课程链接:https://learn.deeplearning.ai/courses/intro-to-federated-learning-c2/
github链接:https://github.com/MSzgy/Federated-Fine-tuning-of-LLMs-with-Private-Data
Introduction
本课程介绍了如何利用联邦学习(Federated Learning)去微调模型,涉及联邦学习,Differential Privacy,PEFT。

Smarter LLMs with Private Data
LLM是通过互联网上大量的公开数据进行训练得到的,但是对于一些私域数据,却不能得到很好的训练。因此很难产生高质量的回答。
下面是一些领域数据训练的模型

LLM中的隐私性问题是需要考虑的一个点,有人曾经在chatgpt中套出了自己的邮箱地址,这是因为自己的数据在chatgpt的训练预料中,因此在做私域数据的训练时也要注意数据的安全性。由此引出了本文要探讨的点Federated LLM Fine-tuning。在做训练时,数据并不会并上传到其他地方,而是训练完后,将模型的参数权重与之前的model进行整合,确保了数据的安全性。

Centralized LLM Fine-tuning
在本节介绍了传统的LLM fine-tuning。
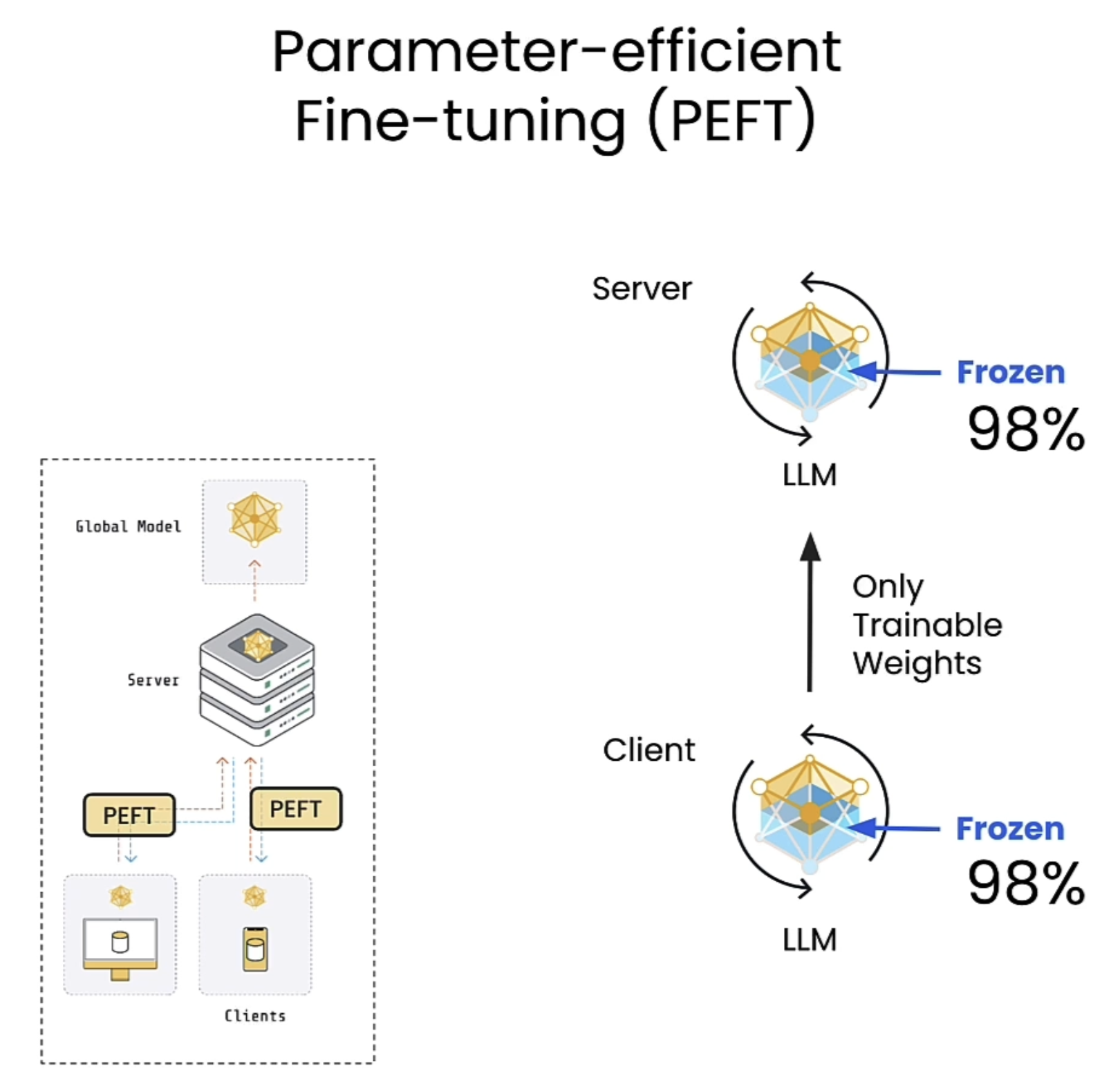
这里使用PEFT方式进行微调,可以从下图看到被训练的参数只占原来的0.278。

Federated LLM Fine-tuning
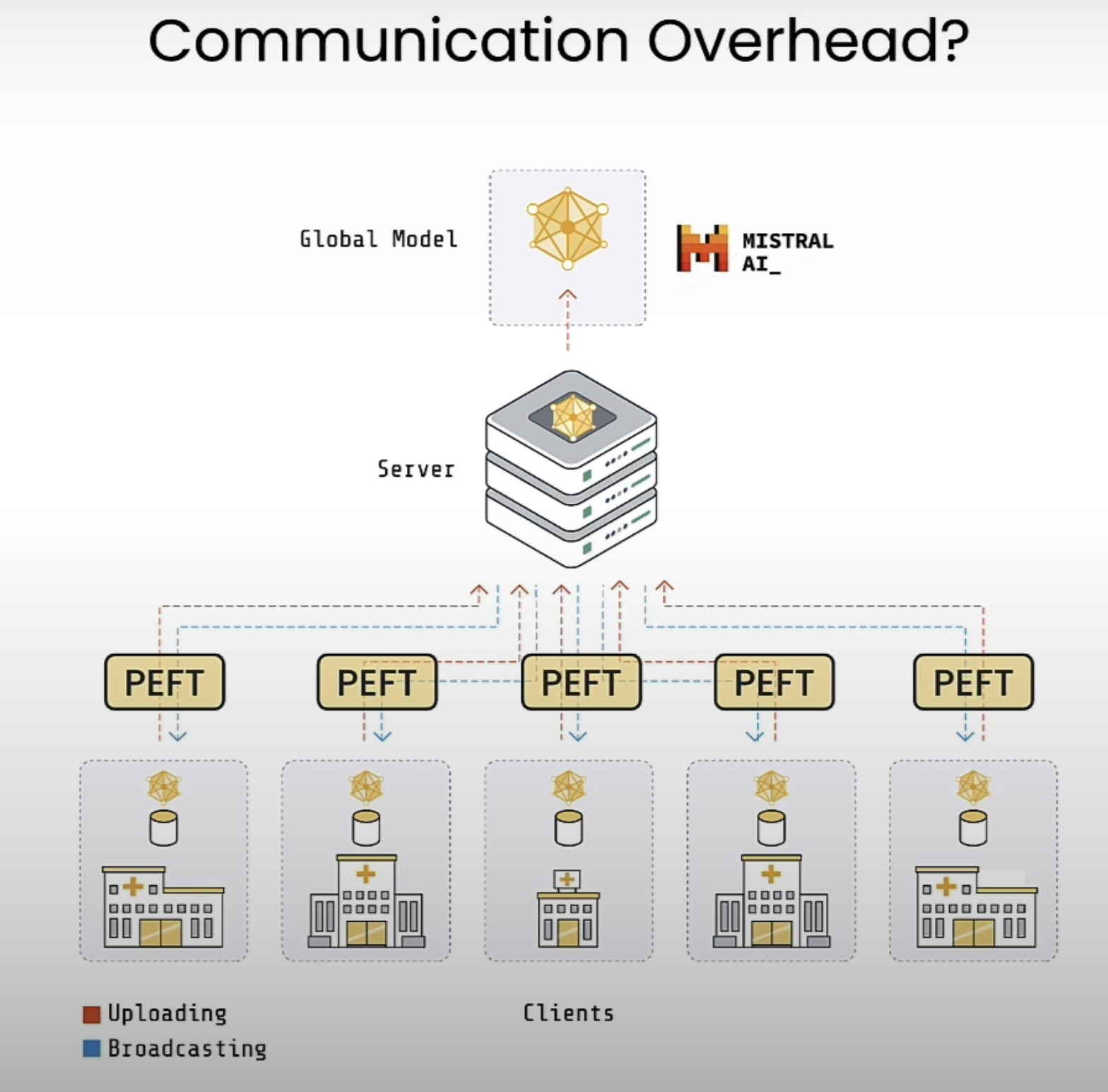
在这节介绍了Federated LLM fine-tuning,同时兼顾了privacy 与 effiency。与上节不同的是,上节的fine-tuning是把各种数据整合到一起然后放在server上训练,而本节直接在数据本地做训练。关于Federated Learning可以学习https://learn.deeplearning.ai/courses/intro-to-federated-learning。


Process
以下面的例子举例,在下面的流程中,会将model传输到各个医院,然后将数据在各个医院本地训练,这里为了减少模型传输时间以及训练时间,采用PEFT方式进行训练。
Federated Learning
https://learn.deeplearning.ai/courses/intro-to-federated-learning
联邦学习(Federated Learning) 是一种分布式机器学习技术,旨在**不共享原始数据**的前提下,让多个参与方(如手机、医院、企业)协作训练一个共享的全局模型。其核心思想是**“数据不动,模型动”**,既保护隐私,又利用分散数据的价值。
---
### 核心原理
1. 数据本地化:
各参与方(客户端)的原始数据始终保留在本地,无需上传到中心服务器。
- 例如:用户手机上的输入法模型根据本地输入习惯更新,但不会上传用户的输入内容。
2. 模型参数协作:
- 服务器下发全局模型给各客户端。
- 客户端用本地数据训练模型,生成**参数更新(梯度或模型权重)**。
- 客户端将参数更新加密上传,服务器聚合所有更新,生成新全局模型。
3. 迭代优化:
重复“下发模型 → 本地训练 → 聚合更新”的循环,直到模型收敛。
---
### 联邦学习类型
1. 横向联邦学习(Horizontal FL)
- 适用场景:参与方的数据特征(列)相同,但样本(行)不同。
- 例:多家银行用各自客户的信用数据联合训练反欺诈模型,特征(收入、负债等)相同,但客户群体不同。
2. 纵向联邦学习(Vertical FL)
- 适用场景:参与方的样本(行)重叠,但特征(列)不同。
- 例:医院与保险公司合作,医院有患者病历特征,保险公司有患者的理赔数据,双方联合训练疾病预测模型。
3. 联邦迁移学习(Federated Transfer Learning)
- 用于数据样本和特征均重叠度极低的场景,通过迁移学习弥补差异。
---
### 关键优势
1. 隐私保护:
原始数据不离开本地,满足GDPR等隐私法规要求。
2. 数据价值利用:
打破“数据孤岛”,联合分散数据提升模型性能。
3. 降低通信成本:
仅传输模型参数(而非原始数据),节省带宽。
---
### 技术挑战
1. 通信效率:
频繁传输模型参数可能带来延迟,需压缩或稀疏化参数(如梯度量化)。
2. 数据异构性(Non-IID):
各客户端数据分布差异大(如不同地区用户行为不同),导致模型收敛困难。
3. 隐私风险:
参数更新可能泄露数据信息(需结合差分隐私、同态加密等增强保护)。
4. 系统异构性:
客户端设备算力、网络条件差异大,需设计容错机制。
---
### 隐私增强技术
1. 差分隐私(DP):
在客户端上传的梯度中添加噪声,防止从参数反推原始数据。
2. 安全多方计算(MPC):
多方协作计算模型聚合结果,确保单方无法获取其他参与方的参数。
3. 同态加密(HE):
对加密后的参数进行聚合运算,服务器无法解密单个客户端的更新。
---
### 应用场景
1. 医疗:
多家医院联合训练疾病诊断模型,无需共享患者病历。
2. 金融:
银行间合作反洗钱模型,保护客户交易隐私。
3. 物联网:
智能家居设备根据本地用户习惯优化服务,数据不离设备。
4. 移动终端:
手机输入法、推荐系统基于用户本地行为更新模型(如Google Gboard)。
---
### 与中心化学习的对比
| 维度 | 联邦学习 | 传统中心化学习 |
|------------------|-----------------------------|---------------------------|
| 数据存储 | 分散在客户端,无需上传 | 集中存储在服务器 |
| 隐私风险 | 低(仅传参数) | 高(需上传原始数据) |
| 通信成本 | 较高(需多次迭代传参数) | 低(单次上传数据) |
| 适用场景 | 数据敏感或分散的场景 | 数据集中且无隐私限制的场景 |
---
### 总结
联邦学习通过**“数据不动,模型动”**的范式,解决了隐私与数据共享的矛盾,成为医疗、金融、物联网等领域的革命性技术。尽管面临通信效率、异构数据等挑战,但随着差分隐私、加密技术的结合,其安全性和实用性将持续提升,推动人工智能在隐私保护下的普惠发展。
Differential Privacy
以下面的图中例子举例,所谓DP,简单的说来就是在原有数据上加噪声以掩盖模糊原本的重要信息。对于LLM A以及LLM B,除去训练数据中的某几条信息并不会影响模型的行为。
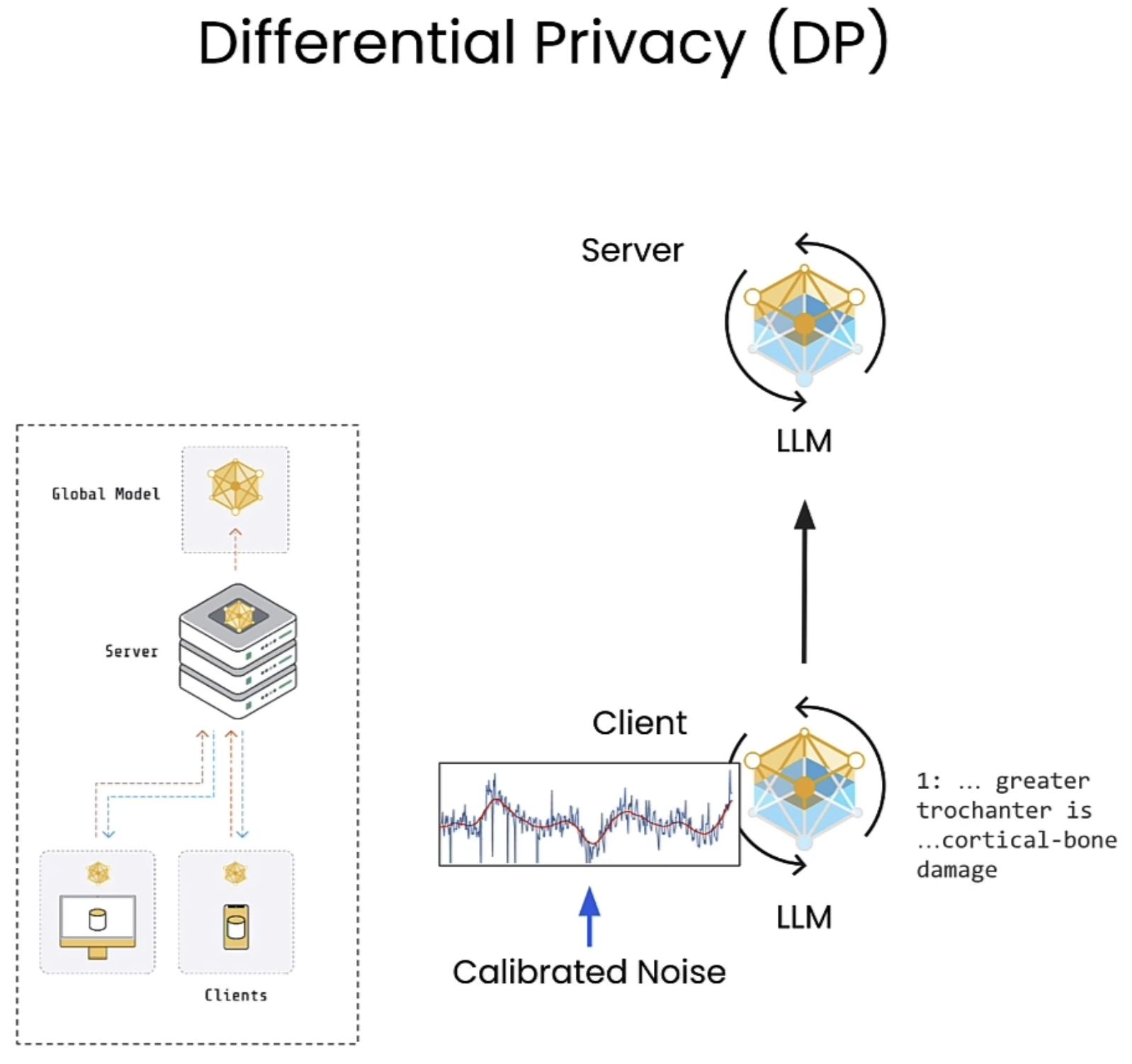
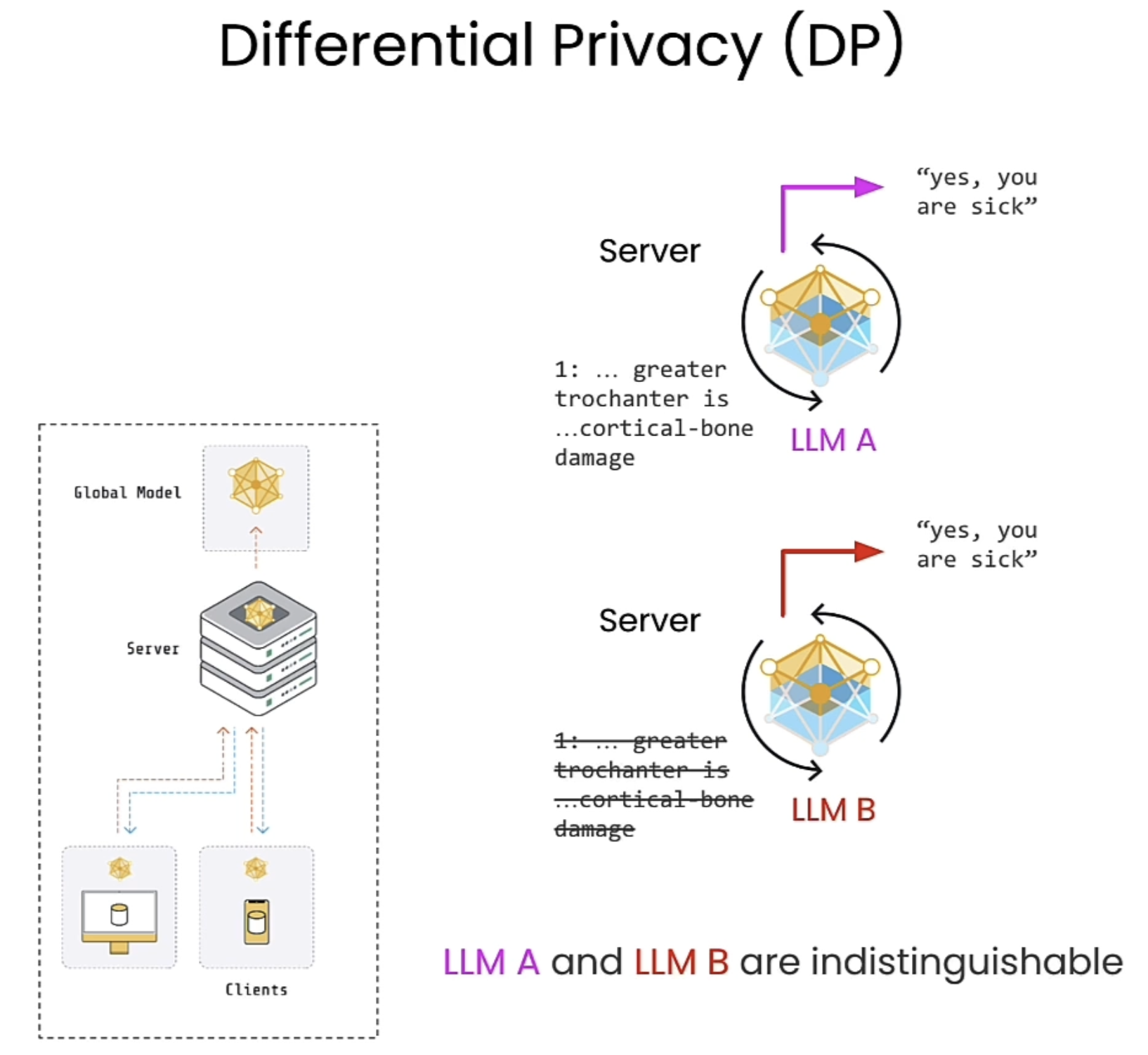
差分隐私(Differential Privacy) 是一种保护个人数据隐私的数学框架,核心目标是:在分析或发布数据时,确保“是否包含某个人的数据”不会对结果产生显著影响,从而避免泄露个体信息。
---
### 核心思想
1. 隐私保证:
通过向数据或查询结果中添加“可控的噪声”,使得攻击者无法通过输出结果反推出特定个体的信息。
- 例如:统计“某疾病患者人数”时,结果中加入随机噪声,即使某人是否患病,也无法被确定。
2. 关键参数:
- ε(隐私预算):控制隐私保护强度,ε越小,隐私性越强,但数据实用性越低。
- 敏感度(Δ):衡量“单一个体数据对查询结果的最大影响”,决定噪声大小。
---
### 常见机制
- 拉普拉斯机制(Laplace):
对数值型查询结果(如计数、求和)添加拉普拉斯分布的噪声,噪声规模由 Δ/ε 决定。
- 例:统计某城市收入中位数时,加入随机扰动,使无法推断个人收入。
- 高斯机制(Gaussian):
适用于高维数据,提供更宽松的 (ε, δ)-差分隐私(允许极小的隐私泄露概率 δ)。
---
### 关键特性
1. 抗后续处理:对差分隐私处理后的数据做任何二次分析,隐私性不变。
2. 组合性:多次查询会累积隐私消耗(总隐私预算 = 各次查询的 ε 之和)。
3. 局部差分隐私:数据在采集前由用户本地添加噪声(如手机端),无需信任中心服务器。
---
### 应用场景
- 人口普查:美国2020年人口普查用差分隐私保护家庭数据。
- 科技公司:苹果、谷歌用其统计用户行为(如输入法热门词),不追踪个体。
- 医疗研究:在共享患者数据时,防止泄露个人病史。
---
### 挑战
- 噪声可能降低数据准确性(需权衡隐私与实用性)。
- 参数选择(如ε大小)依赖经验,需结合场景调整。
---
总结:差分隐私通过“加噪”和严格的数学定义,在数据分析和机器学习中平衡隐私保护与数据价值,已成为现代隐私保护的核心技术之一。
PEFT
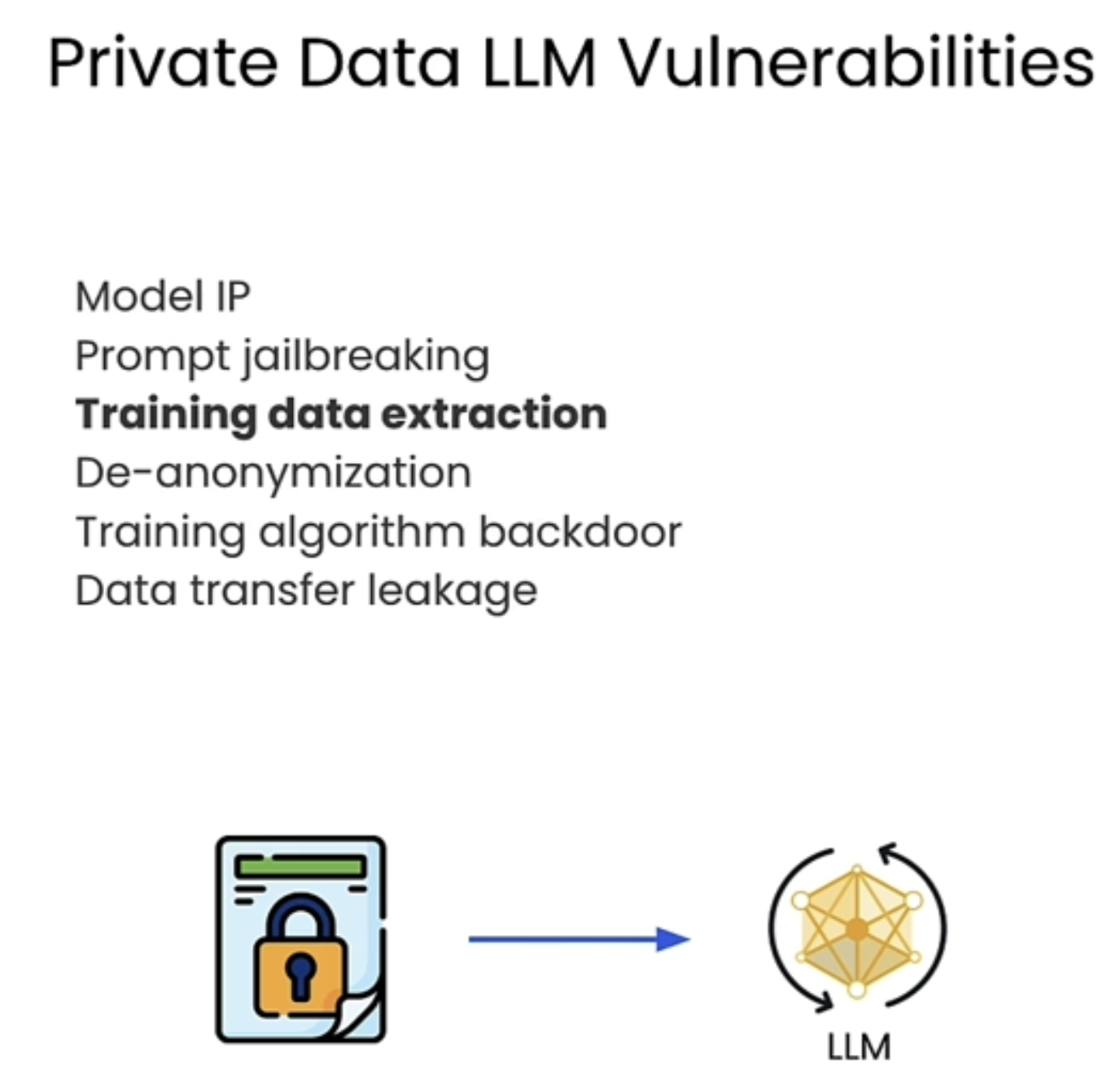
Keeping LLMs Private
下面是常见的一些LLM攻击方法
This image outlines several vulnerabilities associated with private data and LLMs (Large Language Models), including:
1. Model IP – Risks of intellectual property theft related to the model’s architecture and parameters.
2. Prompt Jailbreaking – Techniques to bypass model restrictions and obtain unauthorized outputs.
3. Training Data Extraction – The possibility of extracting sensitive data from the training set, posing privacy risks.
4. De-anonymization – Identifying individuals from supposedly anonymized data.
5. Training Algorithm Backdoor – Introducing malicious functionalities during training.
6. Data Transfer Leakage – Unintended data exposure during communication with the model.
下图介绍了两种方式可以提出training data (但经过尝试,对于deepseek以及 chatgpt,并没有什么用)

下面图片解释了 成员测试(Membership Test) 的工作原理,关键概念是 困惑度(Perplexity):
• 困惑度 是用来衡量 LLM(大型语言模型)生成某个序列时的“惊讶程度”。
• 困惑度越低,表示模型对这个序列越“熟悉”,预测得越准确。
• 计算方法:通过 序列中所有 Token 的归一化概率 来计算。
• 如果一个序列中每个 Token 的概率都很高,那么整体困惑度就会很低。
• 低困惑度的序列 通常是模型“见过”的内容,很可能是训练数据的一部分,这意味着模型对训练数据有一定程度的记忆。
这种方法用于检测某段内容是否出现在模型的训练集中,从而评估模型是否存在 训练数据泄露 风险。
chatGPT解释:
PPL公式:

成员测试(Membership Inference Attack, MIA)主要是用来评估 LLM 是否泄露了训练数据的隐私。以下是详细工作原理和步骤:
核心概念:困惑度(Perplexity) • 定义:困惑度衡量 LLM 对生成某个序列的“惊讶程度”,即模型对这个序列的预测难度。 • 公式:  •  是完整的序列, 是序列中的第  个 Token。 •  是在已知前面 Token 的情况下,模型预测下一个 Token 的概率。 • PPL 越低,表示模型对该序列越熟悉,越可能见过它。
成员测试的步骤
- 准备数据集: • 候选数据集:包含若干序列,其中一部分在模型训练集中出现过,另一部分没有出现过。
- 计算困惑度: • 使用 LLM 对每个序列计算困惑度。
- 分析困惑度分布: • 训练集中出现过的序列:困惑度较低,因为模型对它们较为熟悉。 • 未出现过的序列:困惑度较高,模型更难预测。
- 判定是否为训练数据: • 设置阈值:根据困惑度的分布设置阈值。 • 若某序列的困惑度低于阈值,则判定它“可能”出现在训练集中。
风险和影响 • 隐私泄露:如果序列来自敏感数据(如个人信息、医疗记录等),则会导致隐私泄露。 • 模型安全性:暴露模型对特定数据的“记忆”程度,可能被攻击者用于重建训练集的一部分。
防御方法
- 差分隐私(Differential Privacy): • 在模型训练过程中引入噪声,使得单个训练样本对模型输出的影响极小,从而降低成员测试的准确性。
- 正则化和Dropout: • 减少模型对训练数据的过度拟合,降低记忆效应。
- 数据去重和清洗: • 删除训练集中重复或敏感的数据,减少模型对特定序列的记忆。
应用场景 • 隐私审计:用于检测 LLM 是否存在潜在的隐私泄露。 • 安全评估:评估模型在数据保护方面的鲁棒性,特别是在处理敏感数据时。
总结 • 成员测试 是一种强有力的隐私攻击手段,通过分析 LLM 的困惑度分布,推测某序列是否在训练集中出现过。 • 核心技术 是利用 LLM 对训练数据的“记忆”特点,寻找低困惑度的序列。 • 防御重点 在于通过差分隐私和正则化等方法,减少模型对单个训练样本的依赖。

在本节代码中,介绍了ROC指标来评估训练数据容易泄露程度。
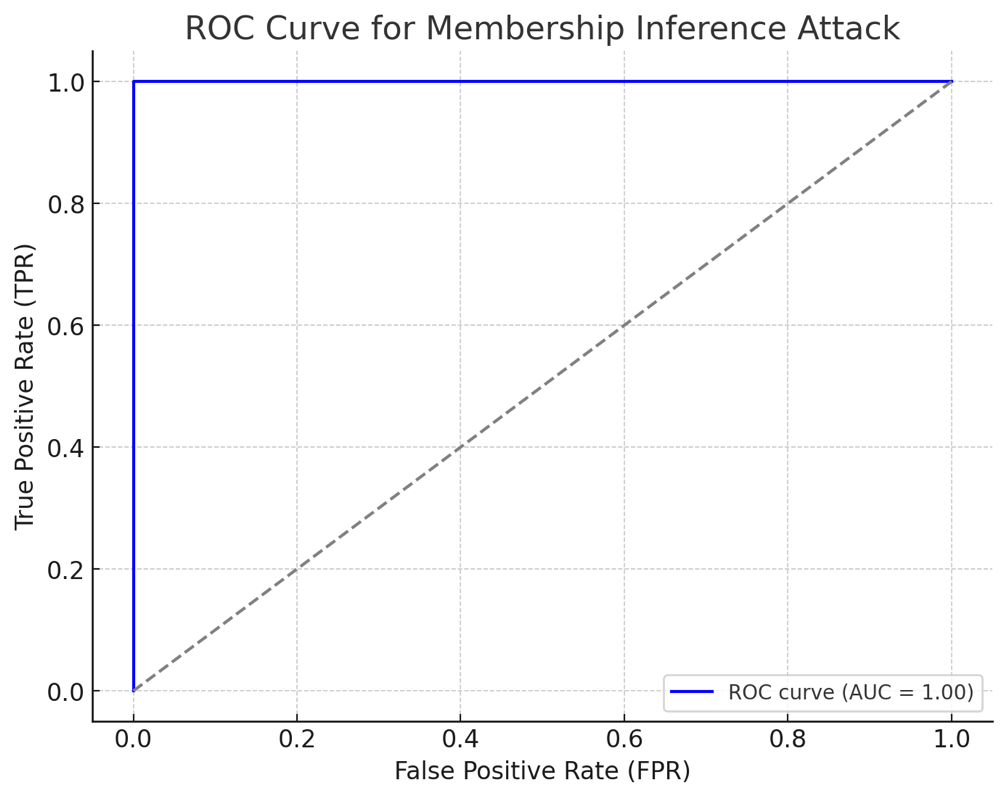
这是基于假设数据绘制的 ROC 曲线,用于模拟成员推断攻击中对训练数据和未见过数据的区分:
• 横轴是 False Positive Rate (FPR),即误报率。
• 纵轴是 True Positive Rate (TPR),即真正率。
• 蓝色曲线表示模型对训练数据和未见过数据的区分能力。
• 灰色虚线为随机猜测的基线。
在 ROC 曲线中:
1. 曲线偏左上方:
• 表示模型具有 很高的区分能力。
• True Positive Rate (TPR) 高,False Positive Rate (FPR) 低,即模型能准确地识别出正样本(如训练数据),且误判为正样本的负样本(如未见过的数据)较少。
• AUC 接近 1,说明模型几乎可以完美地区分训练数据和未见过的数据。
• 在成员推断攻击场景中,这意味着攻击者可以 非常准确 地判断某段数据是否用于模型训练,暴露出严重的隐私风险。
2. 曲线偏右下方:
• 表示模型具有 极差的区分能力 或 分类方向反了。
• TPR 低,FPR 高,即模型经常将正样本错误分类为负样本,反之亦然。
• AUC 接近 0,这意味着模型 几乎完全错误 地分类正负样本。
• 在成员推断攻击场景中,这可能表明攻击者判断完全相反(如训练数据被认为是未见过的数据),或者模型具有 混淆攻击者的效果。
• 总结:
• 左上方: 高区分能力(隐私风险高)。
• 右下方: 低区分能力或分类反转(攻击者难以推断成员关系)。
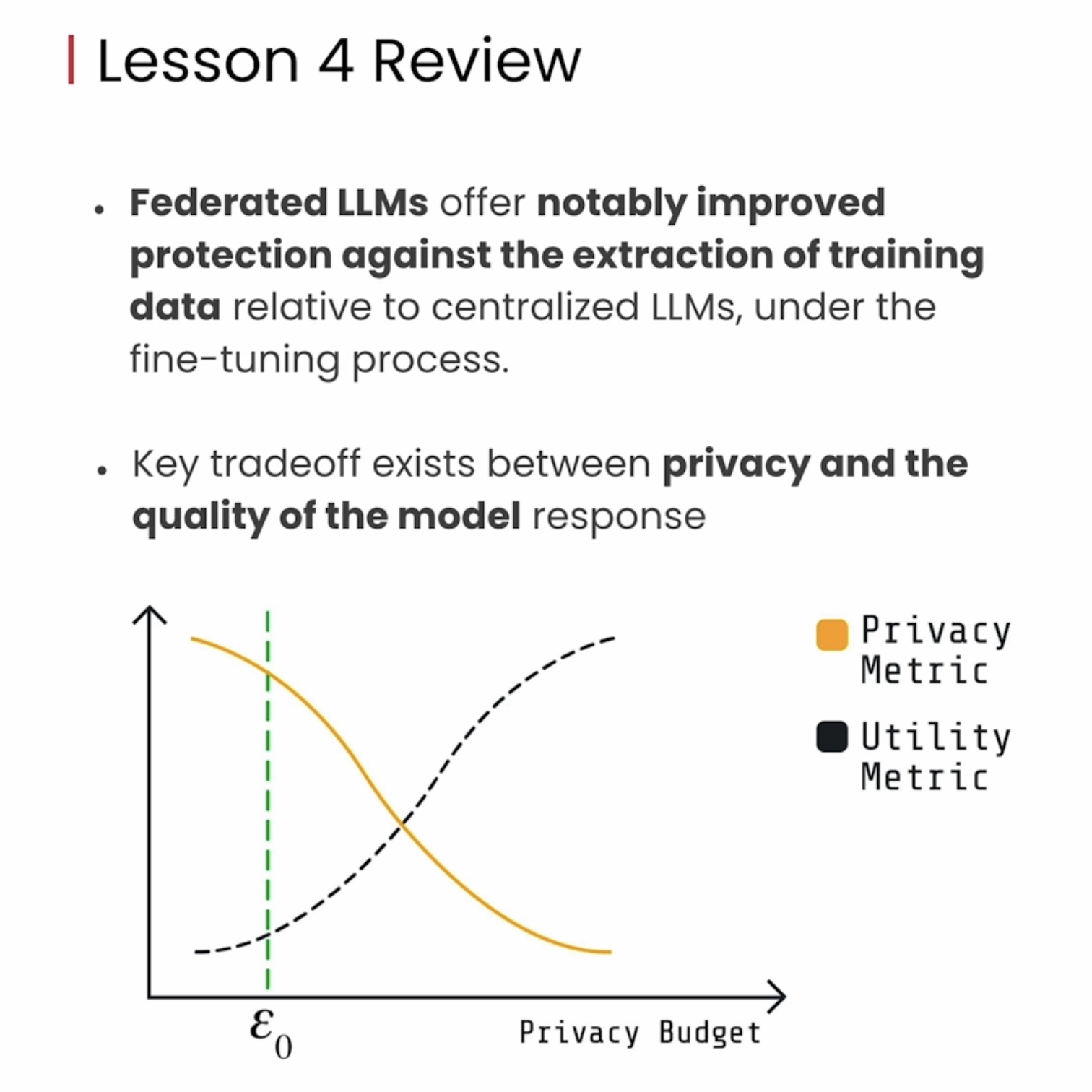
下图中,可见Centralised_fine-tuning比Federated_fine-tuning更为靠左上角,由此说明隐私数据攻击很有效。
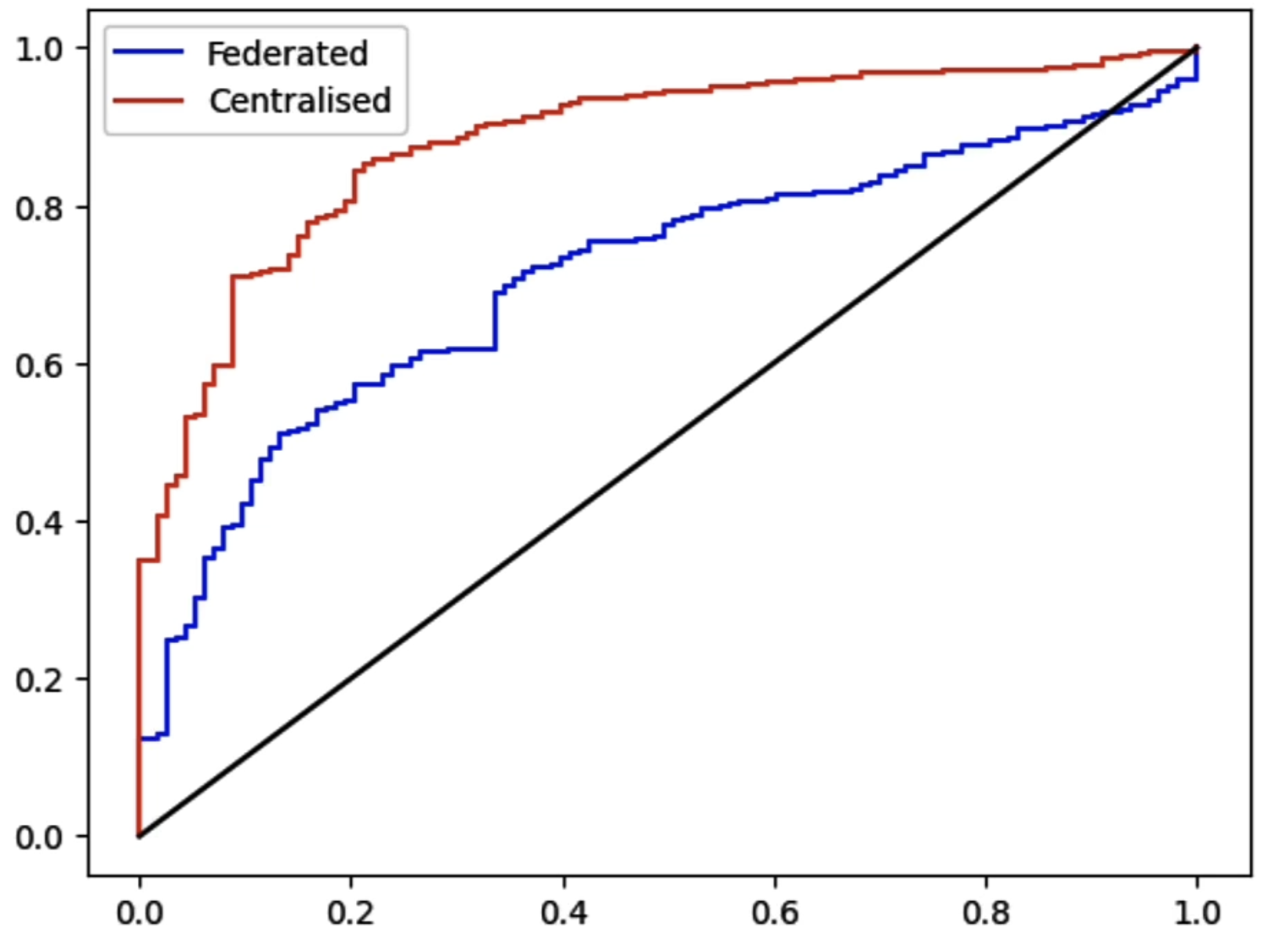
在本节最后,也提出了privacy以及model quality的tradeoff问题,这需要具体问题具体分析,需要具体在项目中进行衡量。