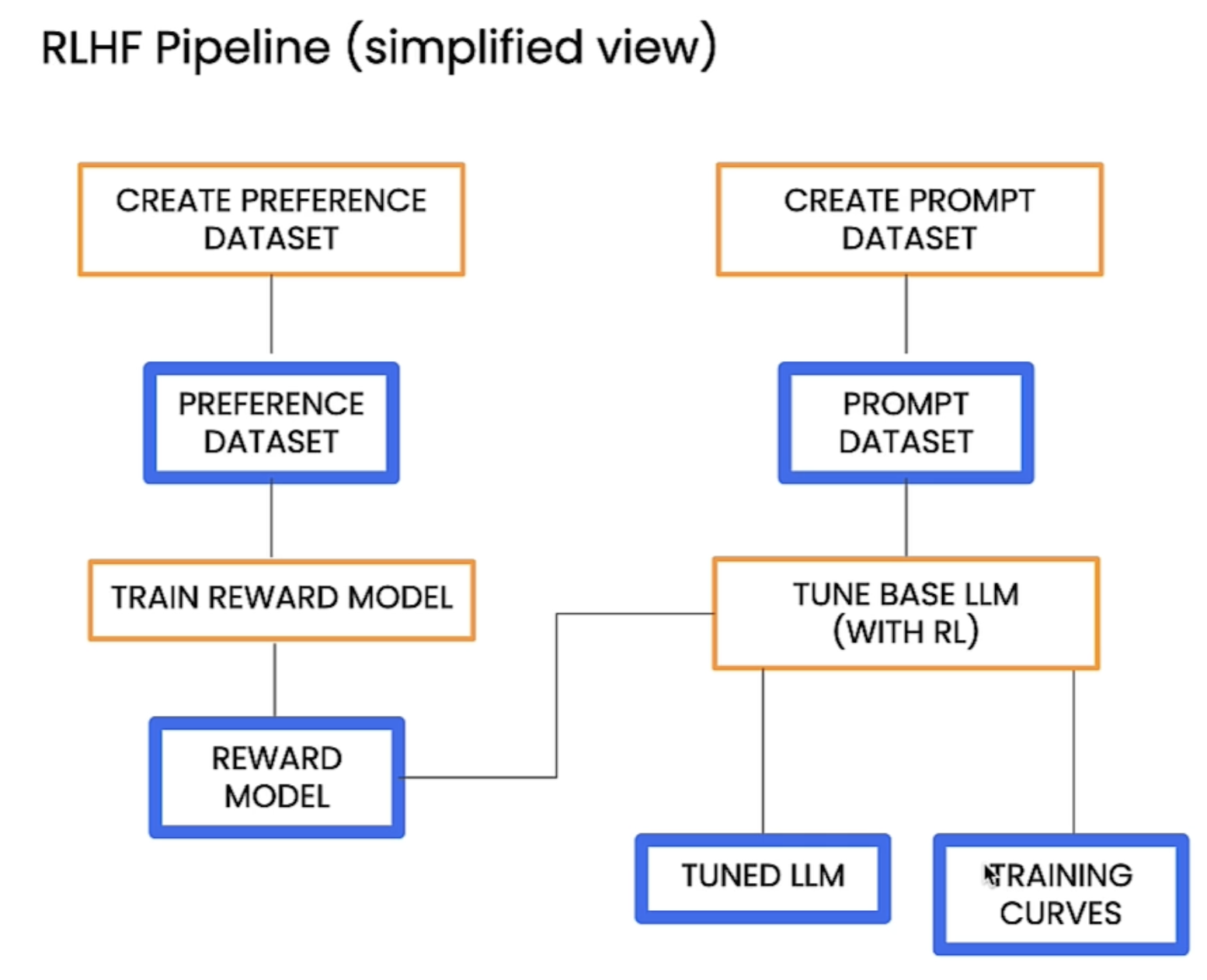
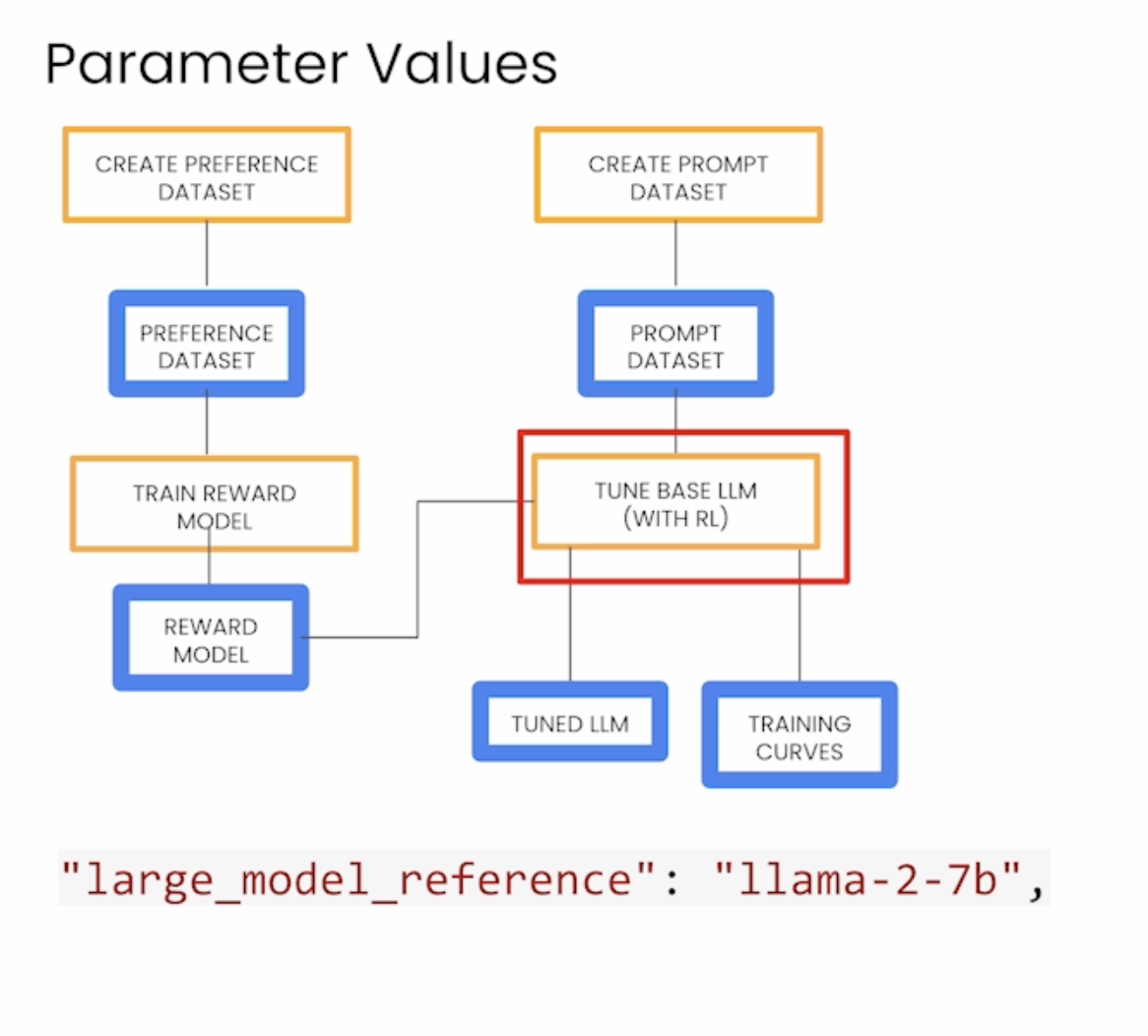
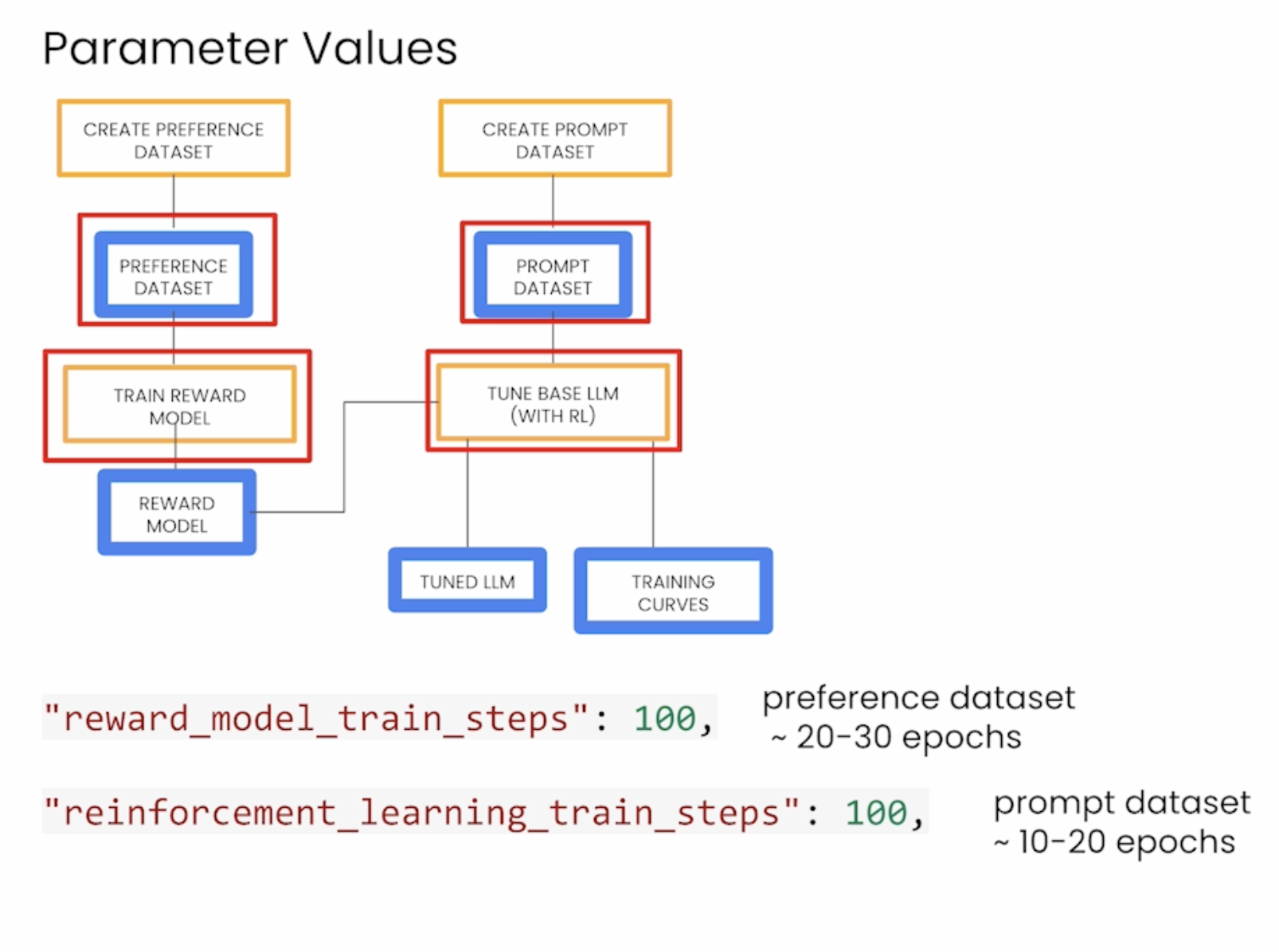
下面是一些训练参数,第一行是关于reward model的,第二行是关于微调LLM的。下面是对图片的详细解释。
Key Concepts and Variables:
1. Create Preference Dataset and Create Prompt Dataset:
• These are the initial steps to prepare datasets for training.
• The Preference Dataset represents user preferences (or ratings of different outputs) and is used to train a Reward Model.
• The Prompt Dataset contains prompts used to fine-tune a base language model (LLM) using reinforcement learning.
2. Train Reward Model:
• Reward Model is a model that predicts the reward for different outputs, guiding the reinforcement learning process.
• Parameters like "reward_model_train_steps": 100 indicate the number of training steps for the reward model (typically 100, but the specific value can depend on the dataset).
• The reward model helps evaluate the quality of generated outputs and aids in adjusting the language model.
3. Tune Base LLM (with RL):
• Tuned LLM refers to the base language model that has been fine-tuned using reinforcement learning techniques with the reward model.
• This step is essential for improving the performance of the base LLM on specific tasks or goals by using RL to adjust its parameters.
4. Training Curves:
• Training curves help visualize the performance during training, such as loss curves, which are used to monitor model convergence.
5. “kl_coeff”:
• KL coefficient is a hyperparameter that controls the balance between reinforcement learning and the original policy (or model). The image suggests increasing the KL coefficient (e.g., kl_coeff: 0.1) to reduce “reward hacking,” a situation where the model learns to optimize rewards in unintended ways.
6. Training Step Values:
• "reward_model_train_steps": 100: This means the reward model should be trained for 100 steps, which corresponds to approximately 20-30 epochs with the preference dataset.
• "reinforcement_learning_train_steps": 100: The reinforcement learning step for fine-tuning the model with 100 steps, typically with the prompt dataset, taking about 10-20 epochs.
• Other parameters include learning rate multipliers ("reward_model_learning_rate_multiplier": 1.0 and "reinforcement_learning_rate_multiplier": 1.0) to control how quickly the model learns in different training phases.
7. Instructions:
• The instruction in the image suggests training the model to summarize in less than 50 words for both the preference and prompt datasets.
Key Warning:
• Reward Hacking: A phenomenon where the model finds shortcuts to maximize rewards without actually solving the intended problem. This can be mitigated by adjusting parameters like the KL coefficient.
Overall, the process focuses on using reinforcement learning to fine-tune a language model by training a reward model and addressing reward manipulation issues (reward hacking).

Evaluate the tuned model
下面介绍了一些evaluate指标:
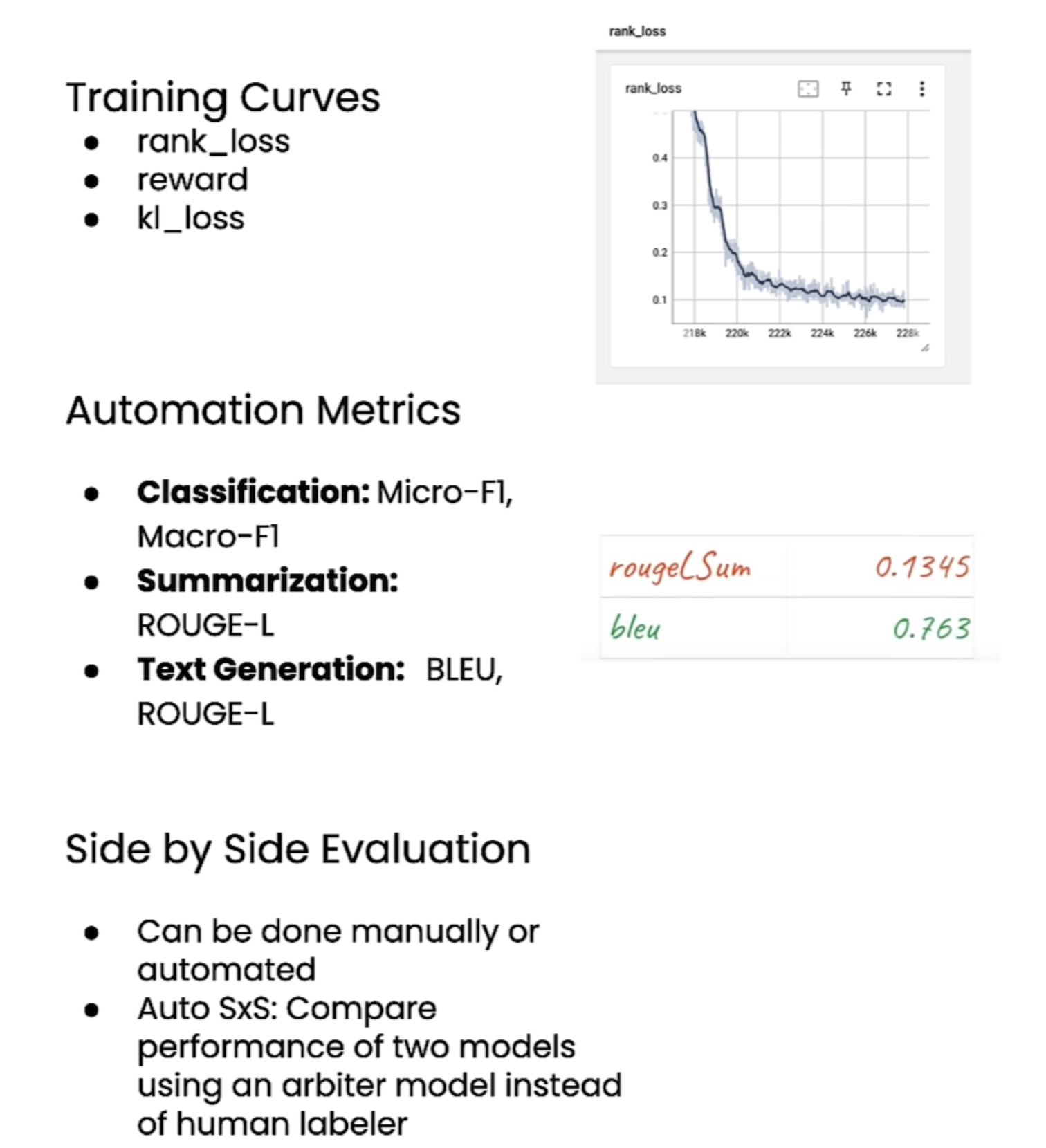
Kl_loss 与reward
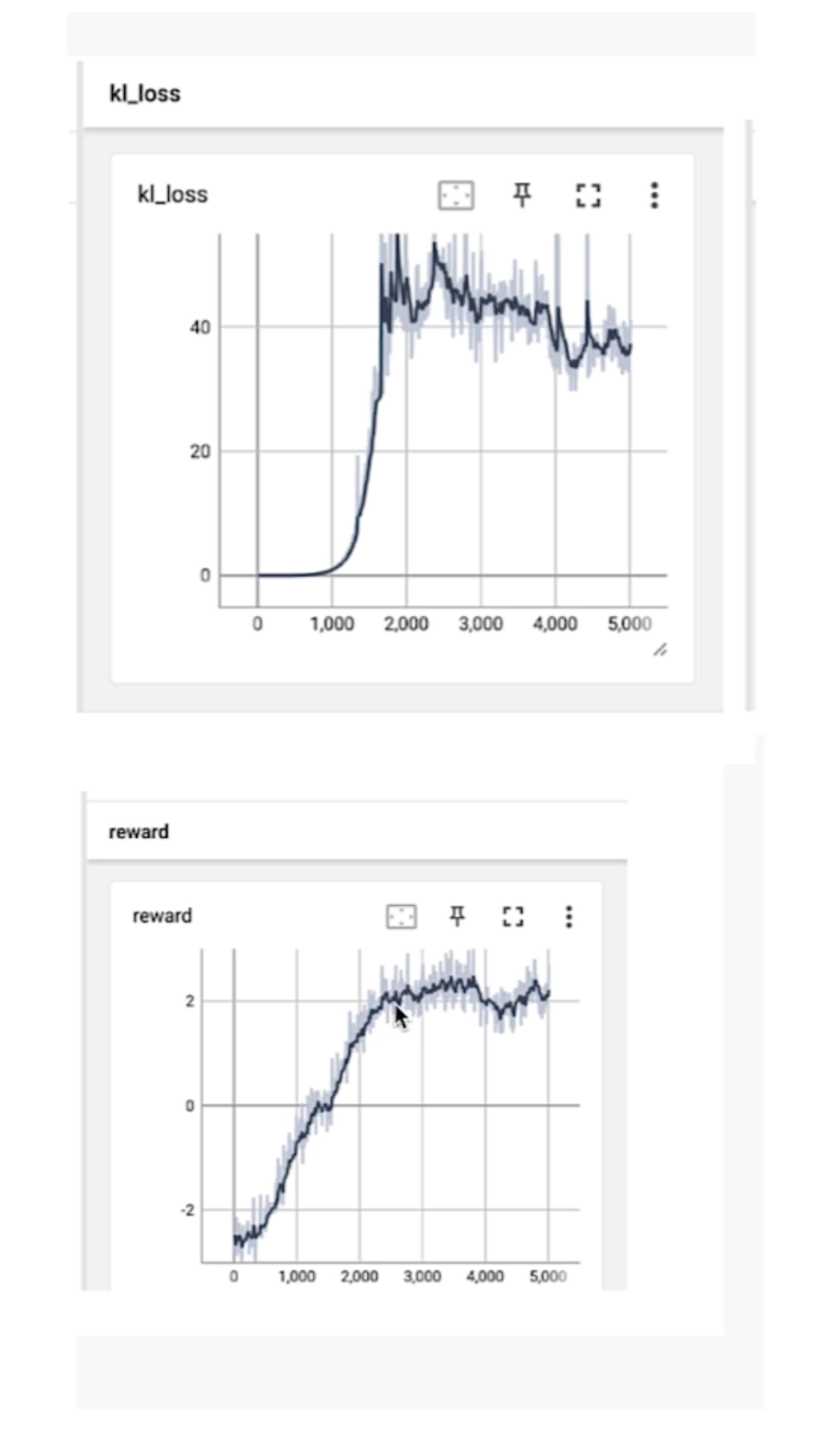
KL loss(KL散度损失)和 reward(奖励)是机器学习和强化学习中的两个重要概念,尤其在策略优化任务(如强化学习中的PPO算法)中密切相关。以下是它们的含义及关联解释:
---
### 1. KL Loss(KL散度损失)
- 定义:
KL散度(Kullback-Leibler Divergence)是衡量两个概率分布差异的指标。在机器学习中,KL Loss 通常用于约束模型输出的概率分布与某个参考分布之间的差异,防止模型偏离参考分布太远。
- 公式:
对于两个分布 \( P \) 和 \( Q \),KL散度定义为:
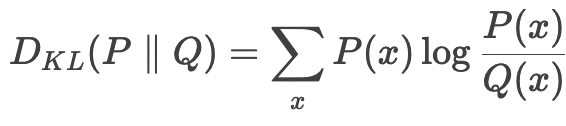
在深度学习中,通常用交叉熵损失减去参考分布的熵来计算。
- 应用场景:
- 强化学习(如PPO算法):限制新策略(policy)与旧策略之间的差异,避免策略更新过大导致训练不稳定。
- 生成模型:约束生成分布与真实分布的差异(如VAE)。
- 蒸馏(Knowledge Distillation):让学生模型的输出分布对齐教师模型的分布。
- 作用:
- 保持策略更新的稳定性,防止过拟合或策略崩溃。
- 在生成任务中,确保生成结果的多样性与真实性。
---
### 2. Reward(奖励)
- 定义:
在强化学习中,reward 是环境反馈给智能体的标量信号,用于评估当前动作的好坏。智能体的目标是通过最大化长期累积奖励(即回报)来学习最优策略。
- 特点:
- 稀疏性:某些任务中奖励信号可能稀疏(如围棋只有终局胜负奖励)。
- 设计难度:奖励函数需要合理设计,否则可能导致模型学到次优策略(如“奖励黑客”问题)。
- 即时性:可以是即时反馈(如机器人移动一步的能耗),也可以是延迟反馈(如游戏通关后的得分)。
- 应用场景:
- 强化学习中的策略优化(如DQN、PPO)。
- 对话系统中基于人类反馈的奖励模型(如RLHF)。
---
### 3. KL Loss 与 Reward 的关系
在强化学习(尤其是基于策略梯度的方法)中,两者常结合使用:
1. Reward 指导策略更新方向:
- 通过最大化期望奖励,模型学习如何选择高奖励的动作。
2. KL Loss 约束策略更新幅度:
- 防止新策略与旧策略差异过大,避免训练不稳定(如PPO中的重要性采样和KL惩罚项)。
示例(PPO算法):
- 目标函数包含两部分:
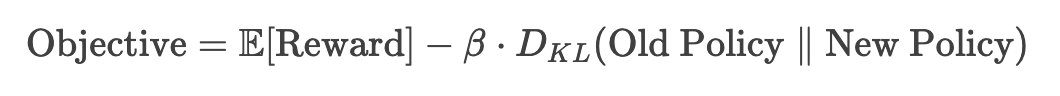
- 第一项鼓励高奖励的动作。
- 第二项(KL Loss)限制策略更新的幅度,避免策略突变。
---
### 4. 实际应用中的权衡
- KL系数(\(\beta\)
- 控制KL Loss的权重。若系数过大,策略更新过于保守;若过小,可能导致训练不稳定。
- 某些算法(如PPO)动态调整 \(\beta\) 以保持KL散度在目标范围内。
- Reward设计:
- 需与任务目标强相关,避免歧义或冲突。
- 在复杂任务中,可能需要结合人工标注或辅助奖励(如InstructGPT中的人类偏好模型)。
---
### 总结
- KL Loss:约束分布差异,稳定训练过程。
- Reward:提供优化方向,驱动模型学习目标。
两者在强化学习中协同工作,确保模型既能高效学习高奖励策略,又不会因更新过快而崩溃。