课程链接:https://learn.deeplearning.ai/courses/intro-to-federated-learning/lesson/uhuz2/introduction
github链接:https://github.com/MSzgy/Intro-to-Federated-Learning.git
Introduction
本课程介绍了Federated Learning(联邦学习),通过这种方式可以维护训练数据的安全性,并且model的参数是在local训练的,最终会把各个local的model上传到server。同时在本课程还提到了一些实用的数据保护策略,例如差分隐私(DP)。
Why Federated Learning
在筛选训练数据时,需要注意到目前使用的都是public data,但是从下图可看出隐私数据占比更多,因此应该如何考虑在private data上进行训练。

Fedetated learning最重要的一点是保持了数据合规,对于每个国家都有自己的数据要求,有的会限制数据不能离境,在这种情形下,Federated learning可以保证在当地使用相关数据训练模型。

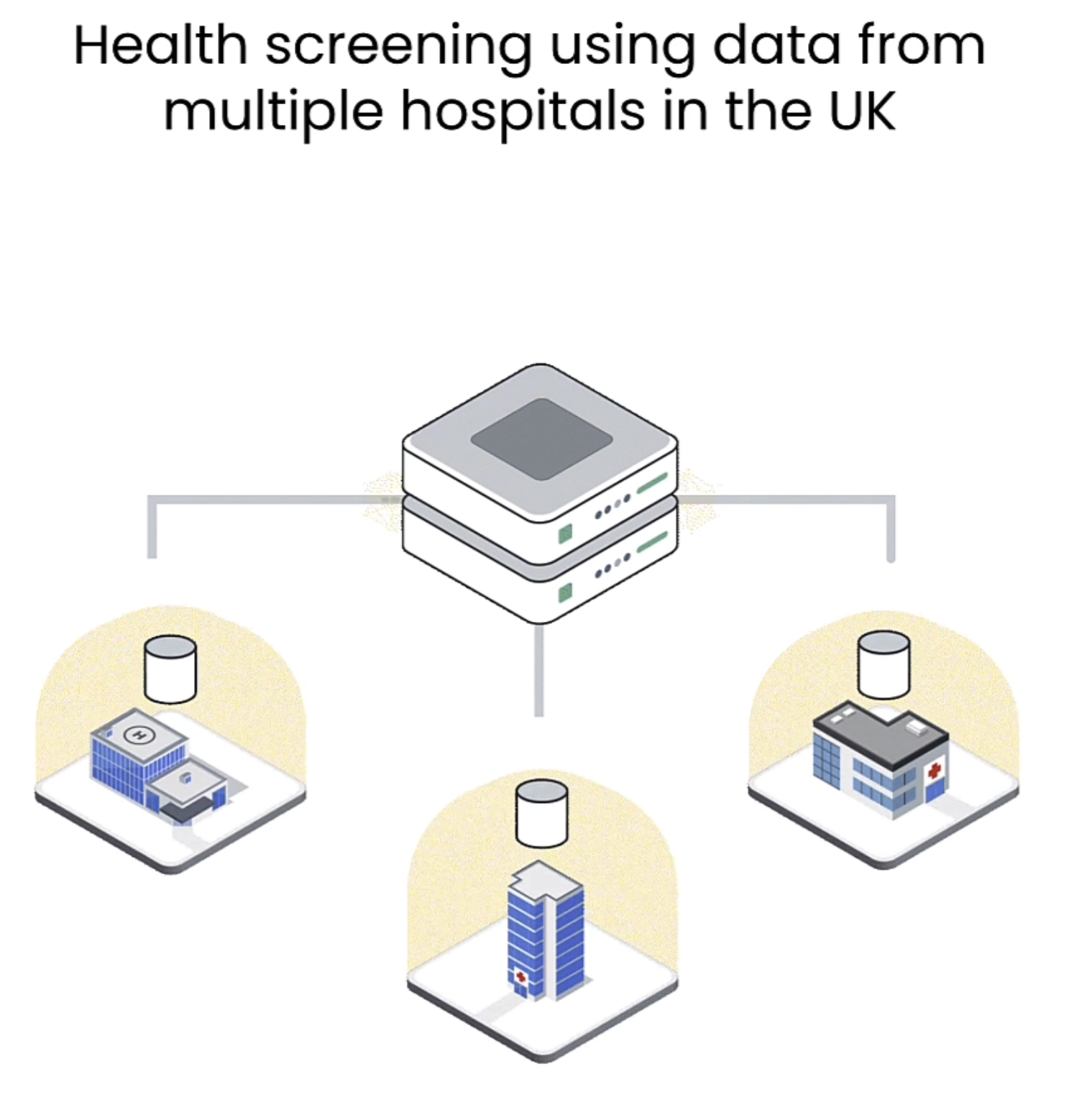
下图是Federated learning的一个例子,各地医院可以利用自己的数据训练模型。
Federated Training Process
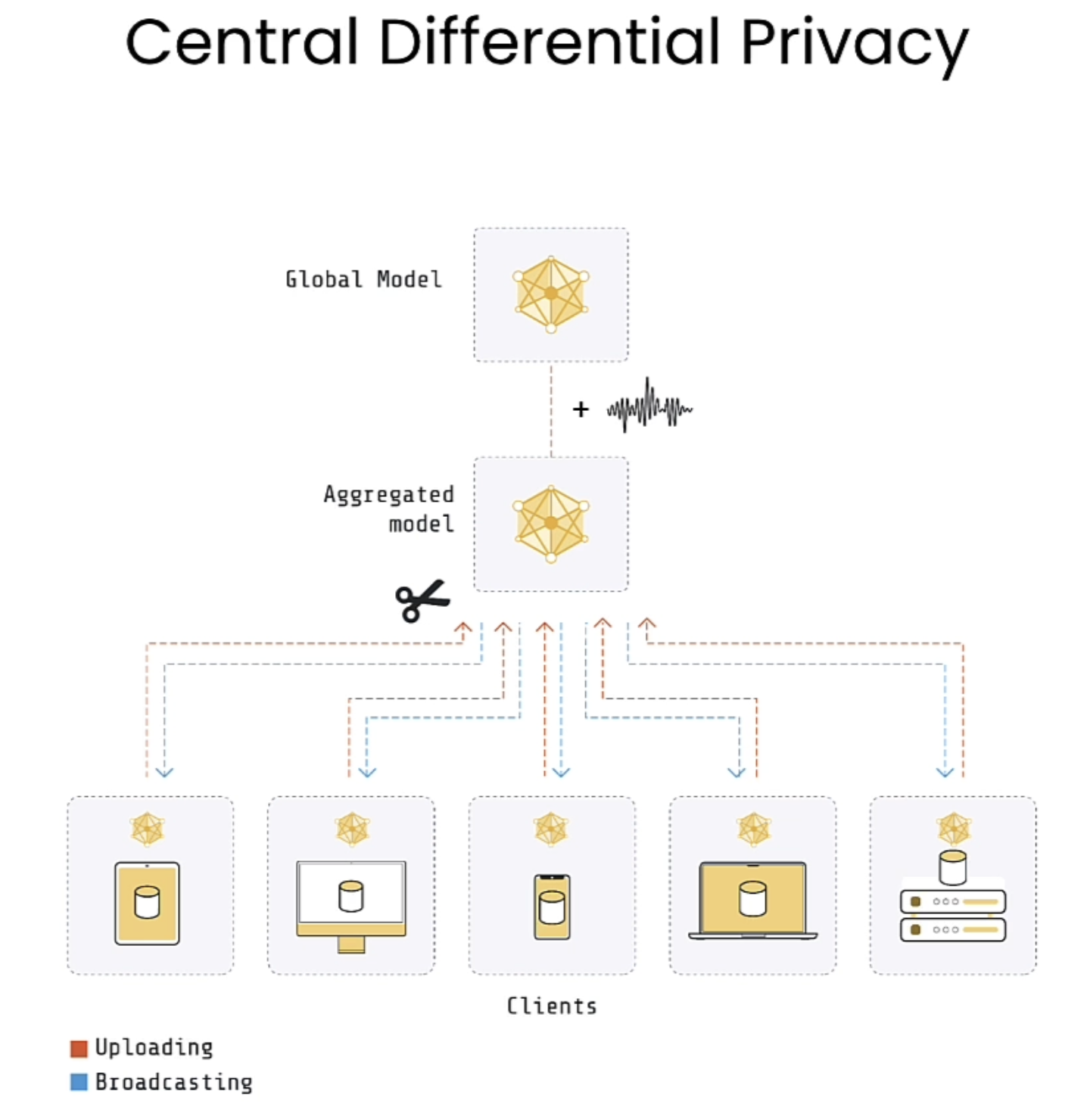
下面是Federated Learning process, 数据都保留在client端,server端会把model传到各个client。在训练时每个client都会对原有model参数做训练,最后各个client将各个训练后的参数传到server端,server会做average处理。


Tuning
在这节,详细介绍了Federated Learning中的框架以及各个参数,例如local_epoch(client 训练轮数),num_clients_participating (参与训练的客户端数量),server端如何聚合client端传来的模型参数等,并讨论了如何根据不同的情况调整这些参数以得到最佳的训练结果。client端的训练配置项都可以从server端获取。
Data Privacy
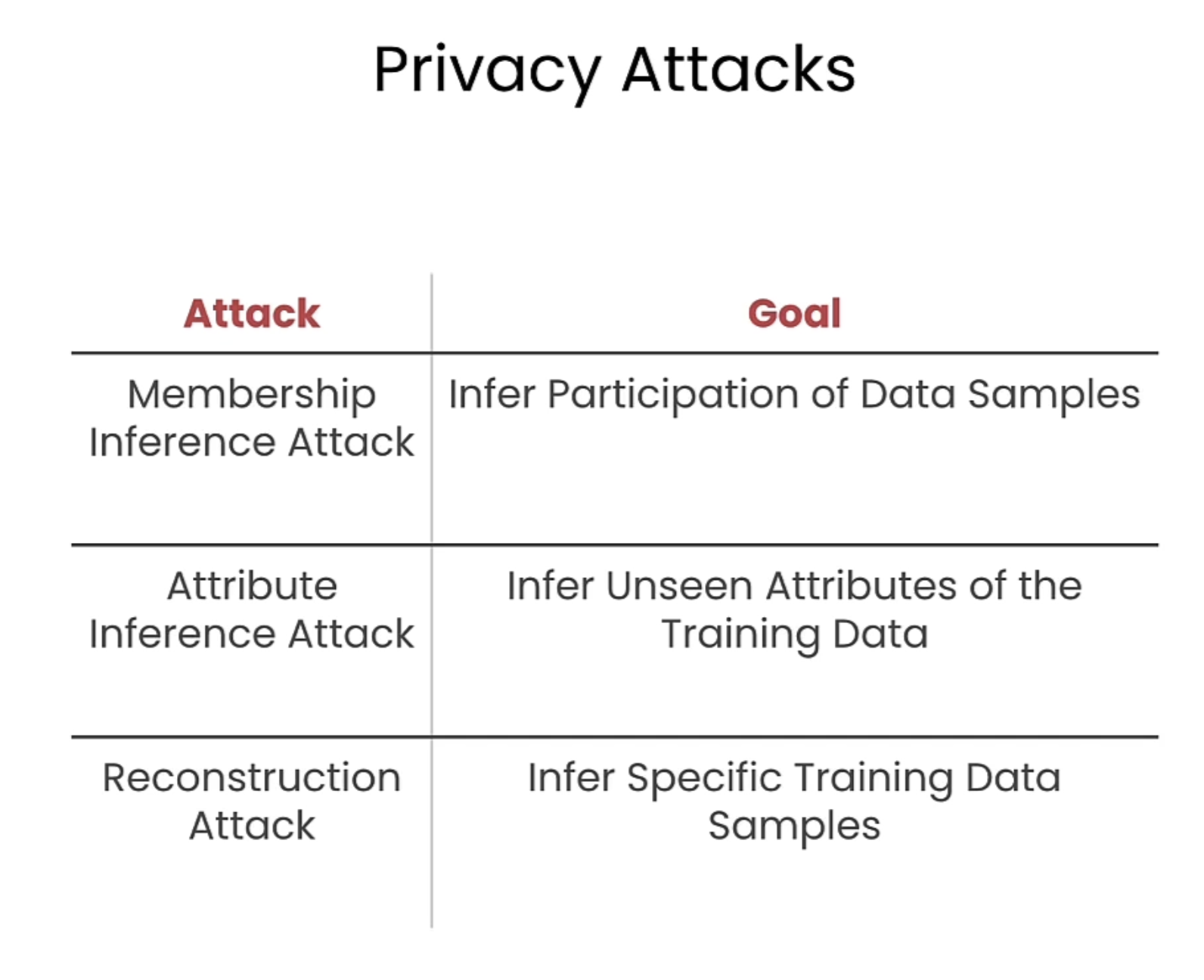
在这节将介绍一种数据安全增强方法:Differential Privacy,下面列举了相关的攻击方式。
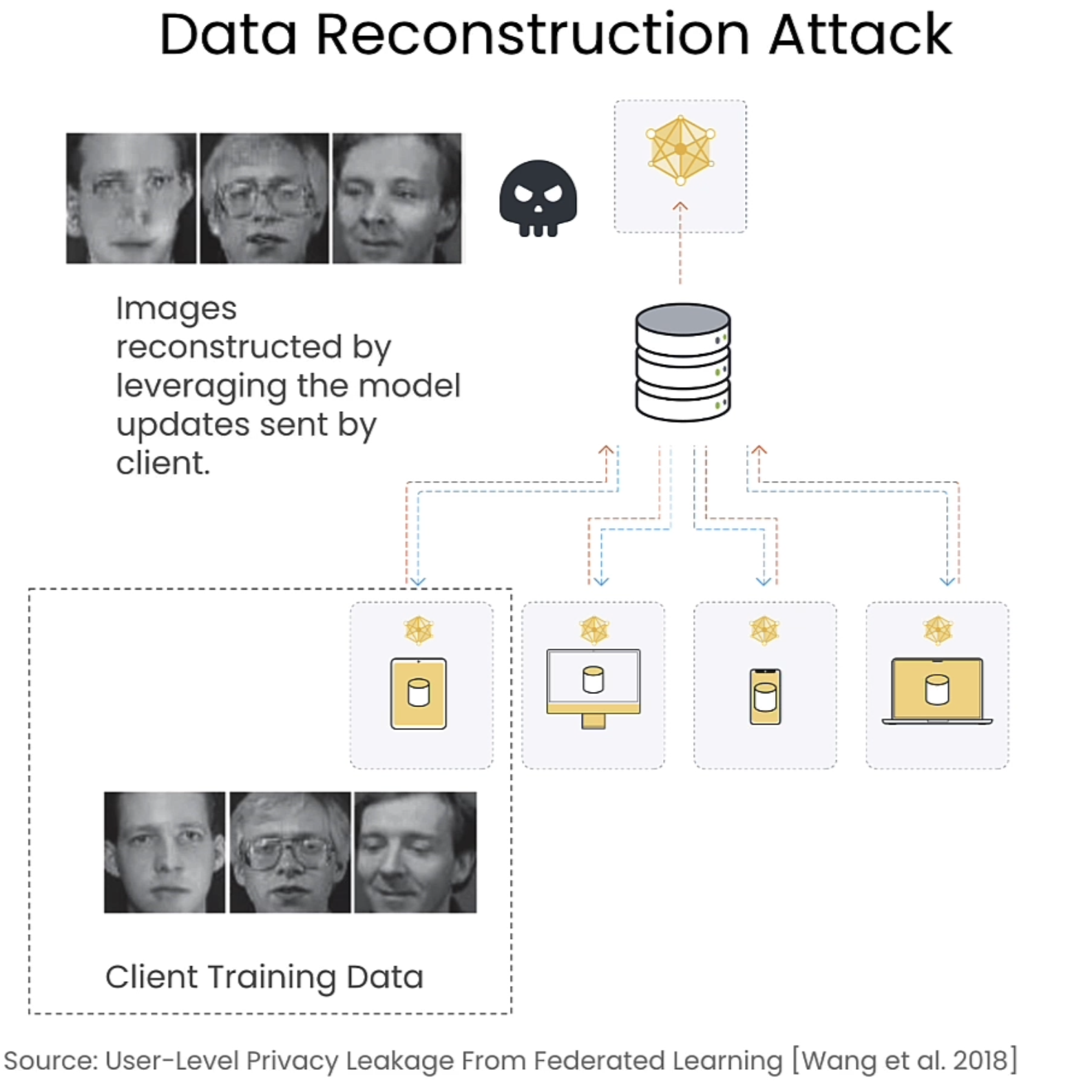
下面的图是一个相关例子,在server端重现了client训练数据的轮廓。
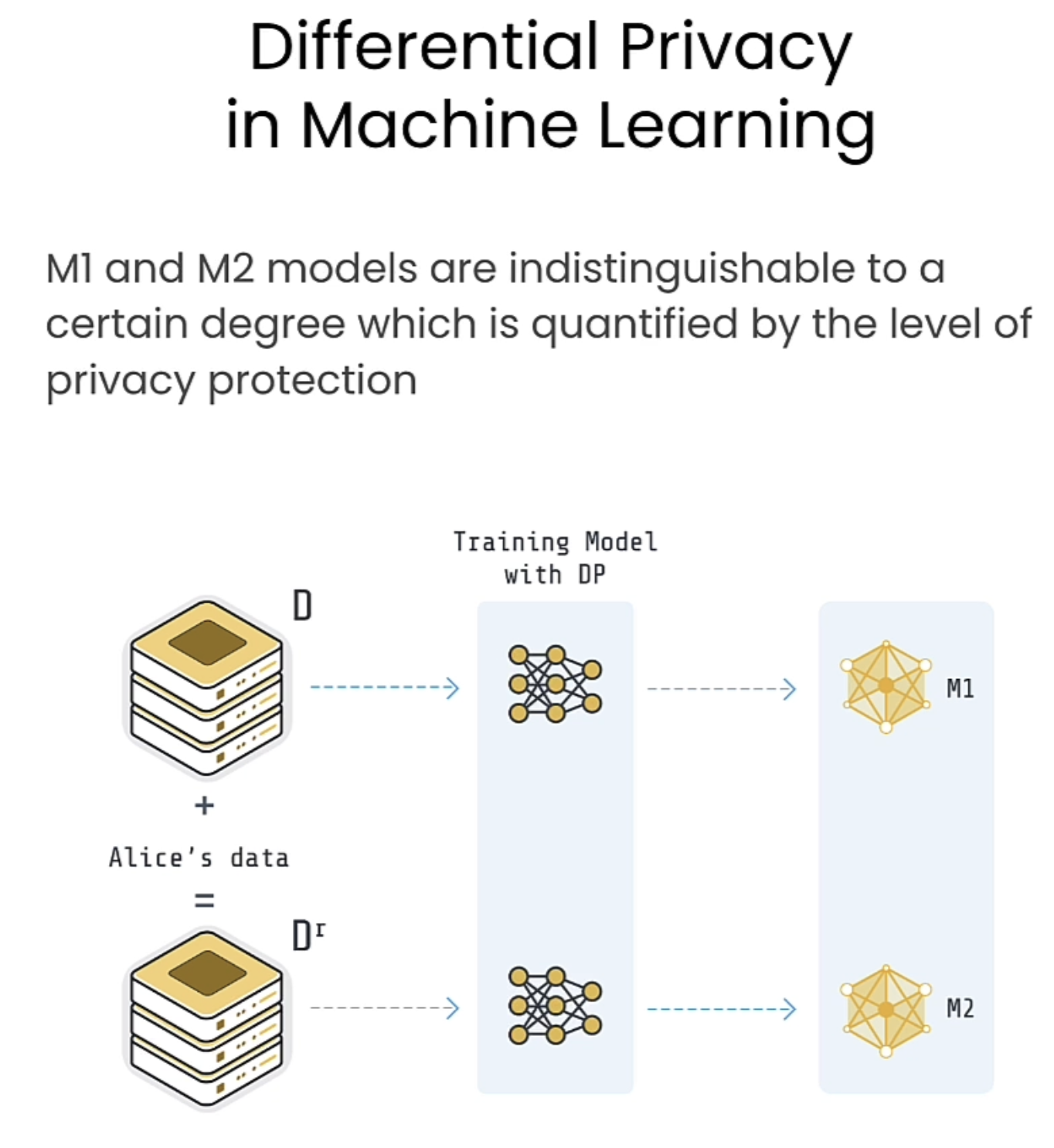
DP可以具体分为Central DP 以及Local DP。

Central DP
Local DP
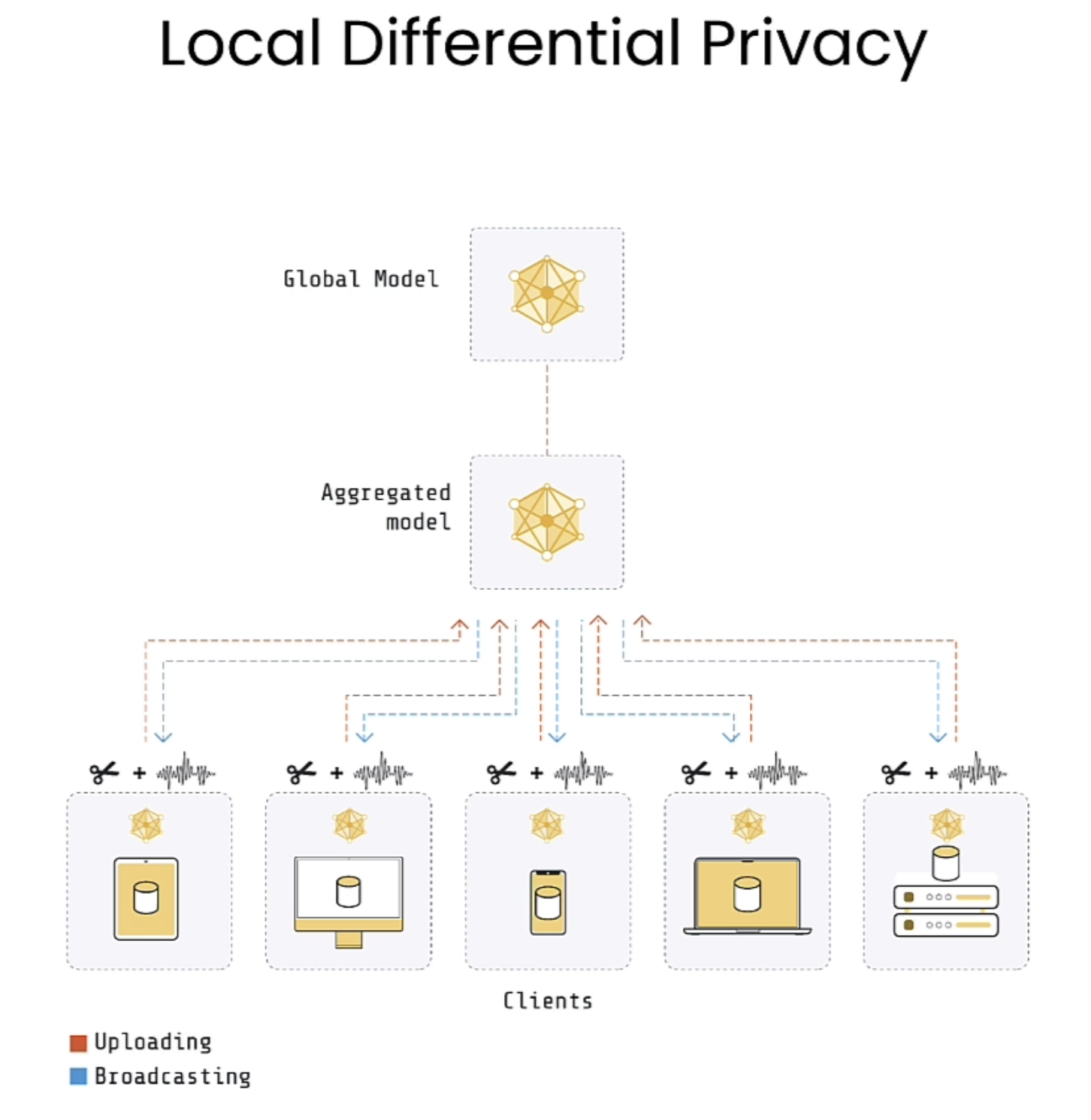
在这里可以看到图中有个剪刀,在机器学习和数据隐私中,“clipping”通常指的是梯度裁剪(Gradient Clipping),它是一种防止梯度爆炸或梯度消失的技术。在分布式学习或本地差分隐私(LDP)的上下文中,clipping 还有另一个意义:它用于限制上传到服务器的数据或梯度的大小,以确保它们不会泄露用户的私人信息。
具体来说,clipping的作用:
1. 梯度裁剪(Gradient Clipping):
• 在训练深度学习模型时,梯度值可能变得非常大,导致训练过程不稳定。梯度裁剪通过将梯度值限制在一个预定的范围内来避免这种情况,从而保持训练的稳定性。
2. 隐私保护中的Clipping:
• 在本地差分隐私中,数据会在上传之前进行裁剪。这意味着在上传到服务器之前,数据(如梯度或统计信息)会被限制在一个可接受的范围内。这样做可以减少数据泄露的风险,确保单个用户的私人信息不会被推断出来。
简单来说,clipping 是一种保护数据隐私和防止训练过程中数值问题的技术。
限制梯度的大小(clipping) 主要通过以下方式减少数据泄露的风险:
1. 防止过大信息泄露:
• 当模型的梯度值过大时,可能意味着某些客户端的数据对于模型的贡献异常突出。如果这些大梯度值上传到服务器,它们可能会透露出关于客户端数据的过多信息。例如,某个用户的输入可能对模型的训练产生了极大的影响,从而暴露了该用户的隐私信息(比如,个人偏好、行为模式等)。
• 通过裁剪梯度,可以将这些异常大的梯度限制在一个可控范围内,从而避免单个客户端的数据被过度暴露。
2. 平衡数据贡献:
• 在分布式学习中,各个客户端的数据量可能不同,因此某些客户端的梯度可能会对模型产生不成比例的影响。通过限制梯度大小,可以确保每个客户端对全局模型的贡献大致均衡,避免某个客户端的数据“主导”模型更新,从而减少泄露该客户端数据的风险。
3. 增加噪声的有效性:
• 在本地差分隐私中,除了裁剪梯度,通常还会为梯度添加噪声,以进一步模糊个人数据的影响。裁剪和加噪声的组合有助于保证即使某个客户端的梯度被上传,也很难从中恢复出关于该客户端的精确信息,因为裁剪限制了信息的泄漏程度,而噪声则进一步保护了隐私。
4. 减少极端值的影响:
• 一些极端的或异常的数据可能会对训练过程产生不合常理的影响。通过裁剪梯度,可以减少这些异常值对模型训练的干扰,进而降低其在训练过程中可能带来的隐私风险。
总之,限制梯度的大小通过减少模型对单个客户端数据的依赖性,增加了数据隐私的保护,确保即使在多人共享模型的环境下,个体的数据仍能保持私密性。
Bandwitdh
在本节介绍了Federated Learning所需带宽的计算方式。(这节github代码缺失pythia-14m),请到原课程去下载。

