github链接:https://github.com/MSzgy/How-Transformer-LLMs-Work
Introduction
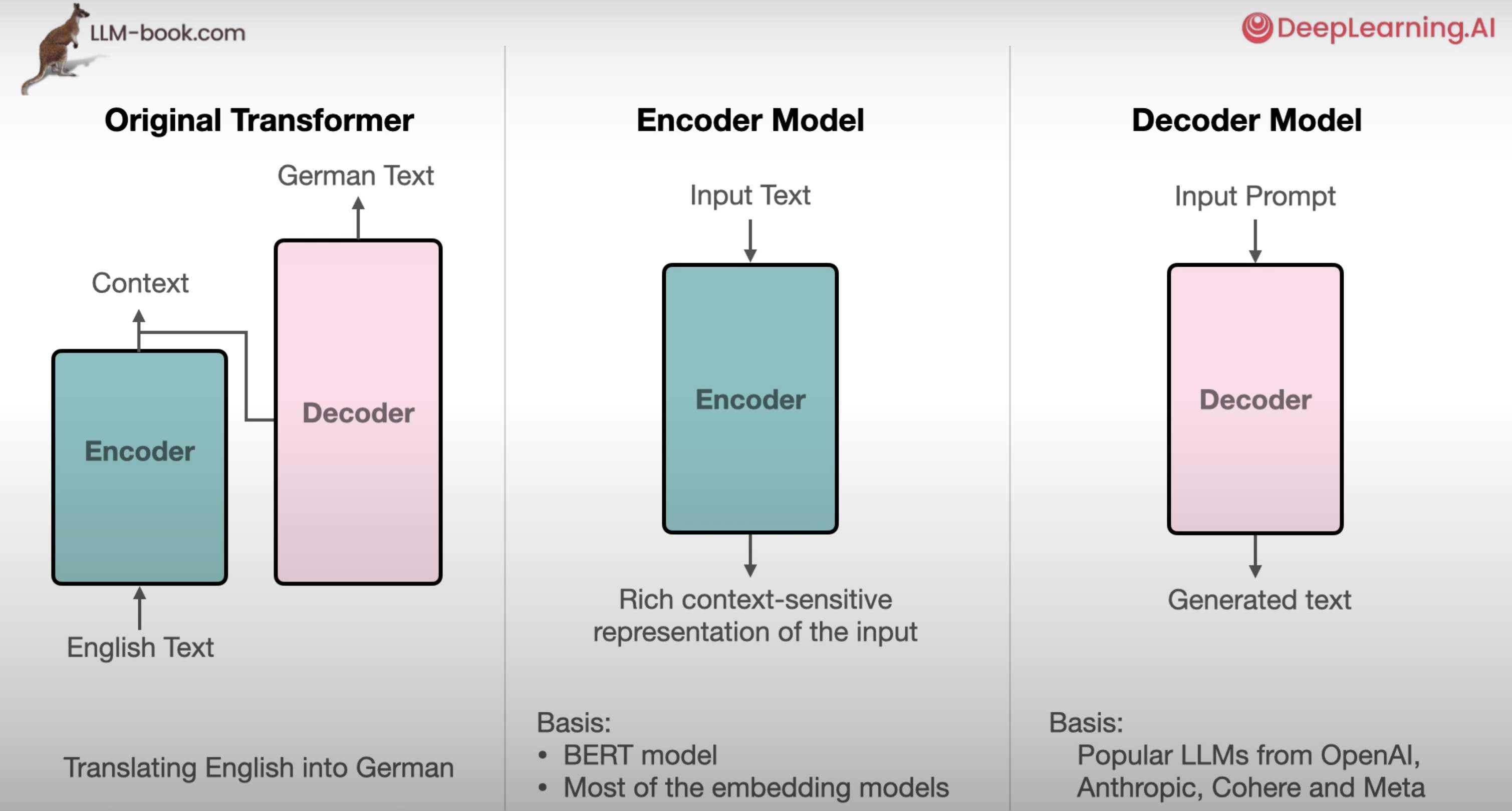
Transformer架构是当代LLM的基石,其来自于论文《Attention is all you need》。不同的LLM采用了Transformer中不同的架构。例如OpenAI就只采用了Decoder Model。
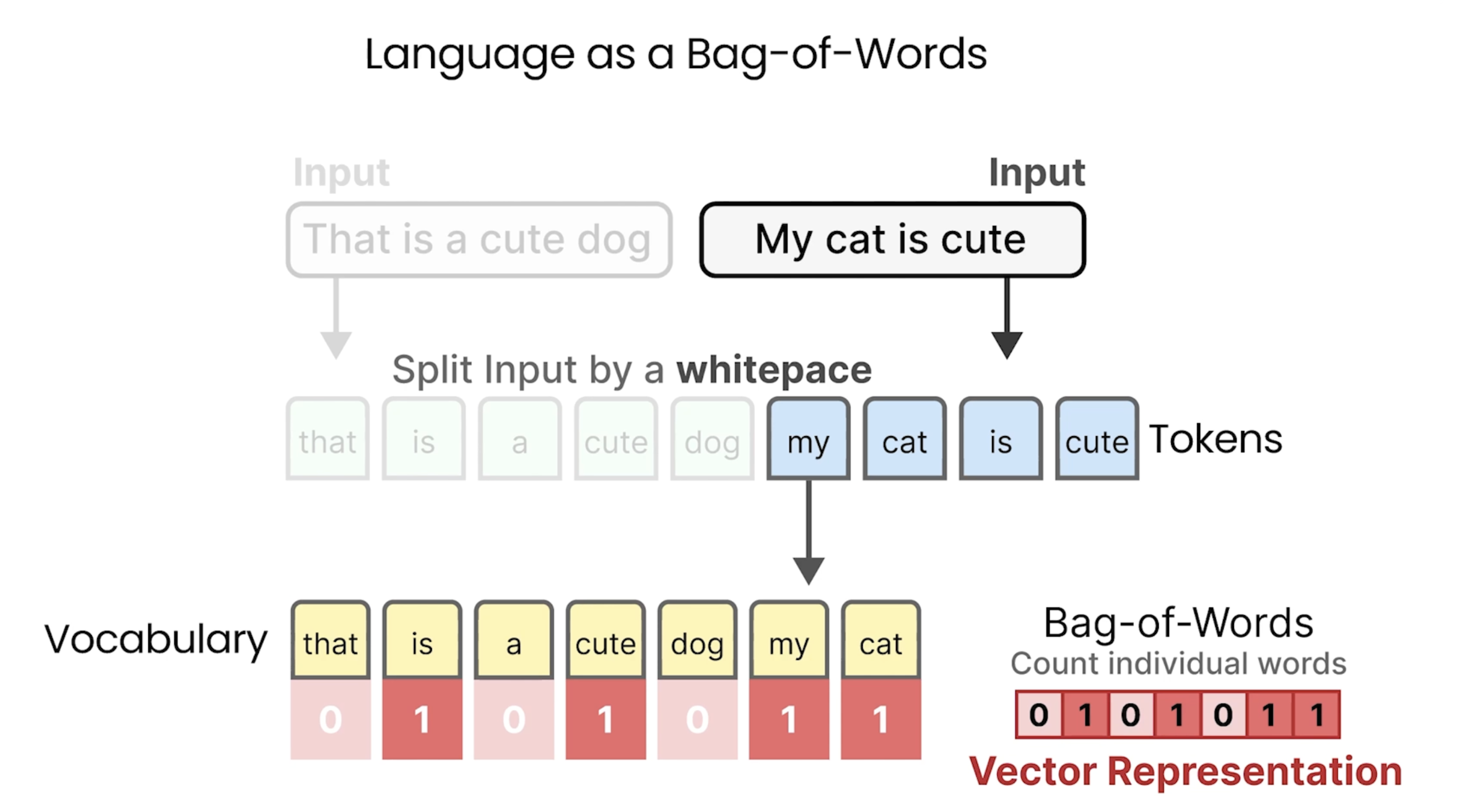
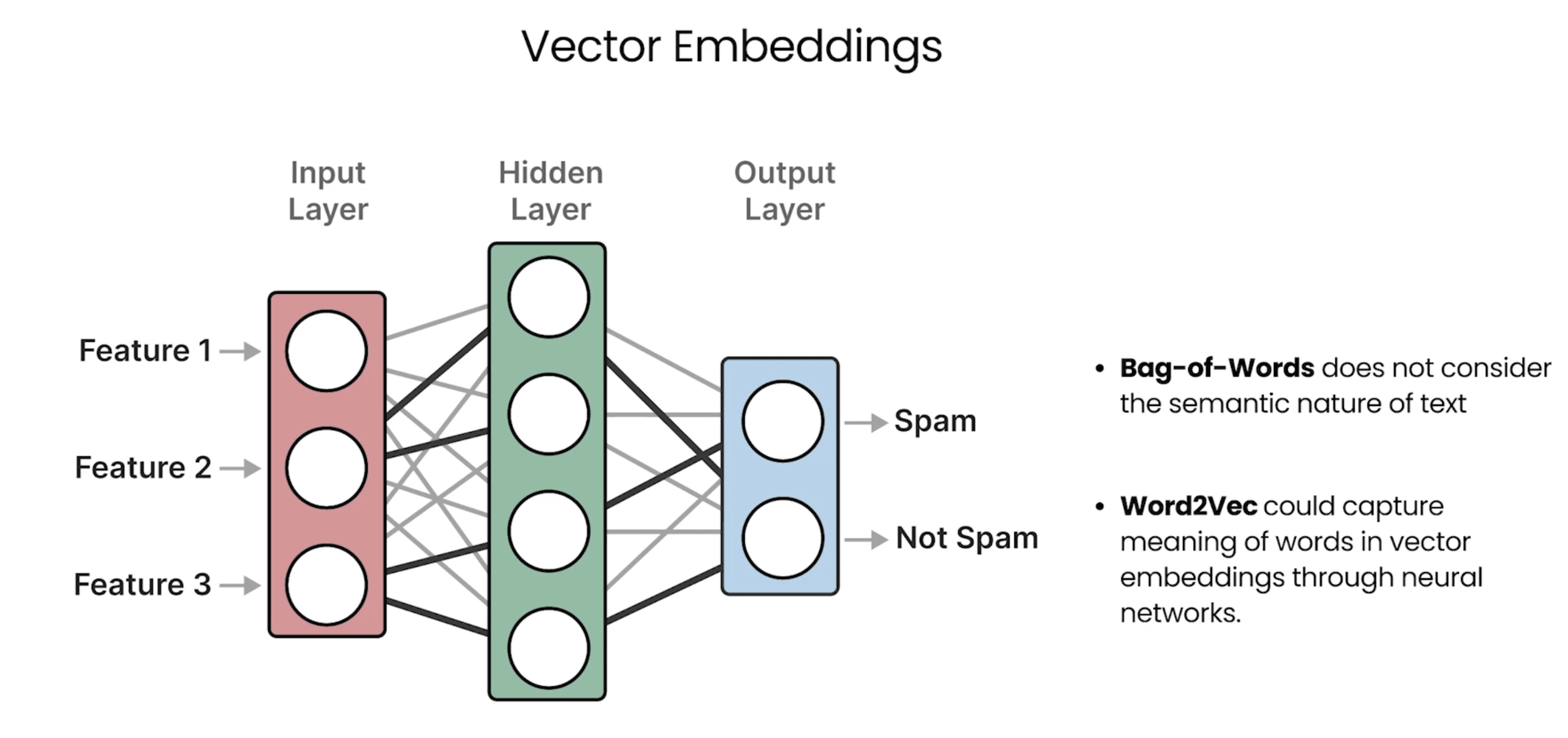
Understanding Language Models: Language as a Bag-of-Words
下面是词袋表示法,对于出现的每个单词,则统计出现的频次。
Understanding Language Models:(Word) Embeddings
词向量矩阵
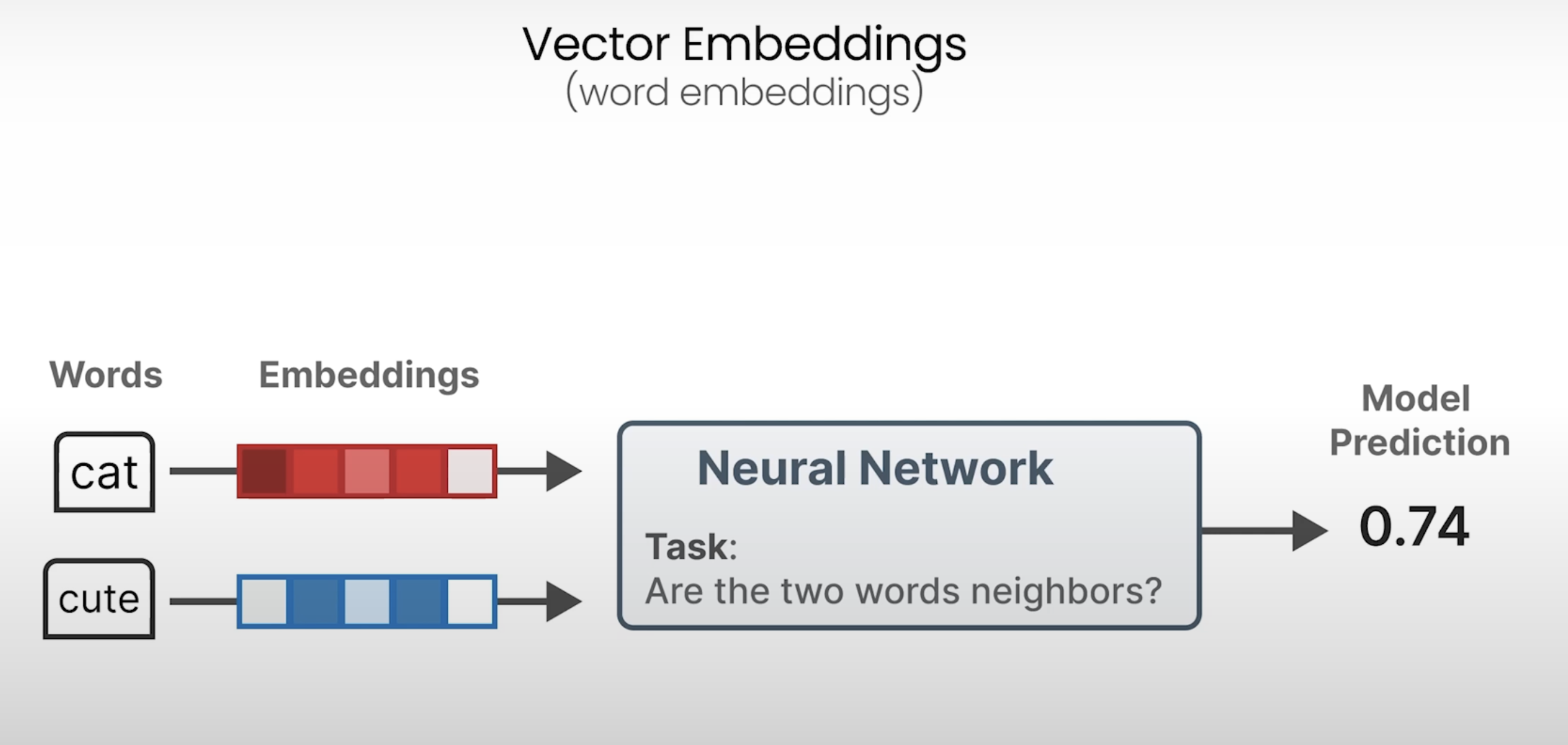
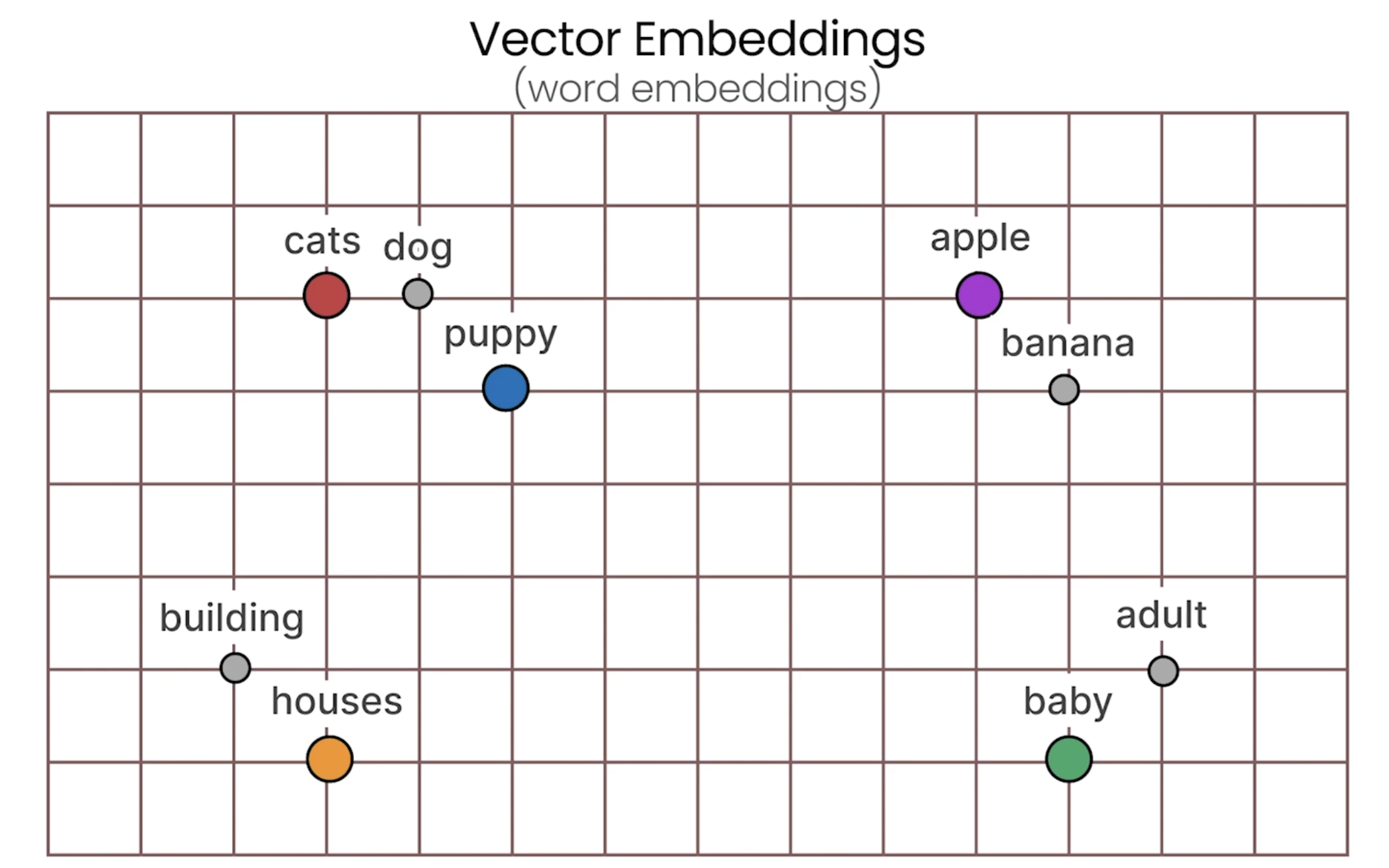
相似语义的词通过词向量表示在高维空间的表示也会相近。
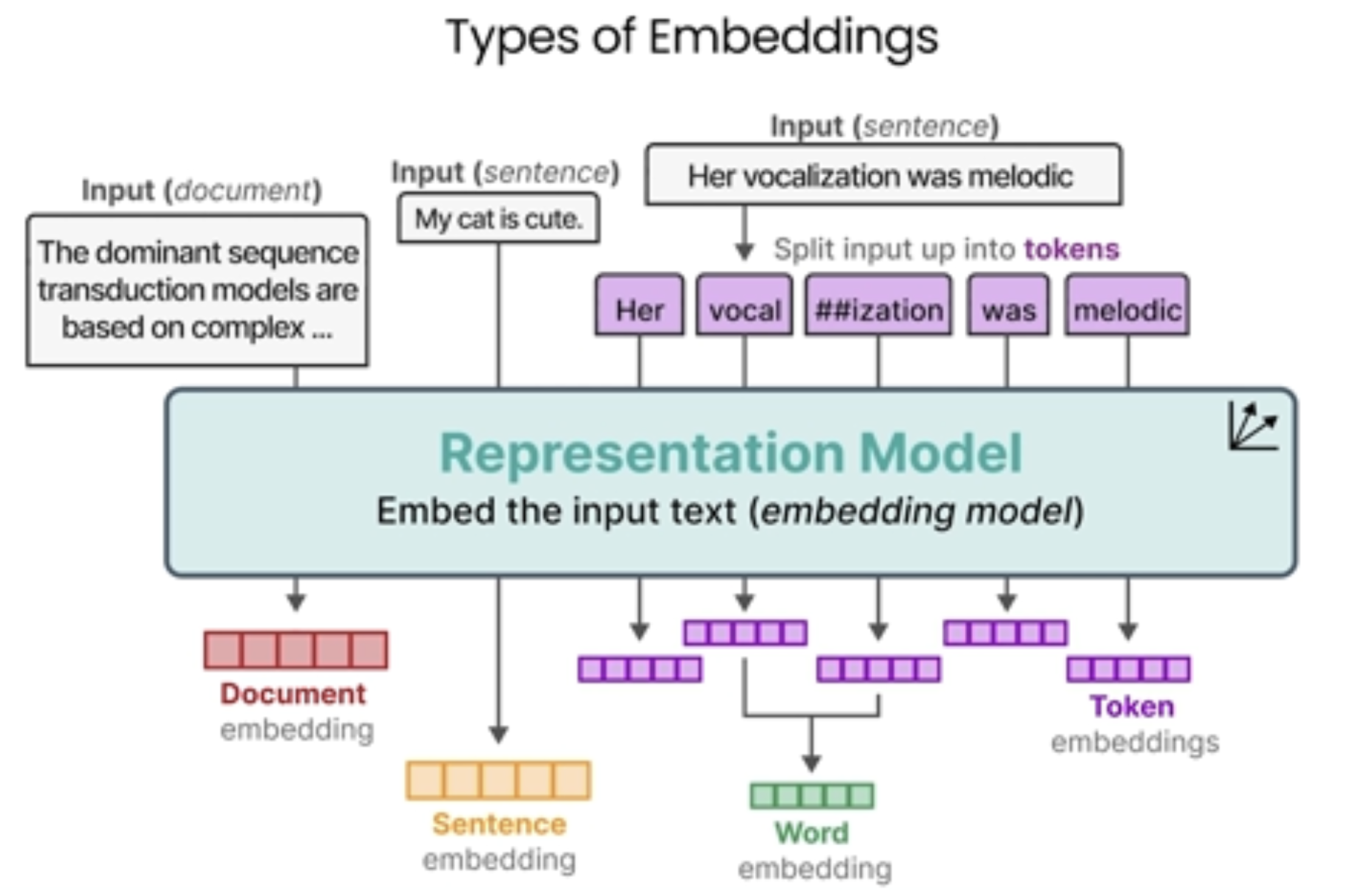
不同类型的Embeddings:
对于未出现的词则可以进行分词,用已经有的词来表示,如下面的例子:vocalization
对于句子,文档也可以直接形成embedding。
Understanding Language Models: Encoding and Decoding Context with Attention
Word2Vec只能静态标识某个词,却没考虑词的Context.
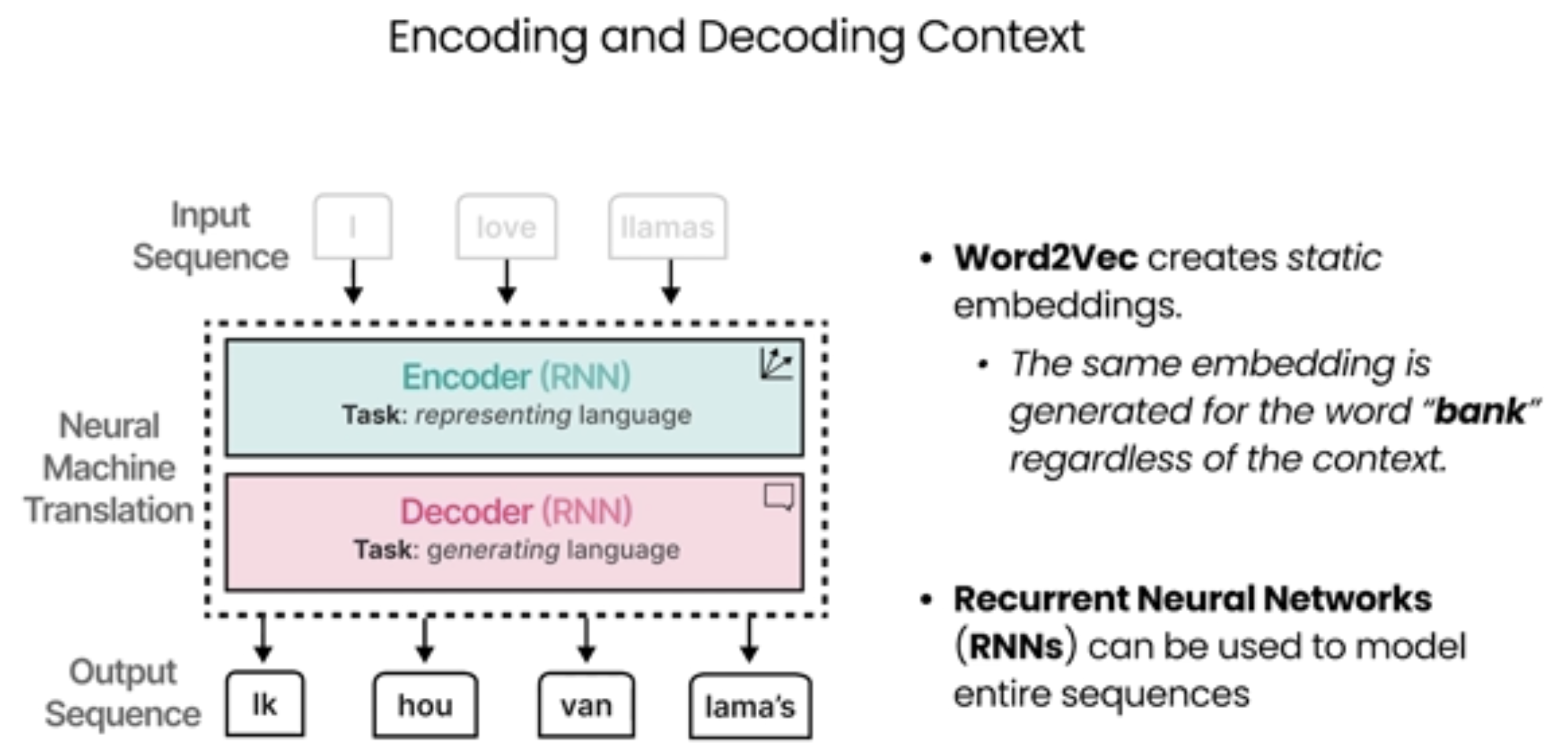
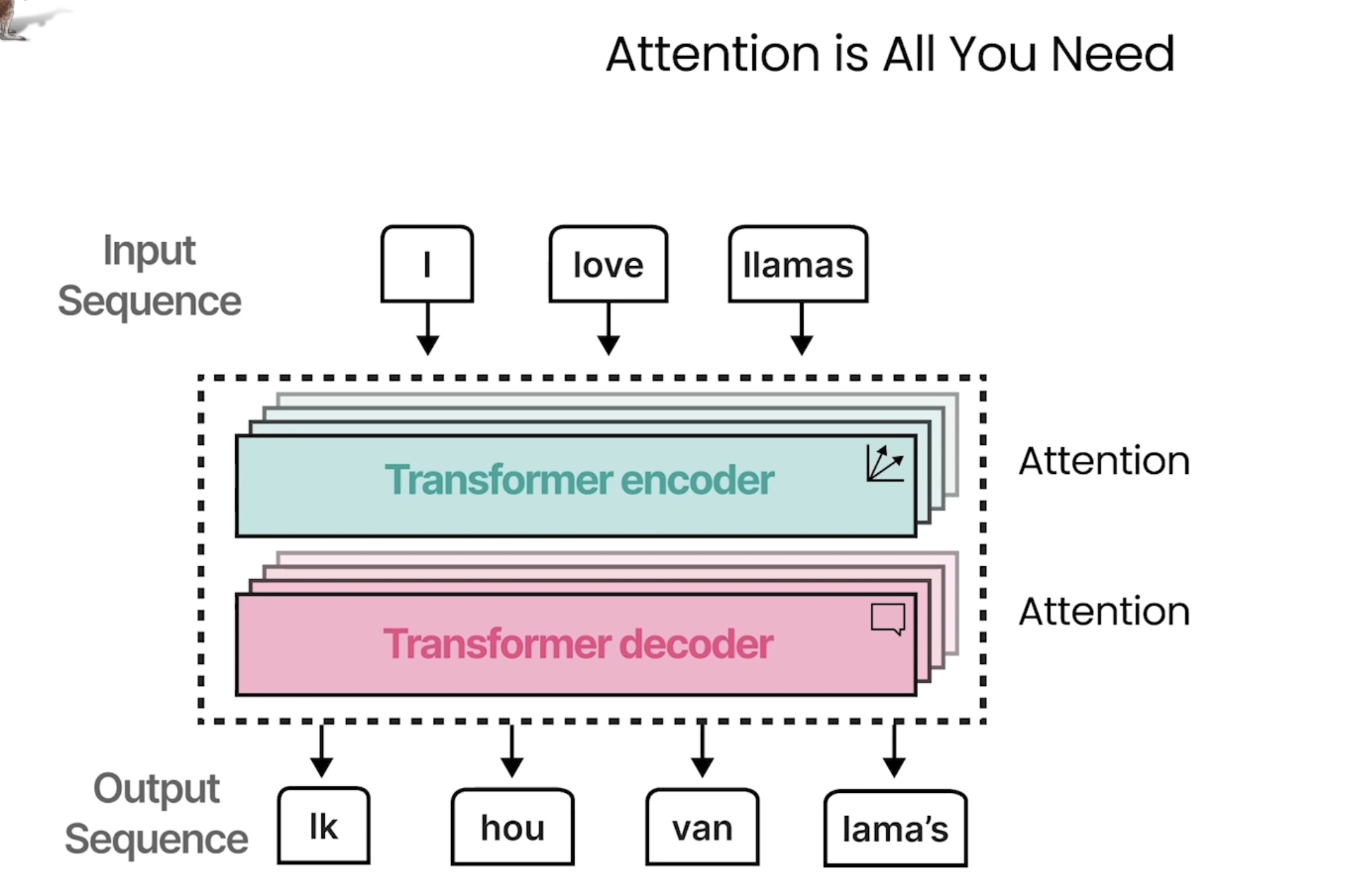
下面是翻译任务的过程,会将英文翻译成德语,这种过程是自回归的。
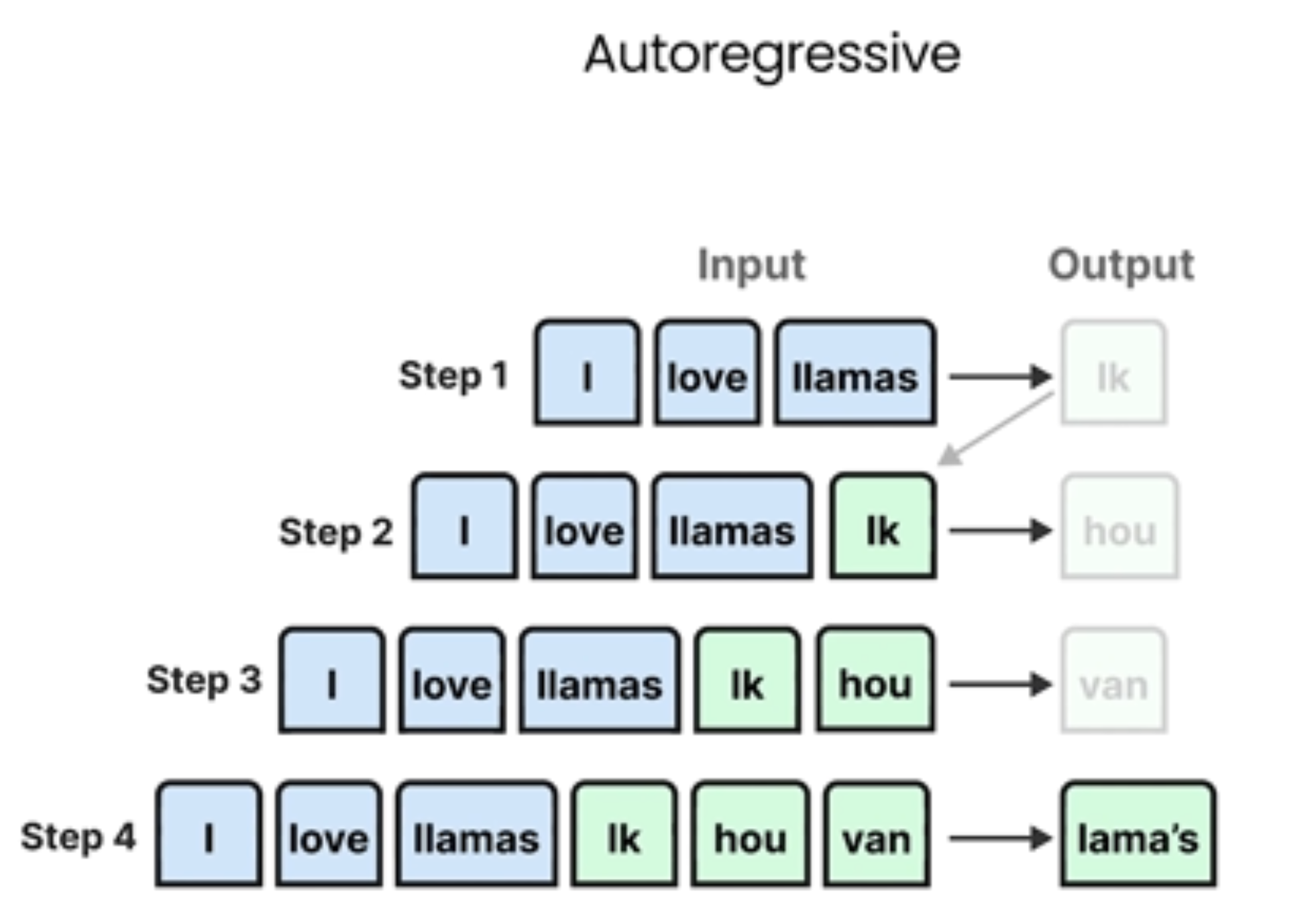
在这个过程中,采用了RNN作为编码器及解码器:
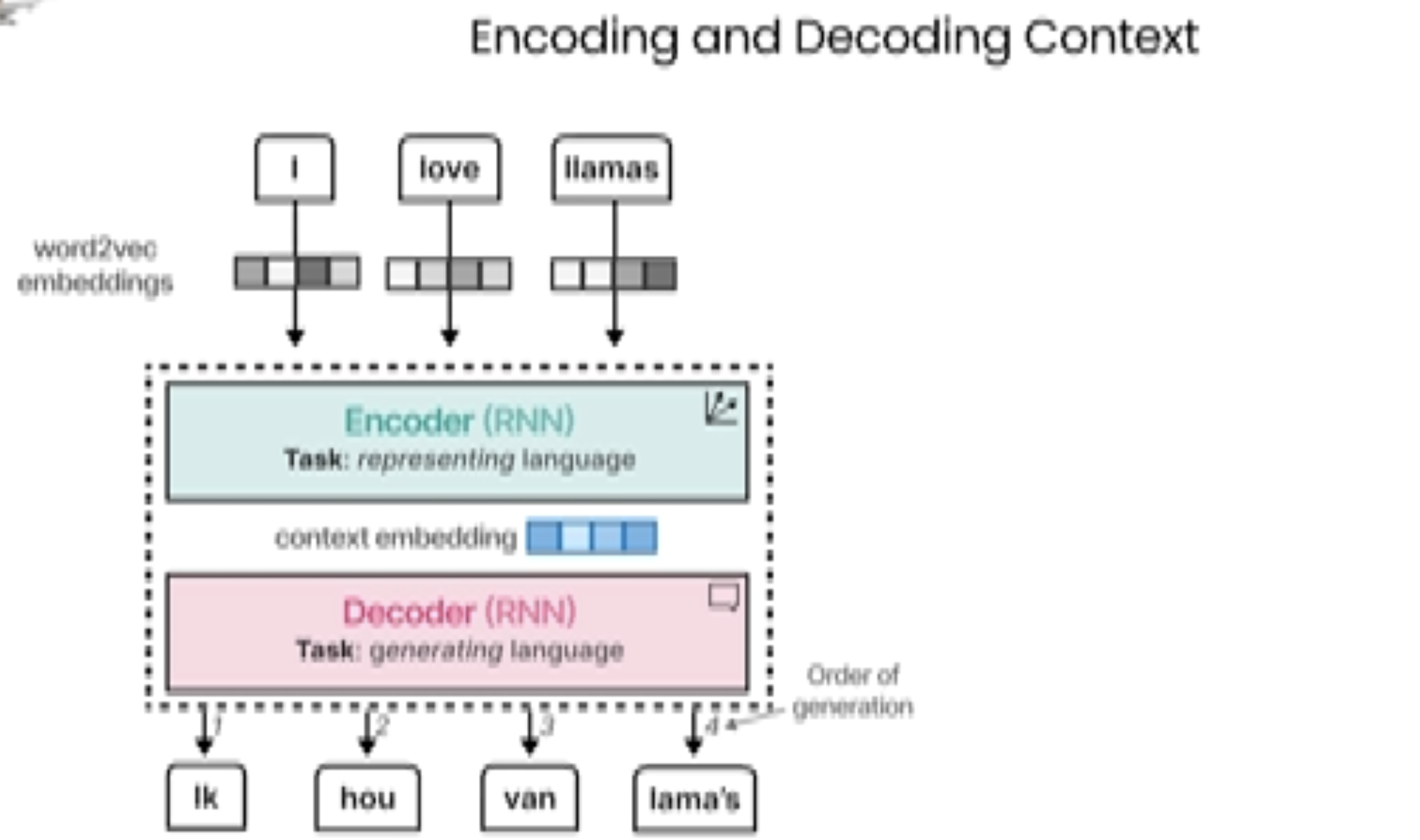
对于上面模型的解释说明:
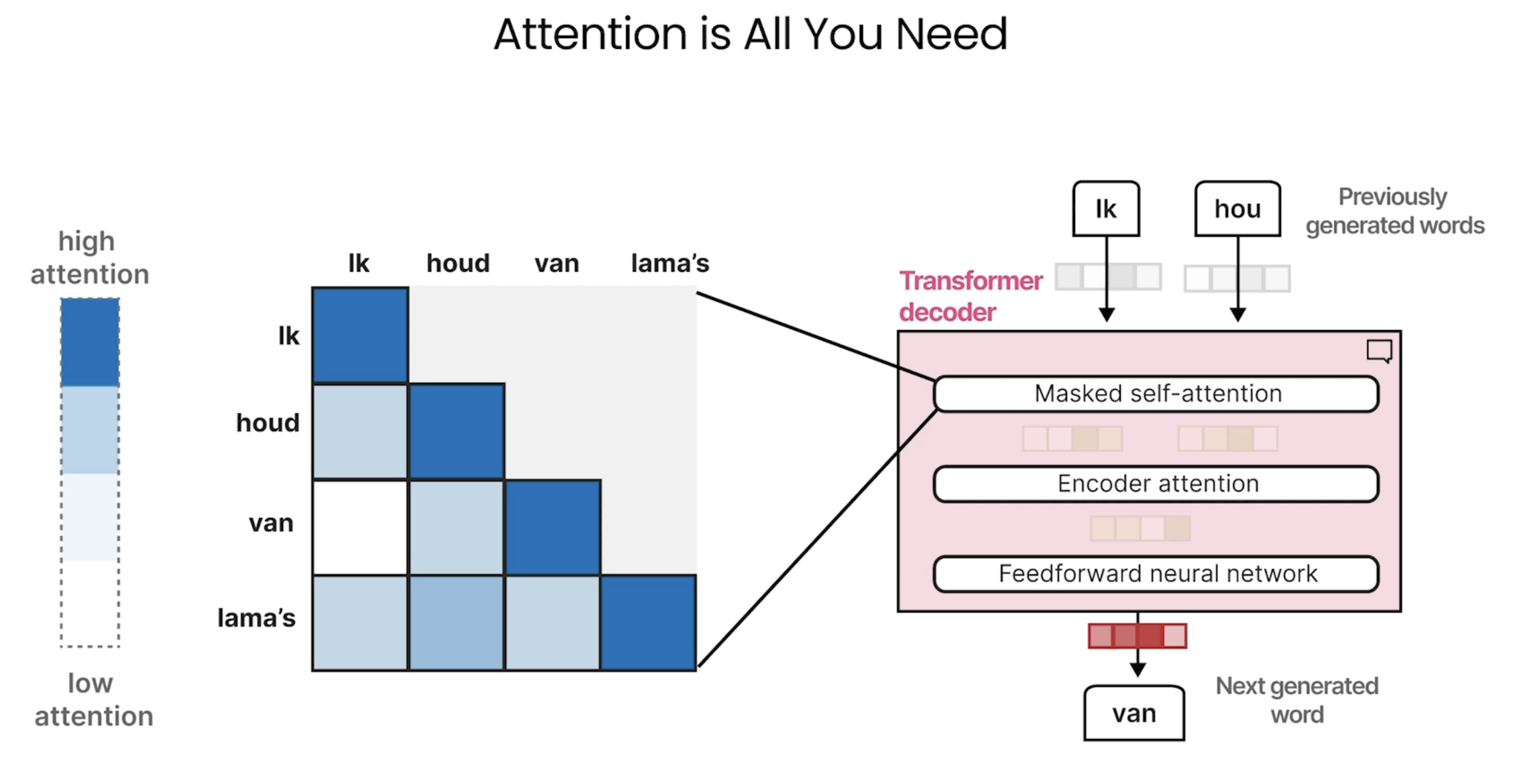
这张图展示了一个编码器-解码器(Encoder-Decoder)模型的工作流程,通常用于自然语言处理(NLP)任务,特别是在机器翻译中。图中的内容涉及了编码和解码的过程:
1. 输入:
• 图中展示了三个词:“I”, “love”, “llamas”,这些词通过word2vec嵌入(word embeddings)转换为向量表示。这是 NLP 中常见的一种方法,用于将每个单词映射到一个高维空间中的向量。
2. 编码器(Encoder):
• 编码器部分使用**循环神经网络(RNN)**来处理输入数据(单词的向量表示)。
• 任务:编码器的主要任务是表示语言,即它接收输入单词的嵌入向量,并生成一个“上下文嵌入”表示,这个表示包含了输入序列的语义信息。
3. 上下文嵌入(Context Embedding):
• 这个上下文嵌入由编码器产生,并传递到解码器。它代表了整个输入句子的语义信息,帮助解码器生成合理的输出。
4. 解码器(Decoder):
• 解码器也是一个循环神经网络(RNN),负责根据编码器提供的上下文信息生成目标输出。
• 任务:解码器的任务是生成语言,即从上下文嵌入中生成目标语言的单词。
• 图中展示了解码器生成的单词序列,如:“lk”, “hou”, “van”, “lama’s”,这些单词是通过解码器逐步生成的,按照生成的顺序排列。
5. 顺序生成(Order of Generation):
• 图中标明了解码器生成单词的顺序。这表明,解码器会根据上下文信息按顺序生成每个单词,直到生成完整的句子或序列。
总结来说,这个图描述了一个典型的序列到序列(Seq2Seq)模型的工作原理,通常用于任务如机器翻译,语音识别等。通过编码器将输入序列转化为上下文嵌入,解码器则根据这些信息生成输出序列。
这个编码器-解码器模型,尤其是基于RNN的架构,尽管在自然语言处理任务中取得了一些成功,但也存在一些明显的缺陷:
1. 长距离依赖问题
• 缺陷:RNN 在处理长序列时,容易遇到“梯度消失”或“梯度爆炸”的问题,导致它很难捕捉到长距离依赖关系(例如,句子开头的词与结尾的词之间的关系)。这意味着,当输入序列较长时,模型可能无法有效地记住早期信息,影响最终的生成效果。
• 解决方案:为了解决这个问题,研究者提出了改进的RNN变种,如长短期记忆网络(LSTM)和门控循环单元(GRU),它们通过引入门控机制来更好地捕捉长距离依赖。
2. 信息丢失
• 缺陷:RNN 在对长文本进行编码时,所有的输入信息都会被压缩成一个固定大小的上下文向量,这个过程可能会导致大量信息丢失。特别是在长句子中,编码器可能无法捕捉到所有重要的语义细节,影响解码器生成的输出质量。
• 解决方案:这种缺陷在Transformer架构中得到改善,Transformer使用自注意力机制(self-attention)来处理长序列,避免了固定上下文向量的问题。
3. 计算效率低
• 缺陷:RNN 是逐步计算的,意味着它必须一步一步地处理输入序列中的每个词,因此在处理长序列时效率较低。这使得RNN在处理大规模数据时,尤其是需要实时反馈的任务中效率较低。
4. 生成质量
• 缺陷:由于编码器-解码器模型只通过一个固定大小的上下文向量来生成整个输出,生成的文本可能缺乏多样性和流畅度,尤其在较复杂或长篇的生成任务中,输出往往重复或不自然。
• 解决方案:Attention机制和后来的Transformer模型通过引入动态的上下文信息选择,使得每个生成的单词都能根据输入的每个部分进行调整,改进了生成质量。
5. 无法处理多模态输入
• 缺陷:传统的RNN编码器-解码器架构通常仅处理单一类型的输入(如文本),对于图像、视频等多模态输入,处理能力有限。
• 解决方案:现代的多模态学习方法(例如CLIP、Vision Transformers)和多模态Transformer架构能够同时处理图像、文本等多种信息类型,提升模型的表达能力。
6. 推理时的逐步生成(逐步依赖)
• 缺陷:在生成输出时,解码器是逐步生成的,每生成一个词就需要依赖之前生成的词。这样做有时会导致错误的传播,特别是在生成较长文本时,早期的错误会影响到后续的生成质量。
• 解决方案:Transformer模型(特别是BERT和GPT等预训练模型)通过大规模的预训练和更高效的生成策略(如掩蔽语言模型、因果语言模型)来改善这一点。
总结
虽然基于RNN的编码器-解码器模型在一些任务中表现不错,但其长距离依赖、信息丢失和计算效率低等缺陷使得它在处理复杂任务时面临挑战。随着技术的发展,Transformer架构已成为解决这些问题的主流方法,提供了更好的性能和灵活性。
下面是采用Attention机制的方式:
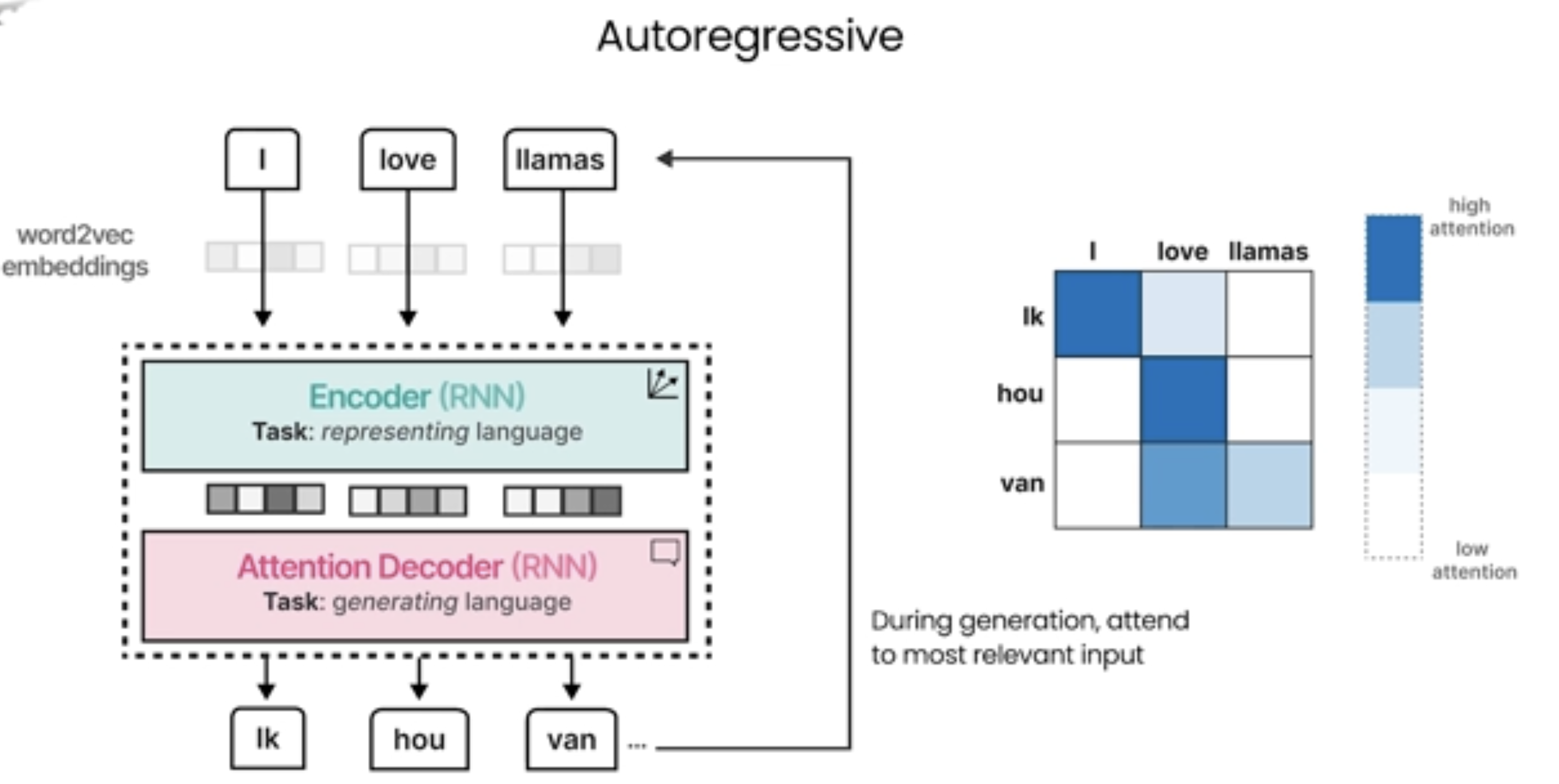
https://zhuanlan.zhihu.com/p/150294471
采用 注意力机制(Attention Mechanism) 的 Seq2Seq 模型会将 编码器所有隐藏层 的输出传递给 解码器,而不仅仅是传统模型中的最终隐藏状态。这是注意力机制相较于传统 Seq2Seq 模型的一个重要改进。
传统 Seq2Seq 与 Attention 的区别:
• 传统 Seq2Seq 模型(没有注意力机制):
• 在没有注意力机制的情况下,编码器的任务是将整个输入序列压缩成一个固定长度的上下文向量(即,最后一个时间步的隐藏状态)。解码器只接收这个最终的上下文向量,来生成输出序列。这种方法存在一定的局限性,尤其是在处理长序列时,因为最终隐藏状态无法完美地捕捉整个输入的所有信息。
• 带有 Attention 的 Seq2Seq 模型:
• 在引入了注意力机制之后,解码器不再只依赖编码器的最后一个隐藏状态(最终的上下文向量)。相反,它会利用编码器所有时间步的隐藏状态(每个输入词对应的隐藏层输出),通过注意力机制来动态地选择哪些输入的部分(哪些隐藏状态)对当前生成的输出最相关。
具体来说:
1. 编码器:编码器(如 RNN、LSTM 或 GRU)处理输入序列,并在每个时间步(每个单词)生成一个隐藏状态。对于输入序列中的每个单词,编码器会产生一个隐藏状态 (每个 对应输入序列中的一个单词)。
2. 注意力机制:解码器使用这些隐藏状态(而不是仅仅最后一个隐藏状态)作为 注意力机制的输入。注意力机制通过计算解码器的查询向量(Query)和编码器的隐藏状态(Keys)之间的相似度,来决定哪个隐藏状态应该对当前生成的单词产生最大的影响。
3. 解码器:解码器根据编码器所有隐藏状态的加权组合(加权后的上下文向量)生成下一个单词。加权组合的权重由注意力机制计算得出,表示每个输入单词对当前解码步骤的相关性。
注意力机制的工作流程:
1. 编码器输出:
编码器处理输入序列后,输出每个时间步的隐藏状态 ,这些隐藏状态包含了输入序列的语义信息。
2. 计算注意力得分:
对于解码器的每个时间步,解码器会生成一个查询向量(Query),通常是解码器当前的隐藏状态。然后,注意力机制会将这个查询向量与编码器的每个隐藏状态(即每个输入单词的表示)进行比较,计算相似度得分(通常是点积或其他相似度度量)。
3. 生成注意力权重:
使用 softmax 函数将这些得分转化为权重,这些权重表示每个输入单词对当前输出单词的相关性。
4. 加权求和:
将编码器的隐藏状态按注意力权重加权求和,得到一个加权的上下文向量,这个向量结合了输入序列中最相关的信息。
5. 解码器生成输出:
解码器将这个加权上下文向量与当前解码器的状态结合,生成下一个输出单词。
举个简单例子:
假设输入句子是:“我 爱 编程”,目标输出是:“I love programming”。
步骤:
1. 编码器生成隐藏状态:
• 对于输入序列中的每个单词(“我”,“爱”,“编程”),编码器会生成一个对应的隐藏状态:
2. 解码器生成输出:
• 假设解码器在生成“I”时,它会用这些隐藏状态来帮助生成下一个单词。
• 解码器会计算当前查询(Query)与每个编码器的隐藏状态之间的相似度(例如,生成“I”时,可能更关注“我”这个词的隐藏状态)。
3. 计算注意力权重:
• 计算得出每个隐藏状态的注意力权重。例如,假设生成“I”时,注意力机制给“我”的权重较高,而对“爱”和“编程”的权重较低。
4. 加权求和:
• 将编码器的隐藏状态按照注意力权重加权求和,得到一个加权的上下文向量。这个上下文向量会被传递给解码器,用于生成下一个单词。
5. 生成下一个单词:
• 解码器根据加权上下文向量生成下一个单词(例如,“love”)。
总结:
在带有 注意力机制 的 Seq2Seq 模型中,编码器的所有隐藏状态都会传递给解码器。解码器使用这些隐藏状态,通过注意力机制动态地决定每个输入单词对当前生成单词的贡献。这种方式大大增强了解码器的灵活性,使得模型可以更好地处理长序列和长距离依赖,生成更准确和流畅的输出。
Autoregressive(自回归)在模型中的含义
自回归模型是指模型在生成输出时,当前步骤的输出依赖于先前步骤的输出。这个概念在多个领域有应用:
在机器学习和深度学习中
语言模型:如GPT系列,它们根据已生成的文本预测下一个词或标记
序列生成:模型一次生成一个元素,每个新元素都依赖于之前生成的序列
生成过程:"从左到右"的方式,每次预测一个新的token并将其作为下一步的输入
技术特点
每次预测都依赖于模型自己之前的输出
生成是按顺序进行的(不能并行生成整个序列)
能够捕捉序列中的长期依赖关系
常见应用场景
文本生成
时间序列预测
语音合成
图像生成(如PixelCNN)
与之相对的是非自回归模型(non-autoregressive models),它们可以一次生成整个序列,不需要依赖之前的输出。
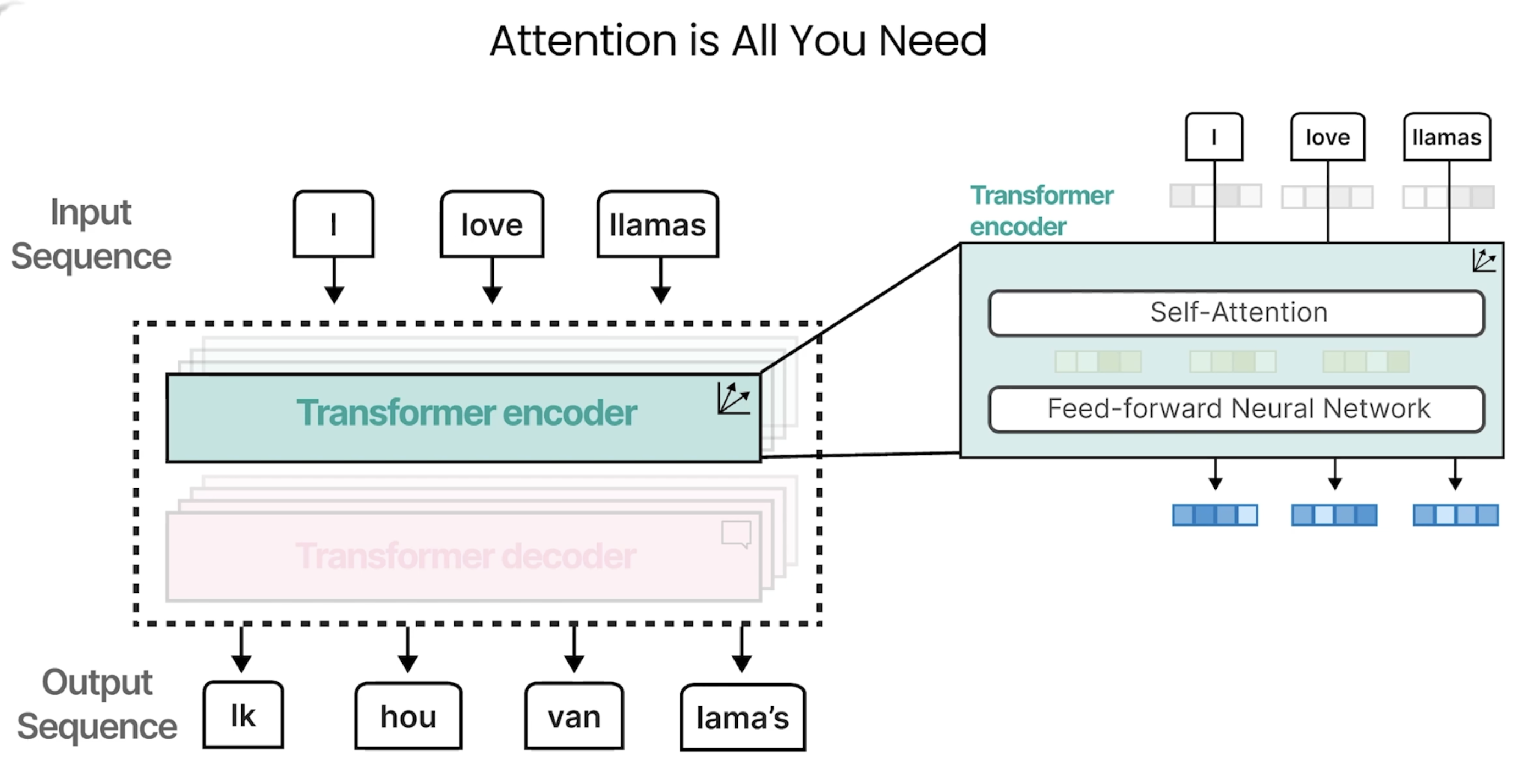
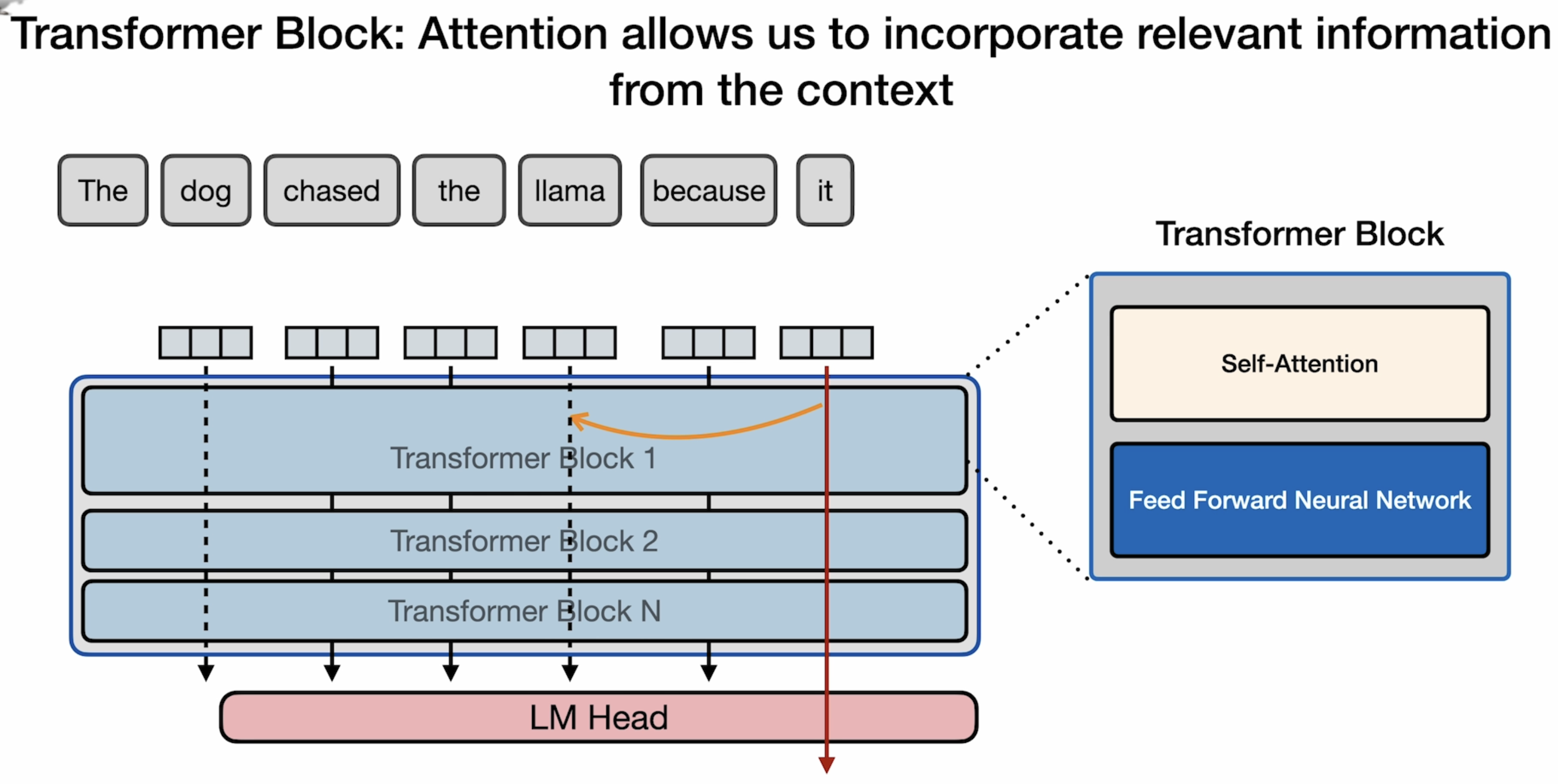
Understanding Language Models: Transformers
在本节介绍了《Attention is all you need》这篇论文提出的Transformer架构。它同样具有encoder与decoder结构。
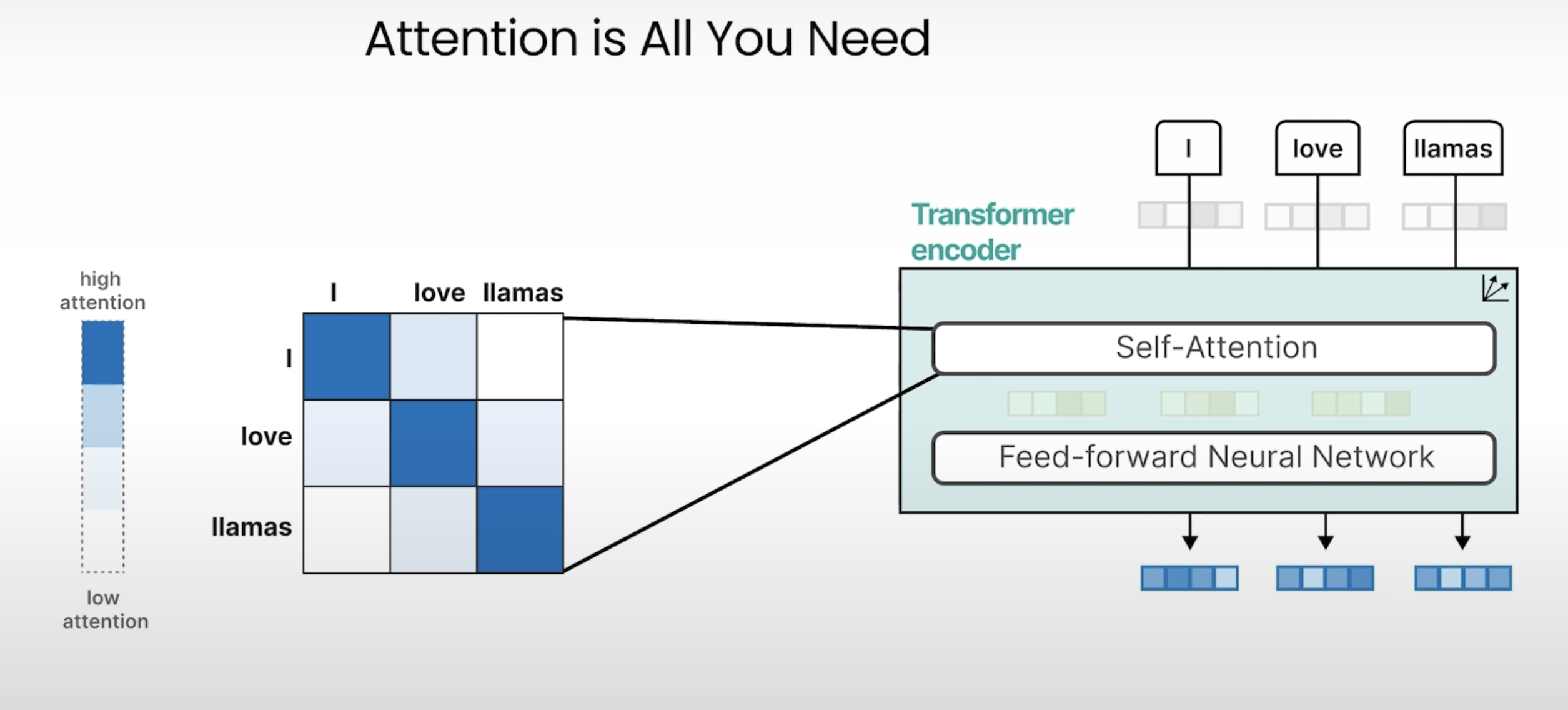
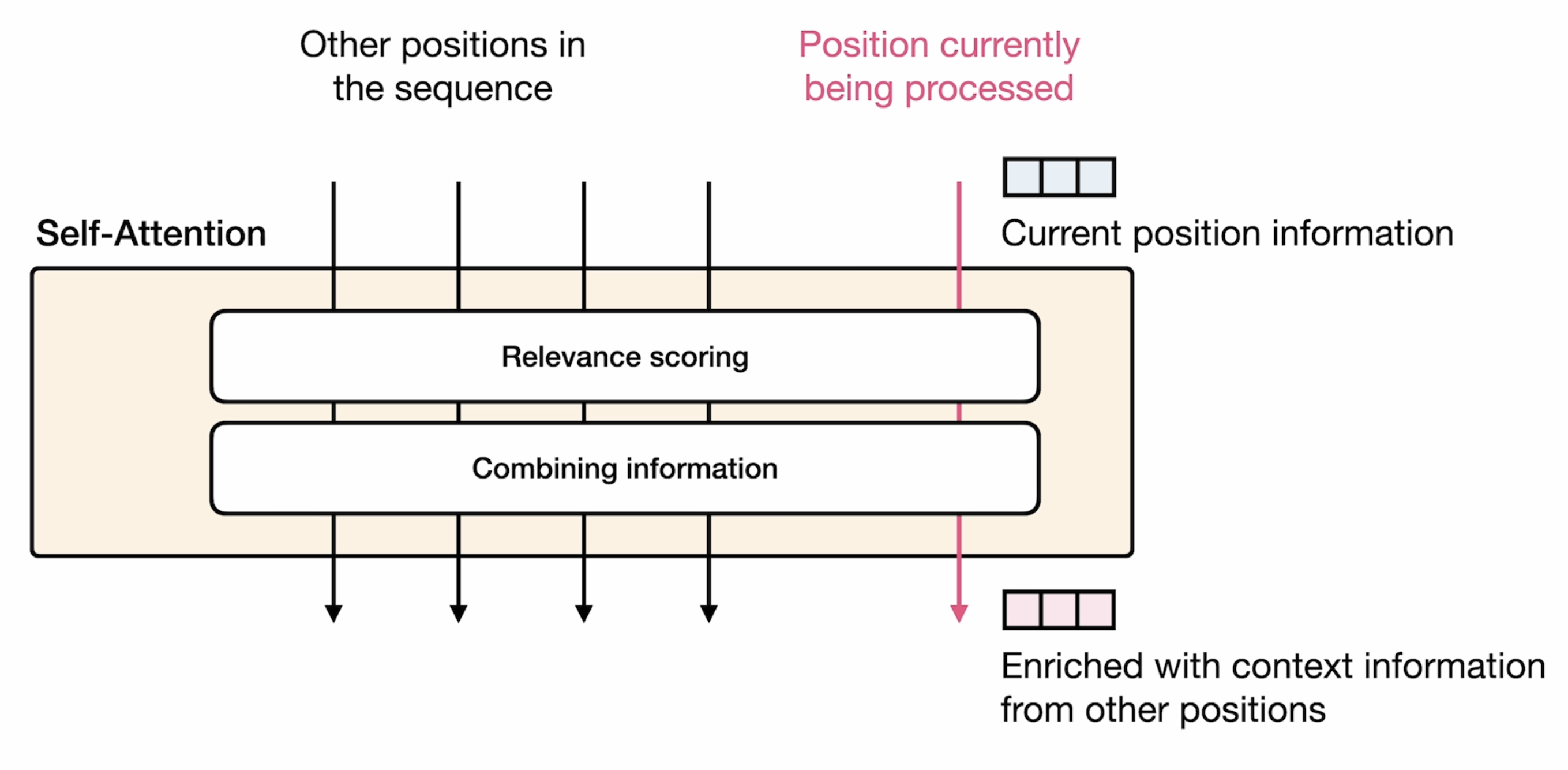
这里采取了self-Attention机制:
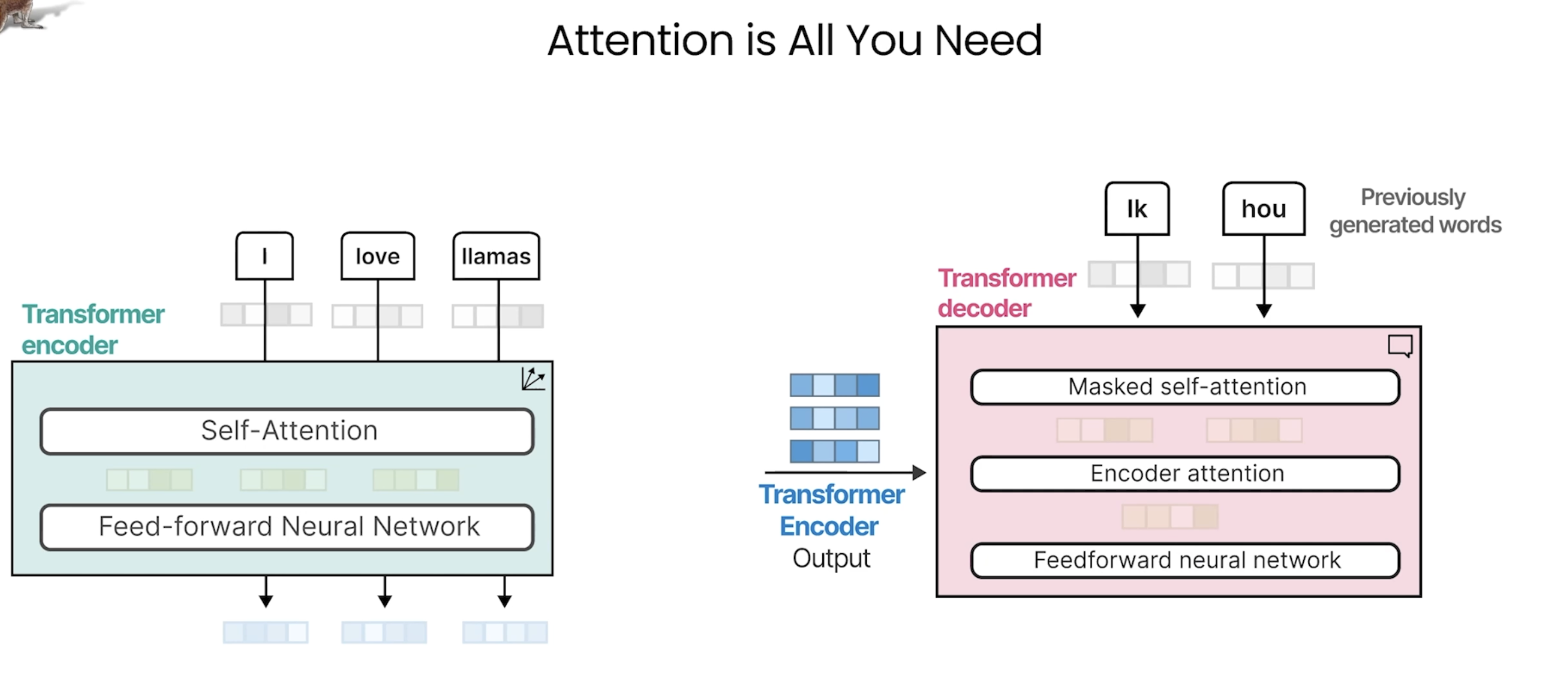
### 1. 解码器的整体结构
解码器由多个相同的层(Decoder Layer)堆叠而成,每个层包含以下子模块:
1. 掩码多头自注意力层(Masked Multi-Head Self-Attention)
2. 交叉注意力层(Cross-Attention,Encoder-Decoder Attention)
3. 前馈网络(Feed-Forward Network, FFN)
每个子模块后接**残差连接(Residual Connection)**和**层归一化(Layer Normalization)**。
---
### 2. 输入处理
解码器的输入分为两部分:
- 目标序列(Target Sequence):在训练时是真实的输出序列(如翻译后的句子),在推理时是逐步生成的序列。
- 编码器输出(Encoder Output):编码器对源序列(如输入文本)的上下文表示。
#### 输入处理步骤:
1. 嵌入层(Embedding):将目标序列的词元转换为向量。
2. 位置编码(Positional Encoding):添加位置信息(与编码器相同的方式)。
3. 输入嵌入 + 位置编码:得到解码器的初始输入。
---
### 3. 解码器层的详细组件
#### 3.1 掩码多头自注意力层(Masked Multi-Head Self-Attention)
- 作用:让解码器关注目标序列中已生成的词元(防止信息泄漏)。
- 掩码机制:
- 在自注意力计算时,对未来的词元进行遮挡(设置为负无穷)。
- 例如,生成第 \( t \) 个词时,只能看到第 \( 1 \) 到 \( t-1 \) 个词。
- 数学实现:
attention_scores = Q @ K.T / sqrt(d_k)
mask = torch.tril(torch.ones(seq_len, seq_len)) # 下三角掩码
masked_scores = attention_scores.masked_fill(mask == 0, -1e9)
attention_weights = softmax(masked_scores)
output = attention_weights @ V#### 3.2 交叉注意力层(Cross-Attention)
- 作用:让解码器关注编码器的输出,将源序列信息融合到目标序列生成中。
- 输入来源:
- Query(Q):来自解码器的当前表示(掩码自注意力层的输出)。
- Key(K)和 Value(V):来自编码器的输出。
- 计算方式:与普通多头注意力相同,但 Q、K、V 的来源不同。
- 意义:解码器通过交叉注意力决定“在生成当前词时,需要关注源序列的哪些部分”。
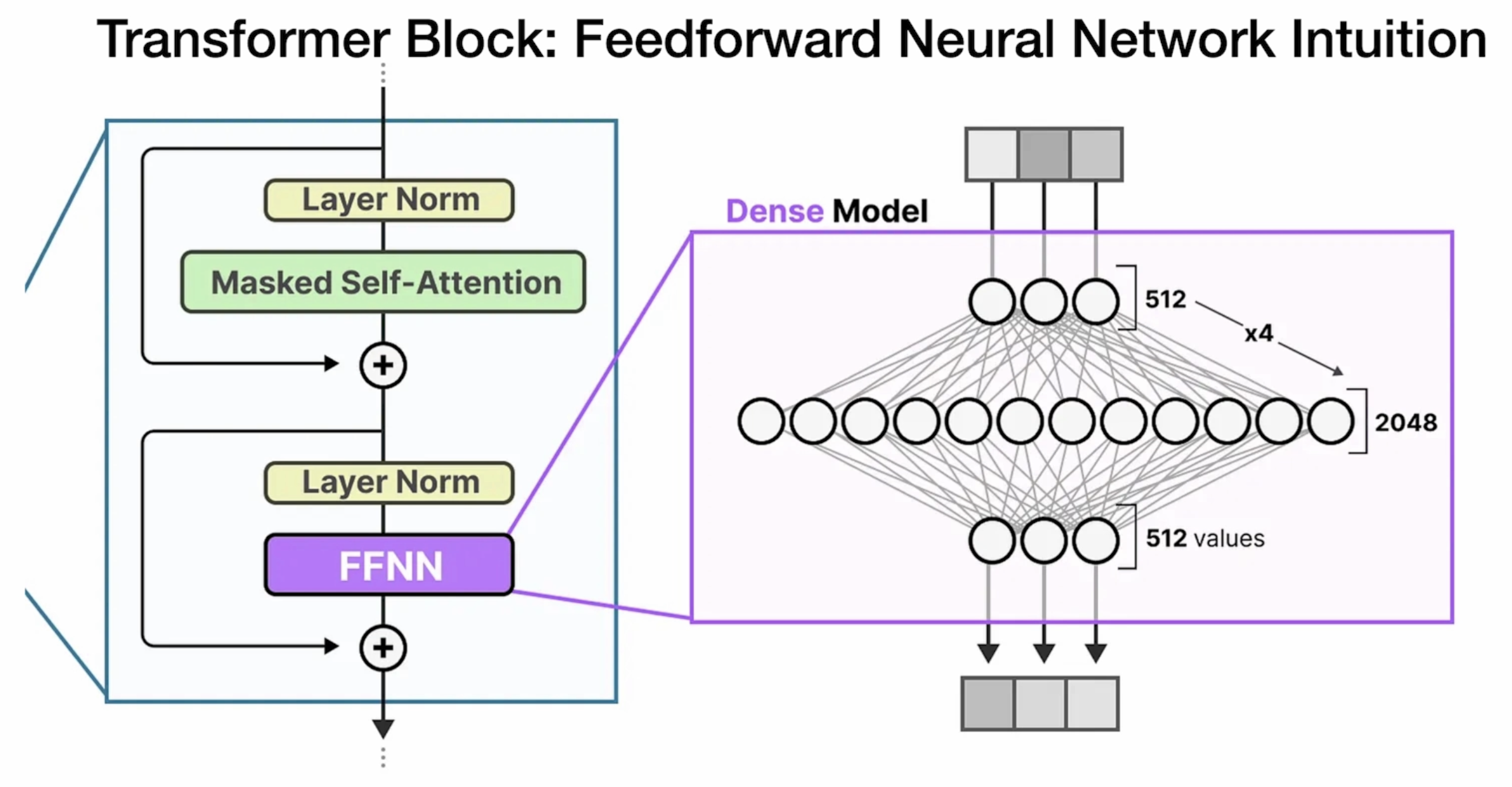
#### 3.3 前馈网络(FFN)
- 与编码器的FFN结构相同:
\[
\text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2
\]
- 作用:对注意力结果进行非线性变换,增强模型表达能力。
#### 3.4 残差连接与层归一化
- 每个子模块的输出为:
\[
x_{\text{out}} = \text{LayerNorm}(x_{\text{in}} + \text{Sublayer}(x_{\text{in}}))
\]
- 残差连接:缓解梯度消失,帮助深层网络训练。
- 层归一化:对每个词元的特征进行归一化。
---
### 4. 解码器的训练与推理
#### 4.1 训练阶段
- 输入:目标序列右移一位(如输入 <sos> A B C,输出 A B C <eos>)。
- 教师强制(Teacher Forcing):解码器在训练时使用真实目标序列作为输入,即使生成错误。
- 损失计算:交叉熵损失,预测下一个词元。
#### 4.2 推理阶段(自回归生成)
- 逐步生成:
1. 输入起始符 <sos>,生成第一个词。
2. 将生成的词作为输入,继续生成下一个词,直到输出 <eos>。
- 生成策略:
- 贪心搜索(Greedy Search):每一步选概率最高的词(可能陷入局部最优)。
- 集束搜索(Beam Search):保留多个候选序列,平衡生成质量与多样性。
- 温度采样(Temperature Sampling):调整概率分布的平滑度,控制生成多样性。
---
### 5. 解码器 vs 编码器的关键区别
| 组件/特性 | 解码器 | 编码器 |
|---------------------|-------------------------------------|----------------------------|
| 自注意力类型 | 掩码自注意力(遮挡未来词元) | 普通自注意力(全上下文) |
| 交叉注意力层 | ✅(连接编码器输出) | ❌ |
| 输入来源 | 目标序列 + 编码器输出 | 源序列 |
| 生成方式 | 自回归(逐步生成) | 单次前向计算 |
---
### 6. 典型模型中的解码器设计
#### 6.1 GPT系列(仅解码器架构)
- 结构:堆叠解码器层,但**没有交叉注意力层**(因无编码器输入)。
- 掩码自注意力:单向注意力(仅左侧上下文),用于语言模型预训练。
- 应用:文本生成、问答等生成任务。
#### 6.2 Transformer原始论文(机器翻译)
- 完整解码器:包含掩码自注意力、交叉注意力和FFN。
- 输入:编码器输出的源语言表示 + 目标语言嵌入。
#### 6.3 T5(编码器-解码器架构)
- 解码器:与原始Transformer相同,用于生成式任务(如摘要、翻译)。
---
### 7. 解码器的核心挑战与优化
1. 长序列生成:
- 问题:生成长文本时可能重复或偏离主题。
- 解决:使用重复惩罚(Repetition Penalty)、核采样(Nucleus Sampling)等。
2. 曝光偏差(Exposure Bias):
- 问题:训练时用真实数据,推理时用模型生成的数据,导致误差累积。
- 解决:课程学习(Curriculum Learning)、计划采样(Scheduled Sampling)。
3. 计算效率:
- 问题:自回归生成逐词进行,速度慢。
- 解决:缓存键值(KV Cache)、并行解码策略(如Non-Autoregressive Models)。
---
### 总结
解码器的核心在于通过**掩码自注意力**避免信息泄漏,并通过**交叉注意力**融合编码器的上下文信息。其自回归生成机制使其成为文本生成、翻译等任务的核心组件。理解解码器的架构是掌握GPT、T5等生成式模型的关键!
https://chat.mosuyang.org/s/fc49e3da-8226-4a43-a234-8eefb05d0bcb
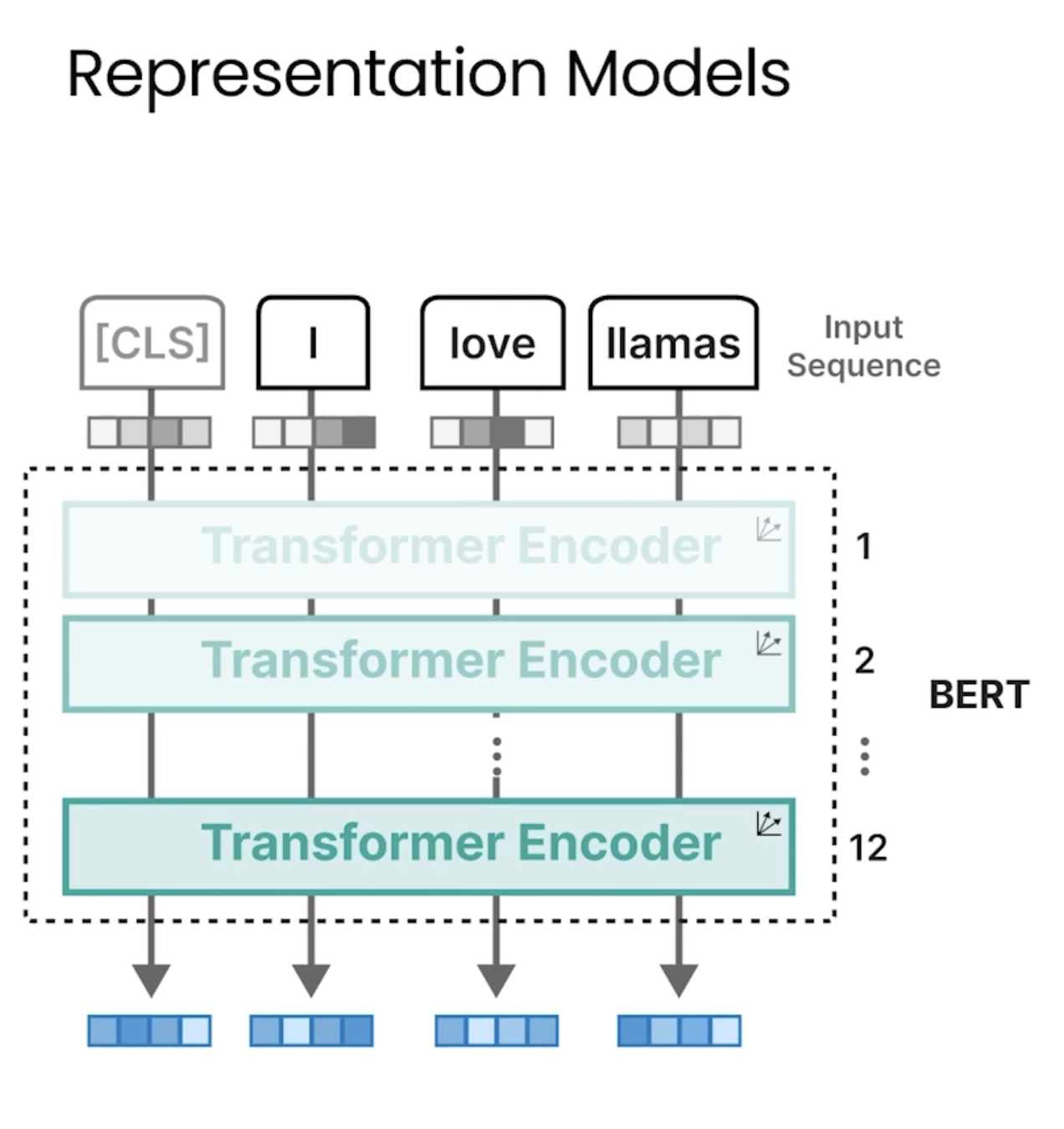
Bert
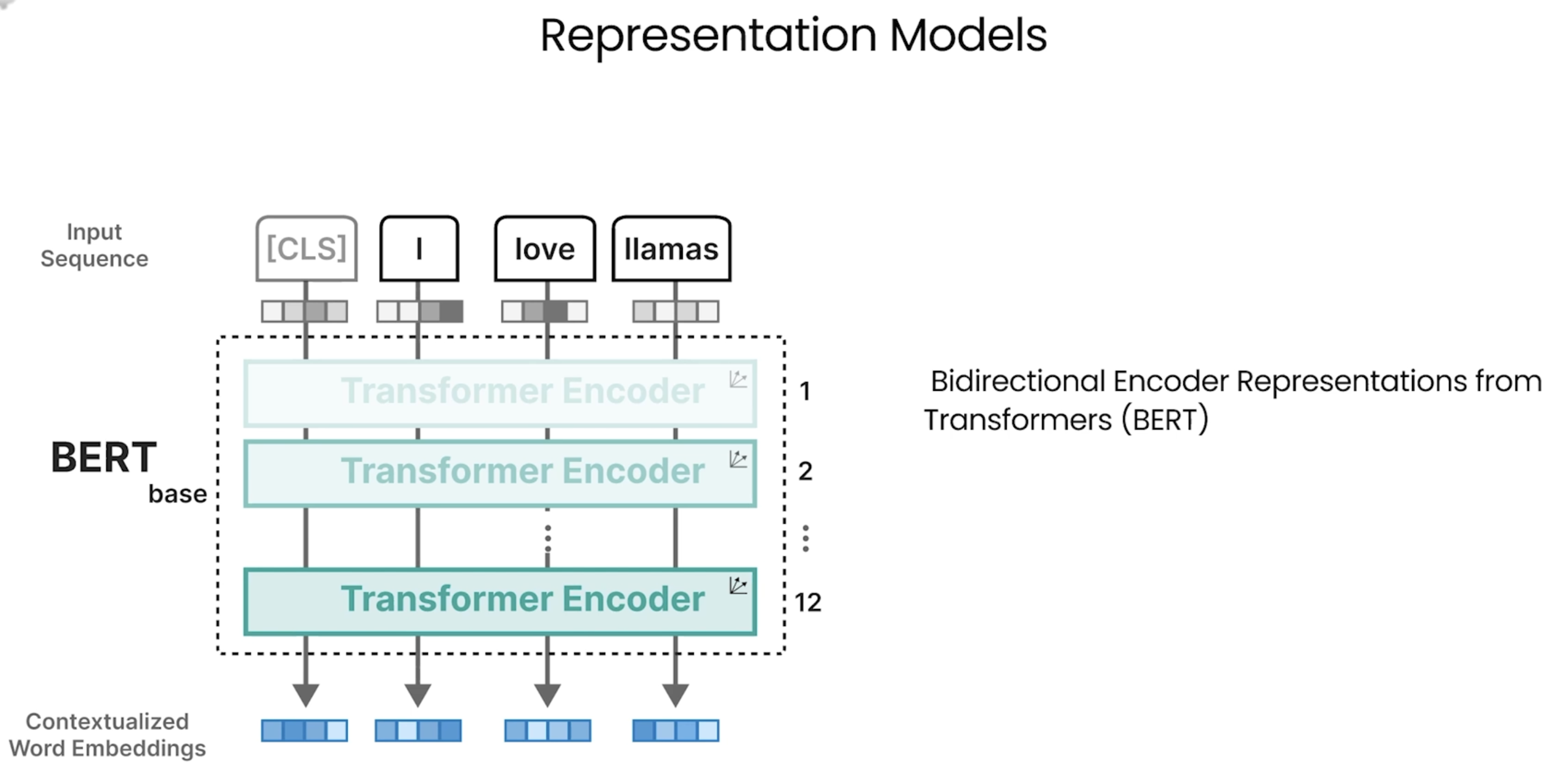
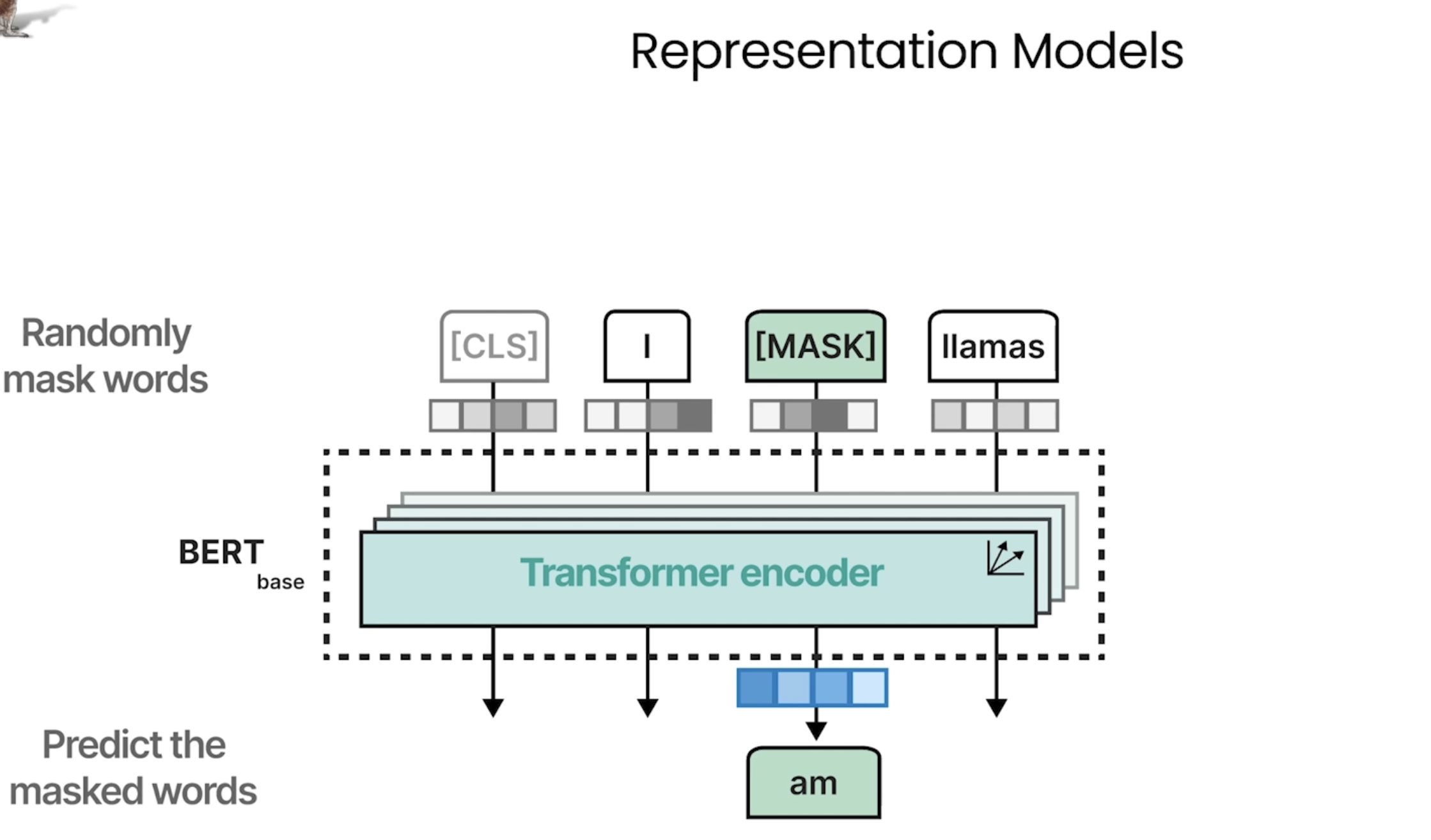
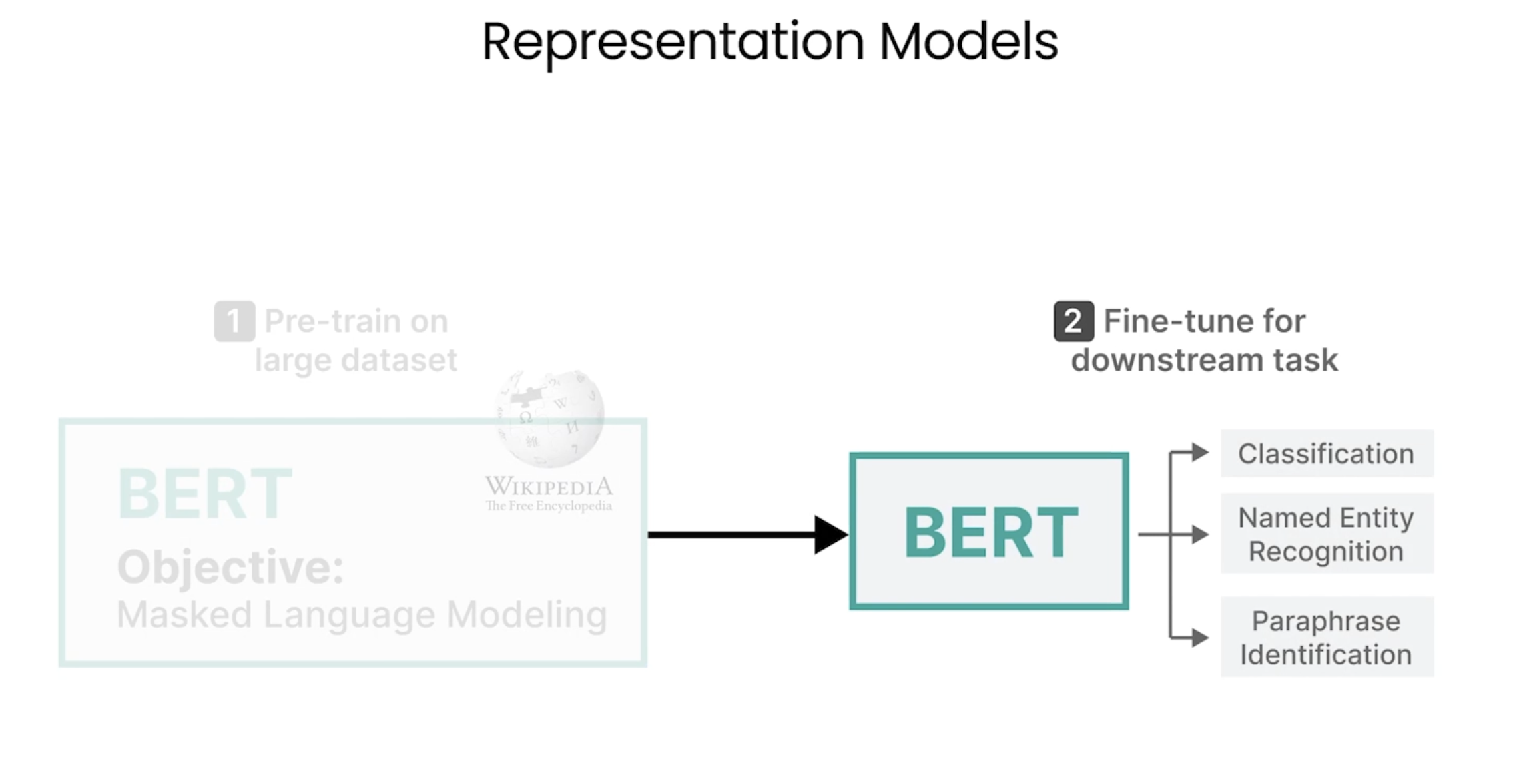
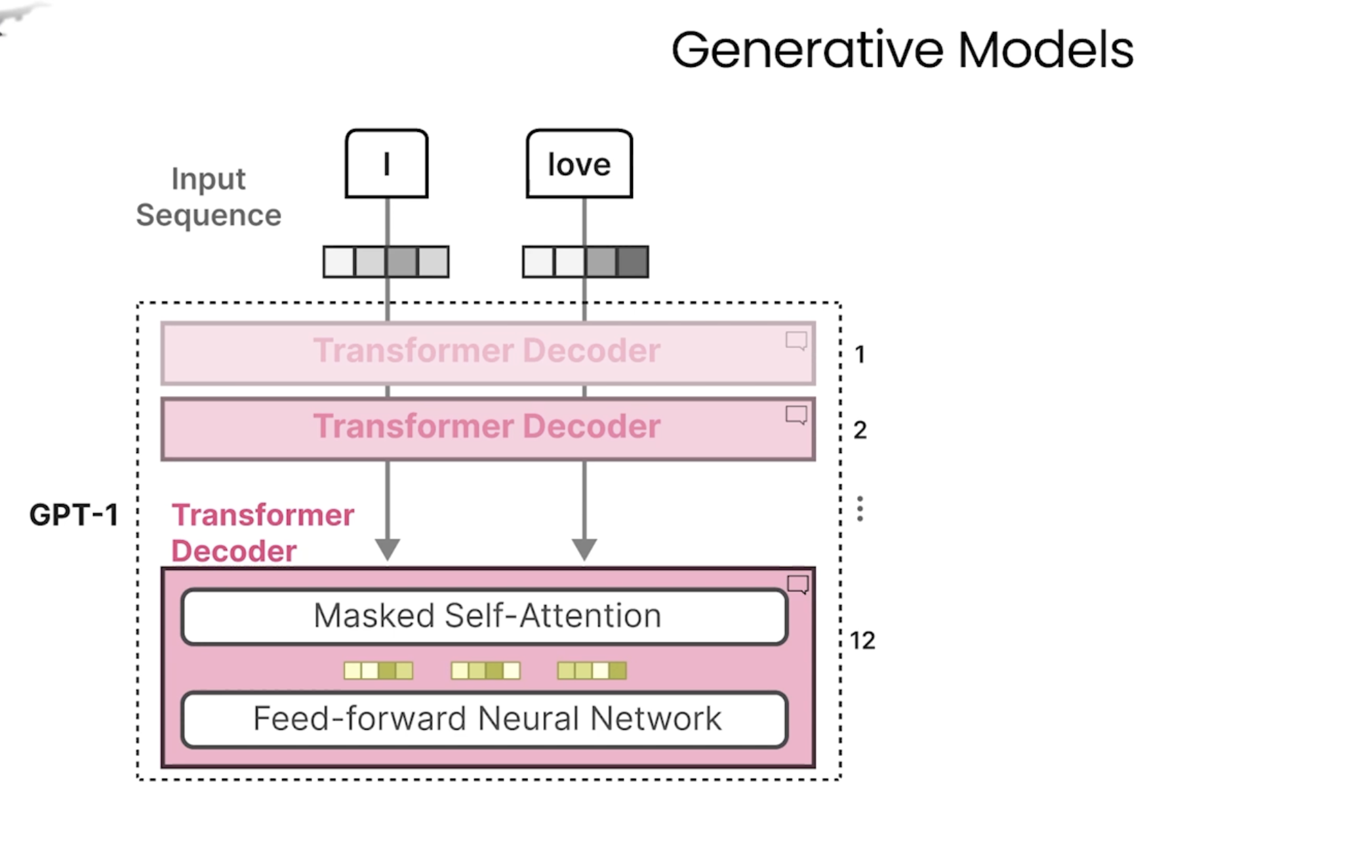
Generative Models
不同架构的生成模型介绍及比较:https://chat.mosuyang.org/s/fc49e3da-8226-4a43-a234-8eefb05d0bcb

下图是GPT使用的只有解码器的模型架构
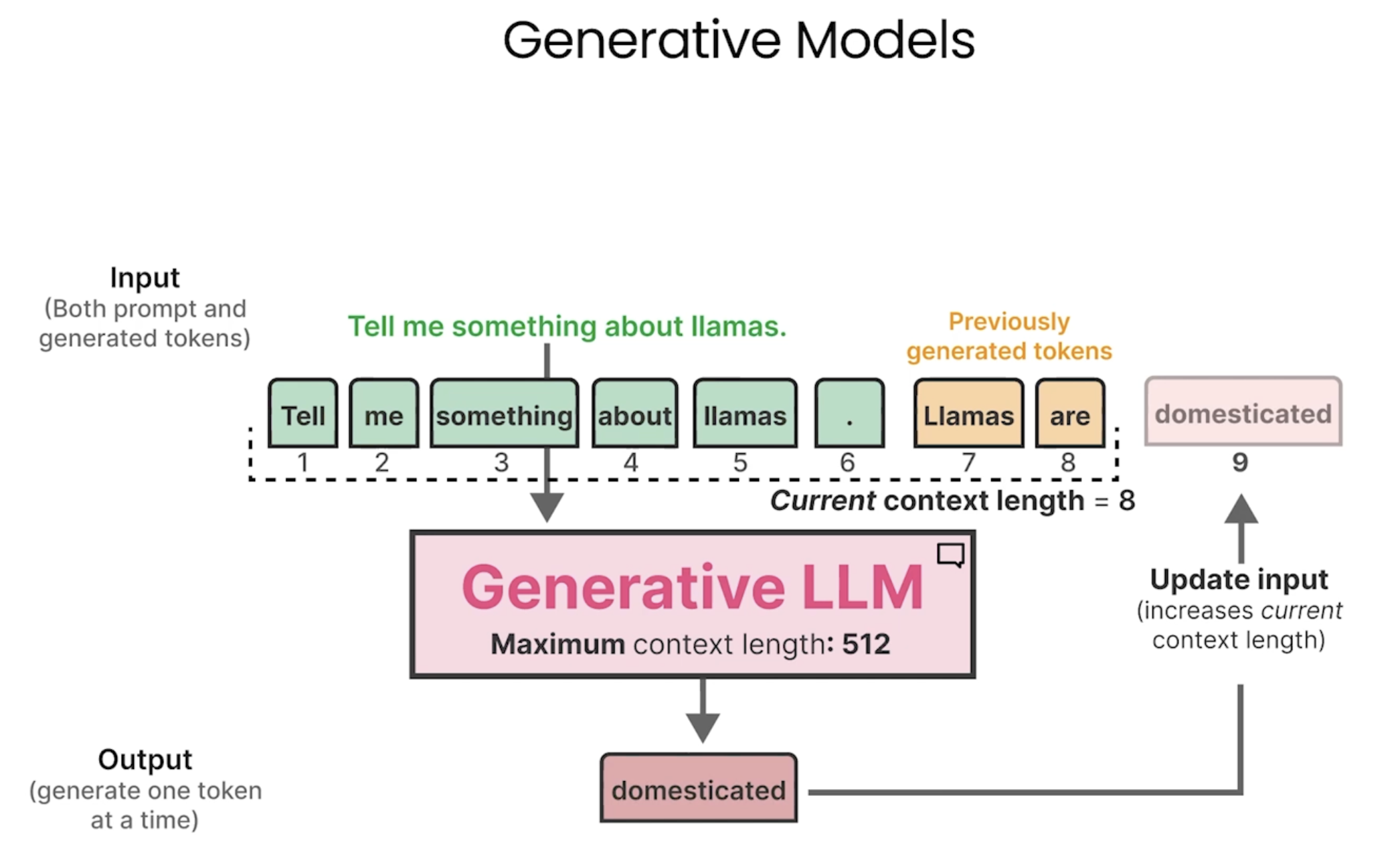
Tokenizers
之前的博客文章详细介绍过 Tokenization
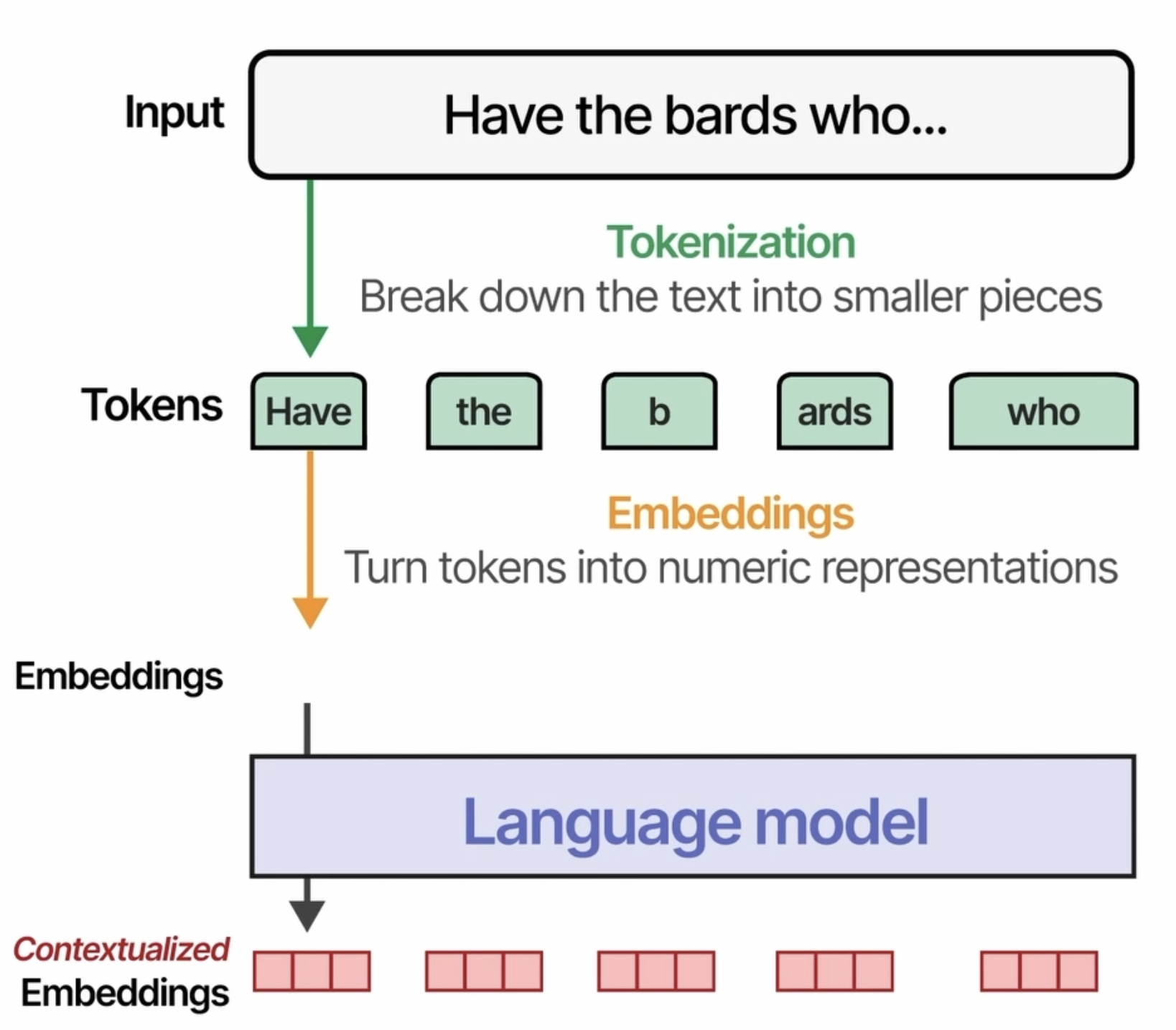
下面代码展示了两种不同的tokenization 方式

Architectural Overview
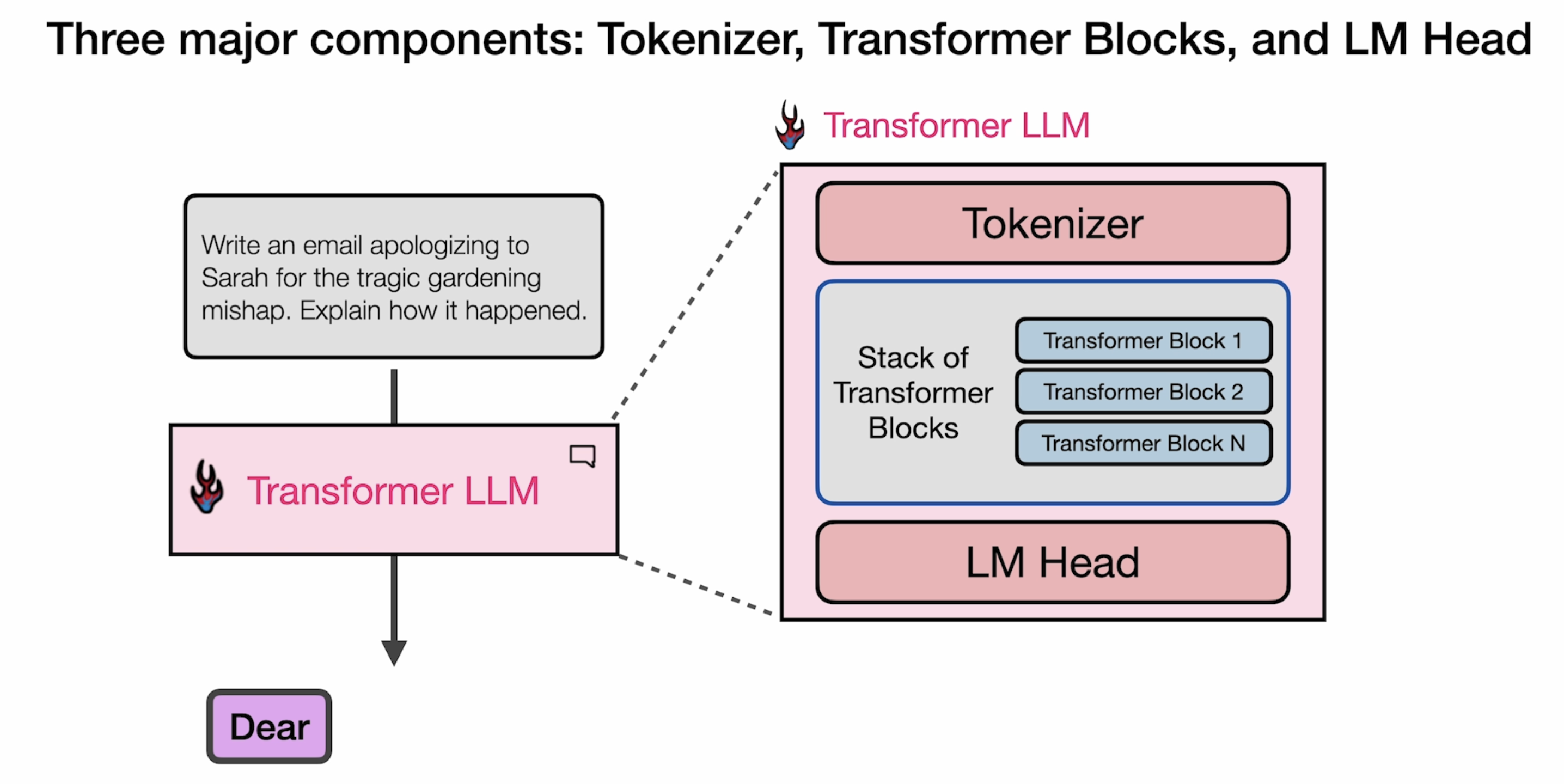
Tokenizer
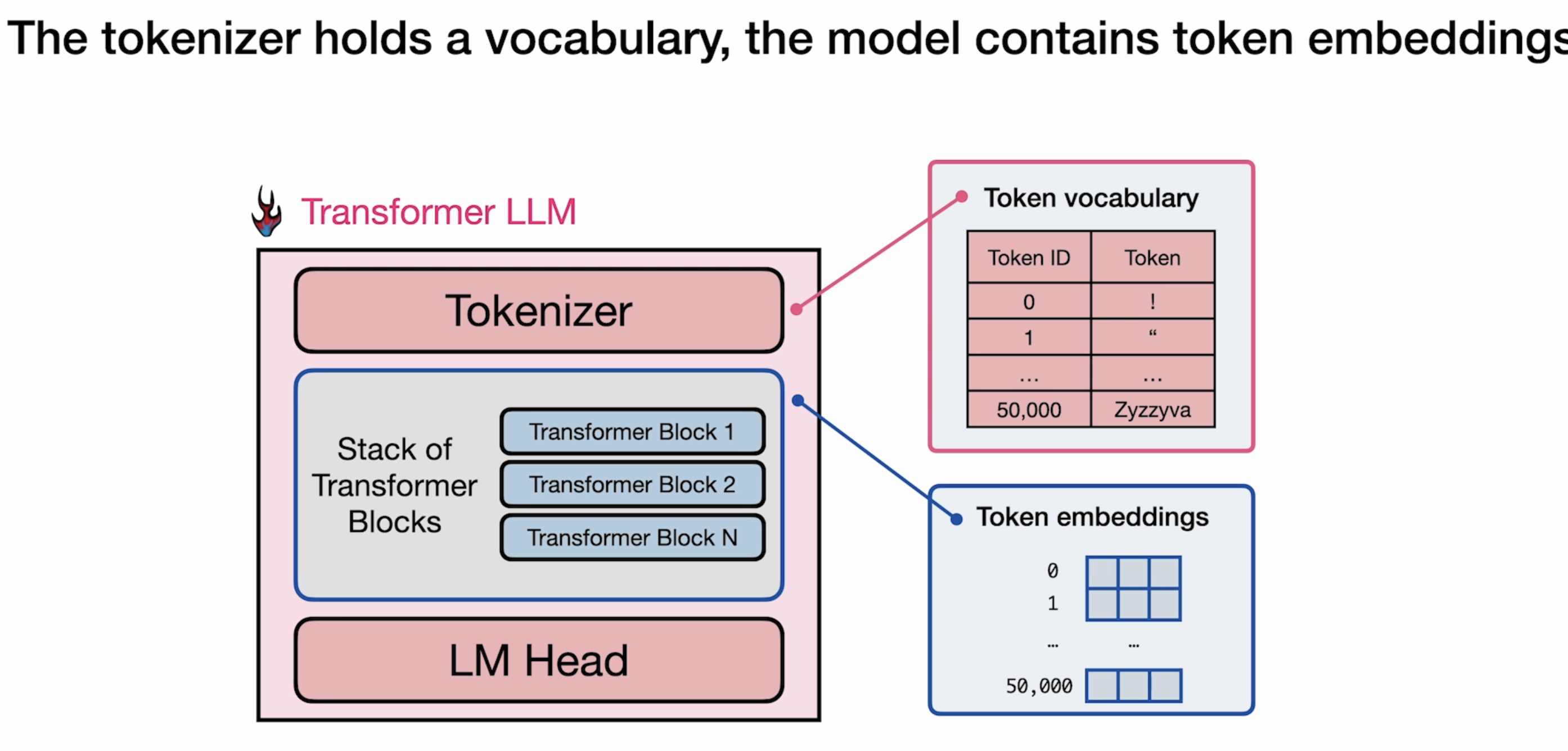
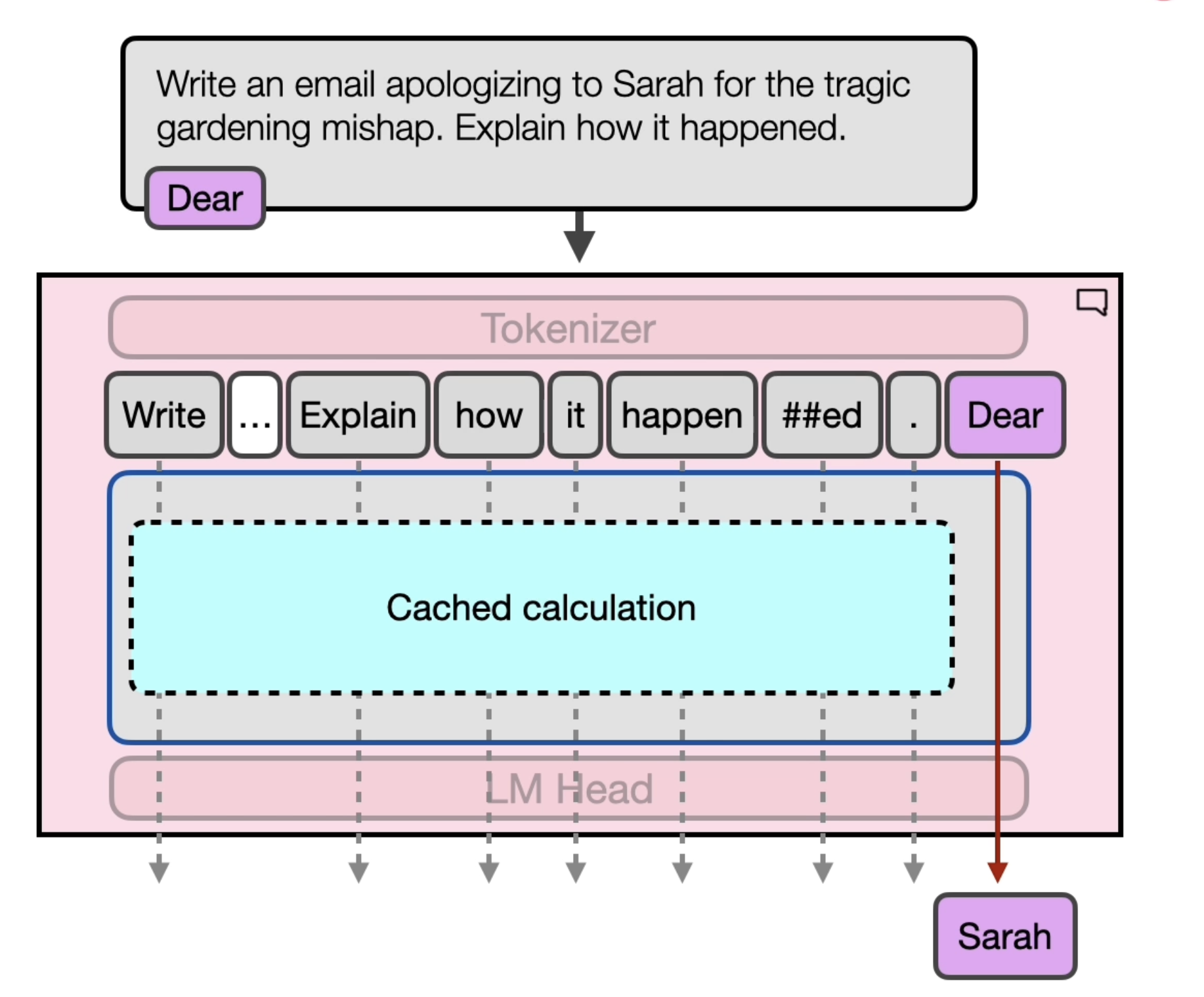
LLM Head
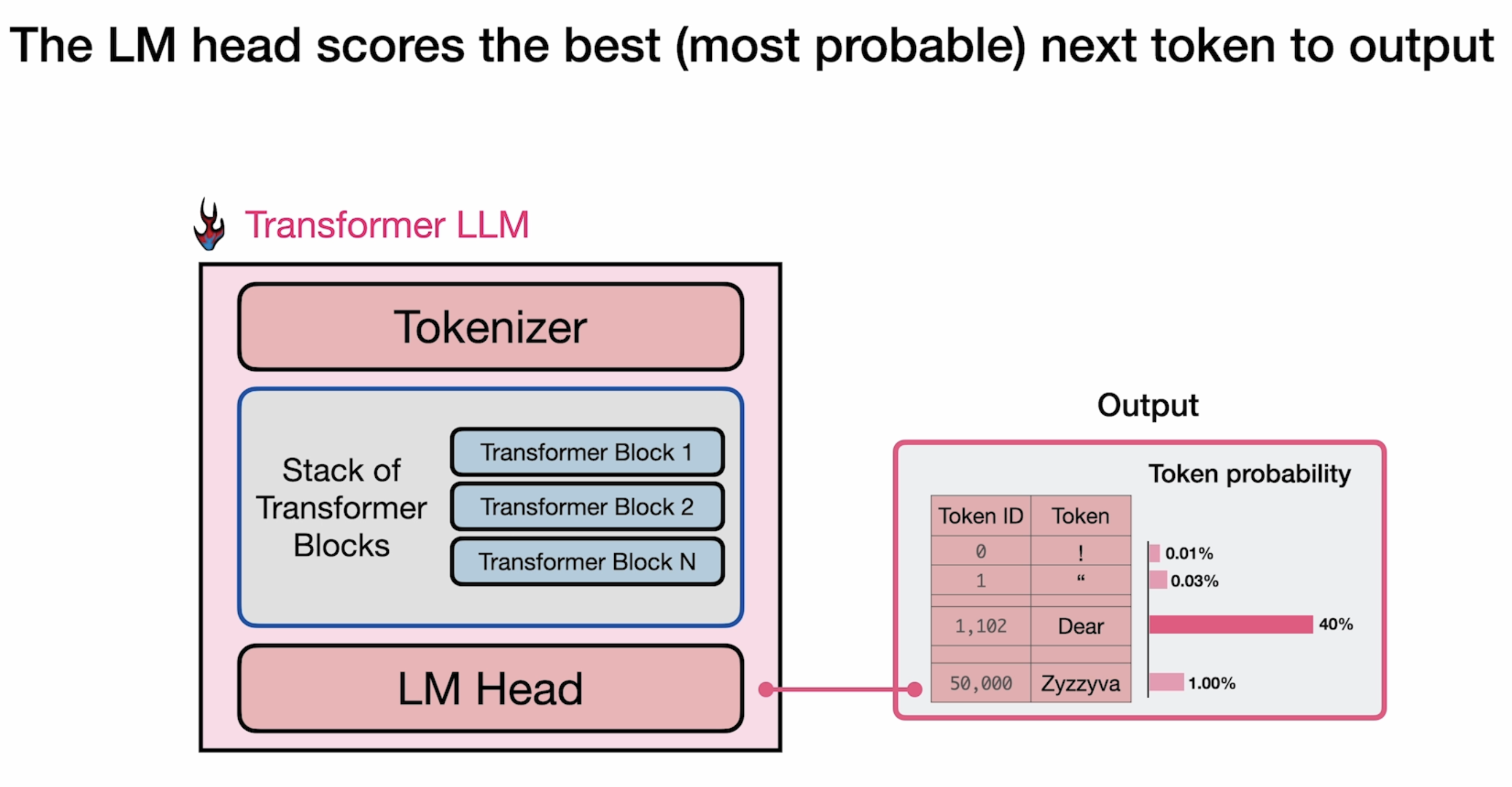
Transformer LLM
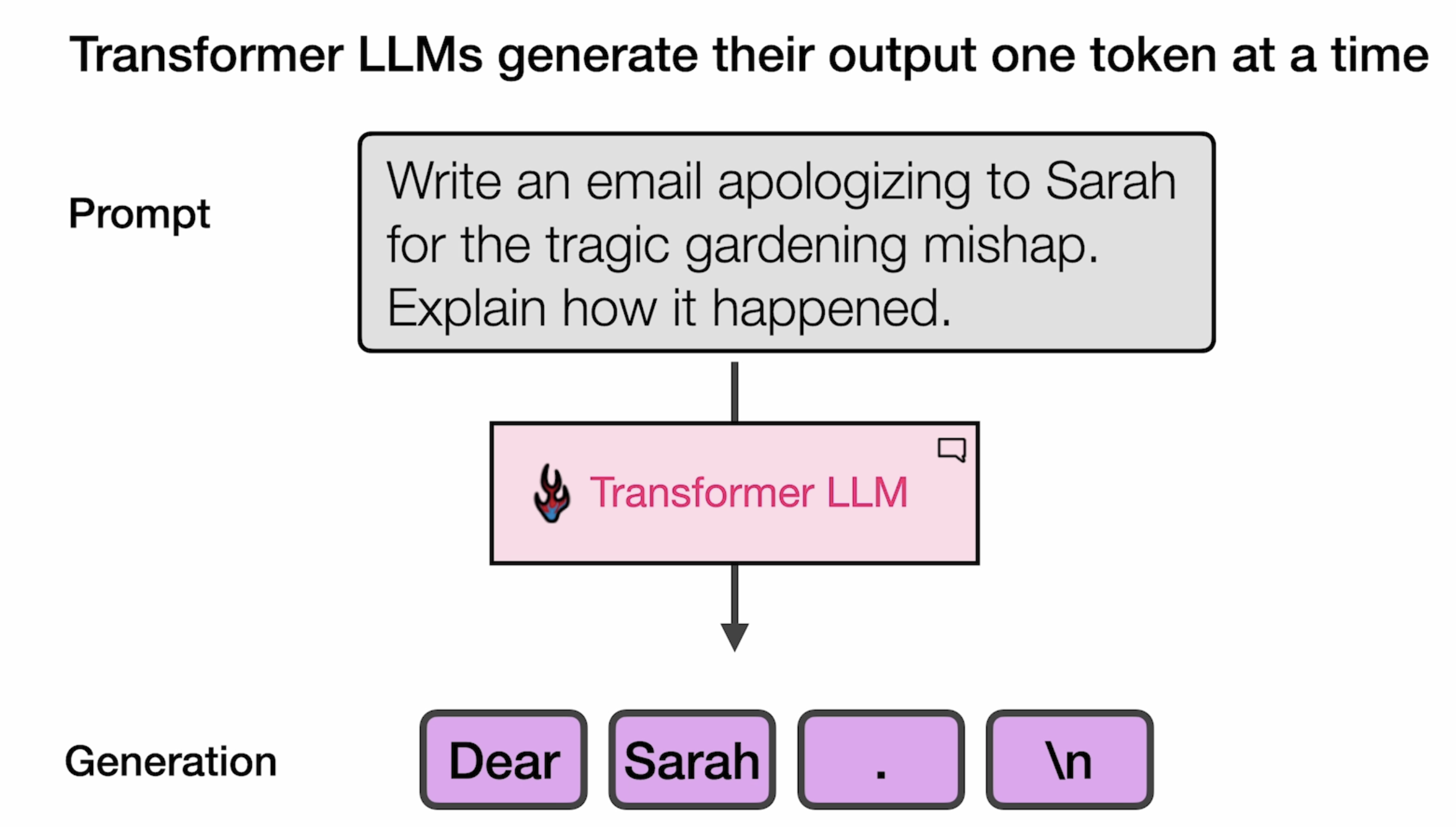
LLM 在输出时,会将每个token一个个的输出。
The Transformer Block
Self-Attention
本节介绍了Query,Key, Value矩阵,属于attention中的核心内容。前面也有详细解释这三个向量矩阵的作用。
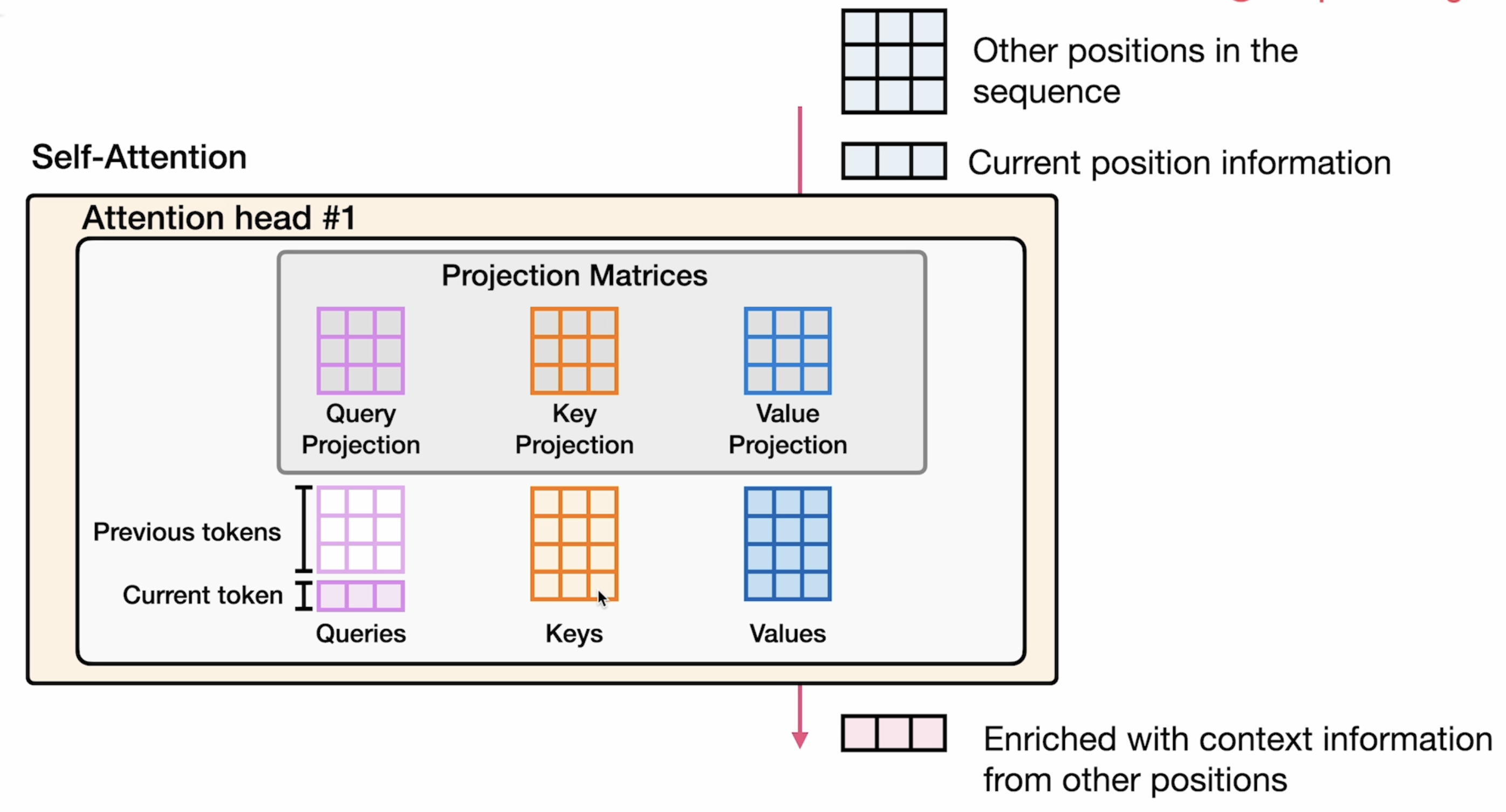
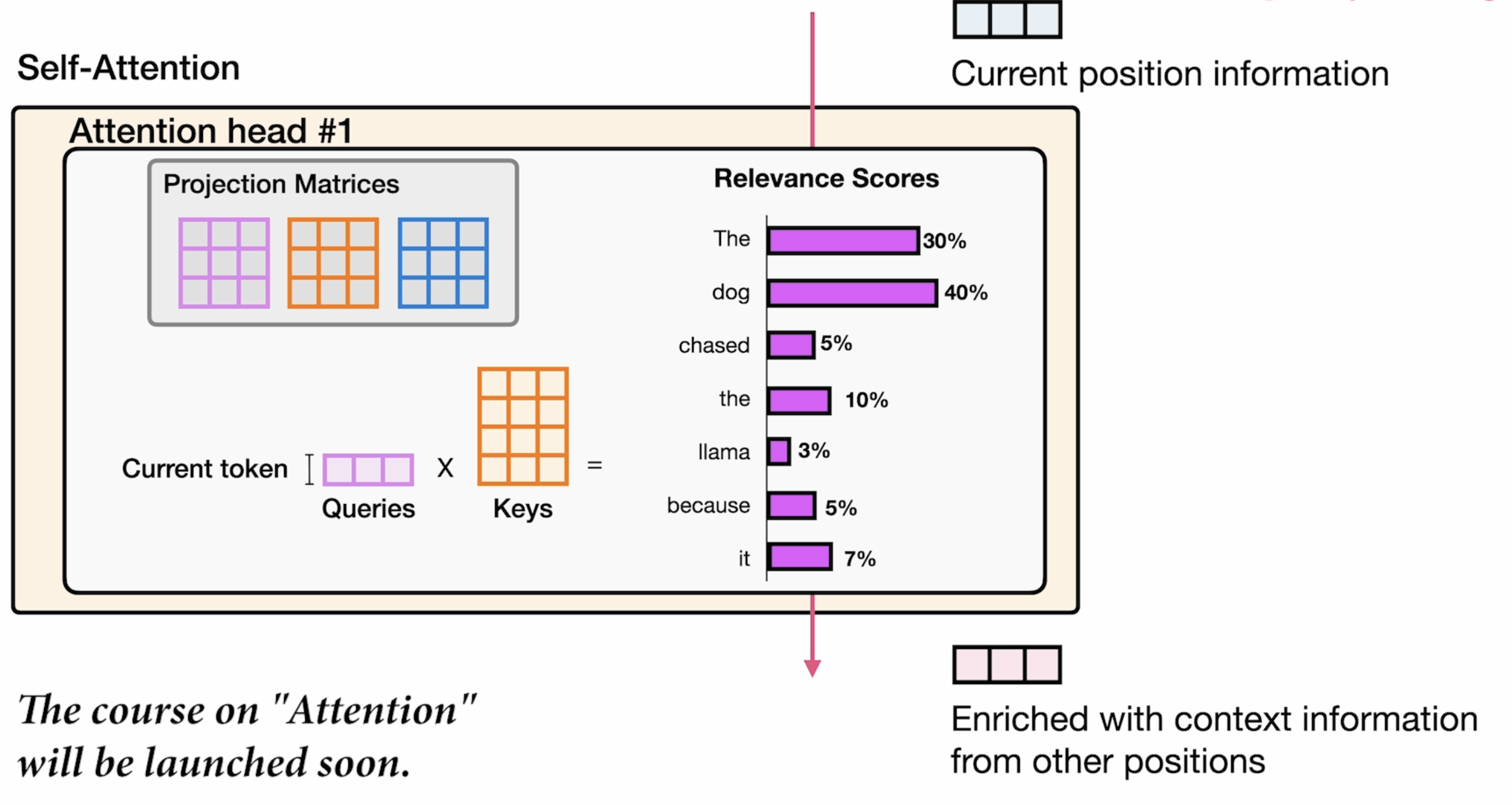
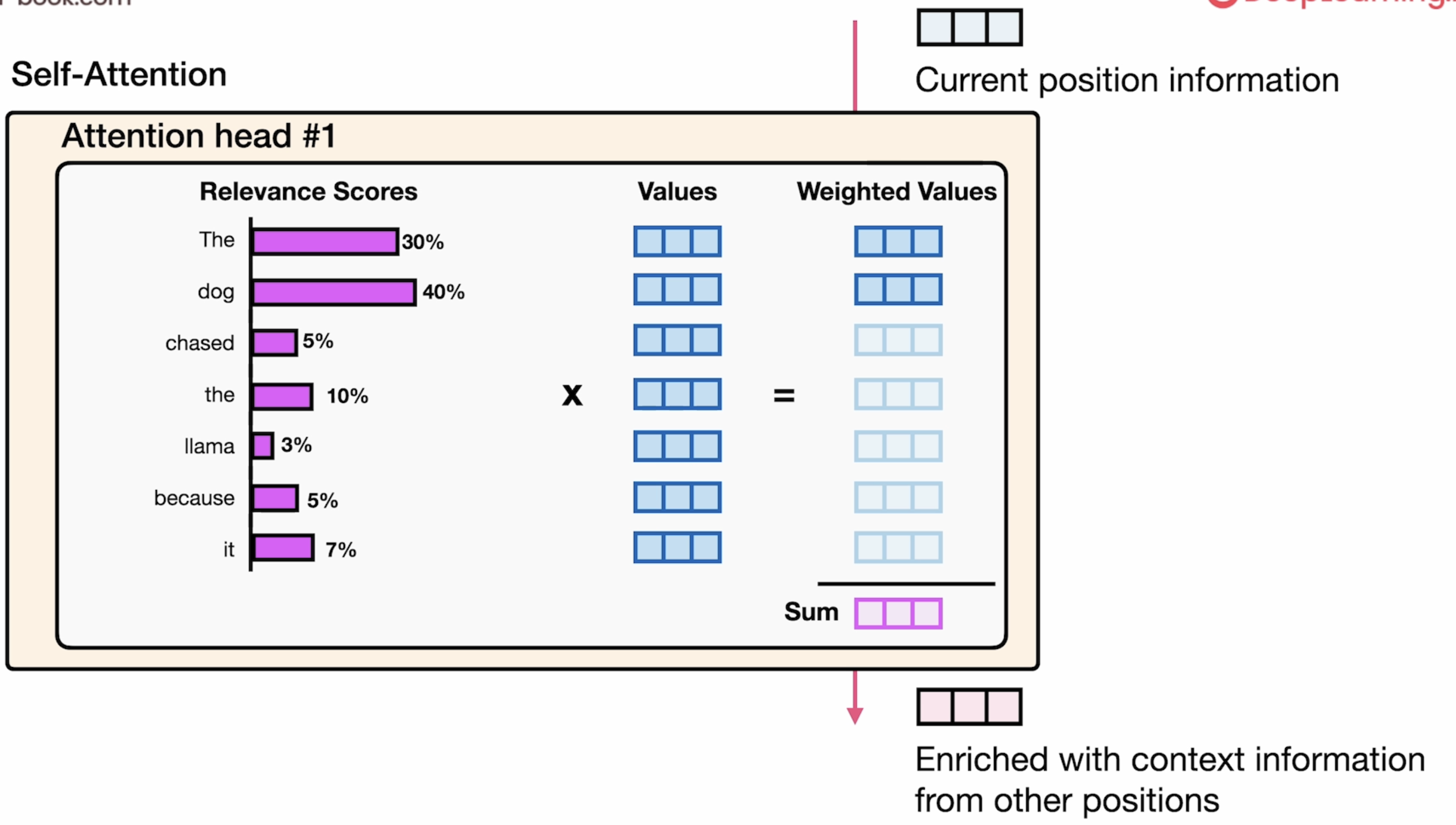
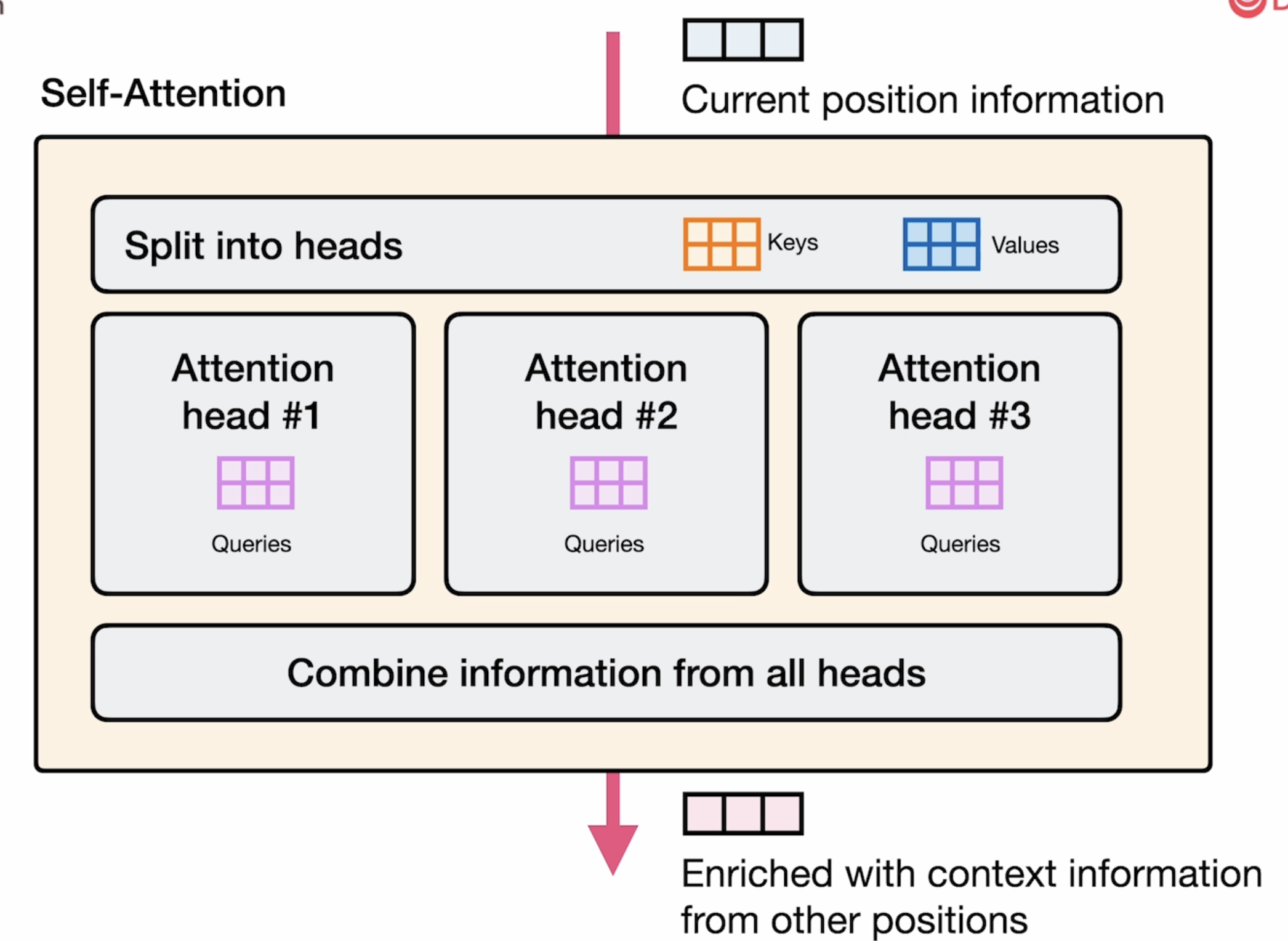
在具体工程应用中,attention head 是有多个的,就像下图表示所示:每个attention head都有 Q K V三个向量矩阵。
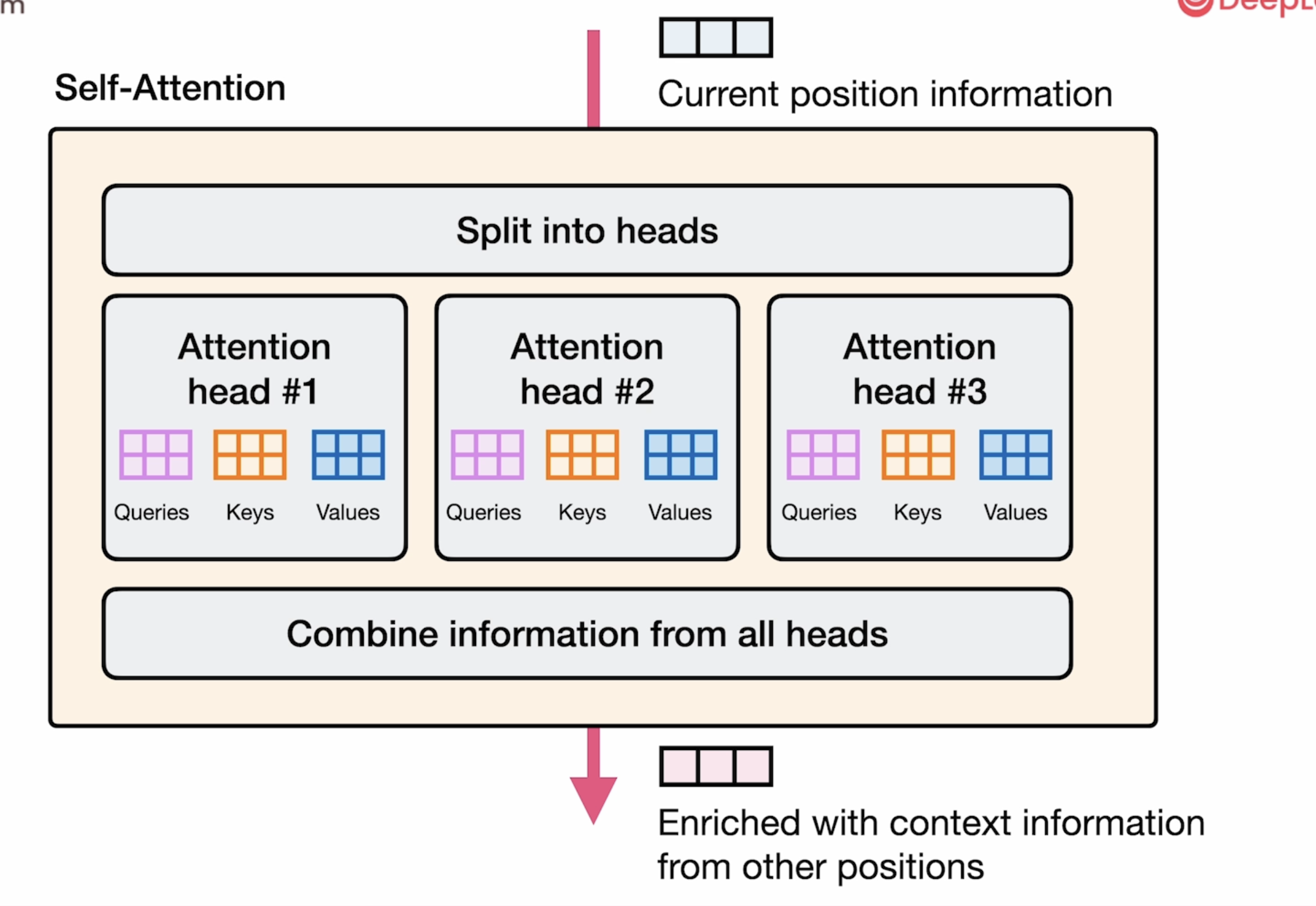
improve performance method
shared K V Matrix
为了节省时间,每个attention head 可以共用 Q K V三个矩阵。
<details type="reasoning" done="true" duration="8">
<summary>Thought for 8 seconds</summary>
> The user is asking about the benefits of sharing Key (K) and Value (V) matrices across attention heads while having separate Query (Q) matrices for each head. This is shown in the diagram where each group has Keys and Values, and then multiple attention heads with their own Queries.
>
> Let me analyze the benefits of this "grouped query attention" or "multi-query attention" approach:
>
> 1. Computational Efficiency:
> - Reduced memory bandwidth: By sharing K and V across heads, there's significantly less memory needed for storing and accessing these matrices
> - Lower computational cost: Computing K and V projections only once instead of once per head reduces the total computation required
> - Faster inference: This is especially important for large models where memory bandwidth is often the bottleneck
>
> 2. Model Performance Benefits:
> - Still maintains representation diversity: Different Query projections per head allow the model to attend to different patterns in the input
> - Preserves most of the modeling capacity: Research has shown this approach retains much of the performance of full multi-head attention despite the parameter reduction
> - Potentially better generalization: The parameter sharing may act as a form of regularization
>
> 3. Implementation Benefits:
> - Allows for more efficient batching of operations
> - Enables more attention heads with the same parameter budget
> - Makes running large models on consumer hardware more feasible
>
> 4. Specific to Large Language Models:
> - Particularly beneficial for decoder-only architectures where K and V caching is important
> - Makes KV cache more memory-efficient during text generation
> - Allows for longer context windows with the same memory budget
>
> This approach represents a compromise between full multi-head attention (separate Q, K, V for each head) and single-head attention, offering a sweet spot of performance and efficiency. It's been adopted in several modern LLM architectures to improve inference speed and reduce memory requirements while maintaining most of the benefits of multi-head attention.
</details>
在图中展示的多头注意力机制中,每个注意力头共享 Keys (K) 和 Values (V) 但拥有独立的 Queries (Q) 有以下几个显著好处:
1. 计算效率大幅提升:
- 减少内存带宽需求:K和V矩阵只需计算一次而非每个头都计算
- 降低总体计算成本:K和V的投影只需进行一次
- 提高推理速度:尤其在大型模型中,内存带宽常是瓶颈
2. 内存效率:
- KV缓存(cache)大小减少:在文本生成过程中,每个新token只需存储一组KV,而非每个注意力头一组
- 允许支持更长的上下文窗口:相同内存预算下可处理更长序列
3. 保持模型表现:
- 维持表示多样性:独立的Q矩阵仍使每个头能关注不同的输入模式
- 保留大部分建模能力:研究表明,这种方法尽管参数减少,但保留了多头注意力的大部分性能
- 可能更好的泛化:参数共享可能起到正则化作用
这种方法(有时称为"分组查询注意力"或"多查询注意力")在现代大型语言模型中被广泛采用,因为它在保持模型质量的同时,显著提高了推理效率和内存利用率。
Sparse Attention
<details type="reasoning" done="true" duration="5">
<summary>Thought for 5 seconds</summary>
> The user is asking about sparse attention (稀疏注意力), which is shown in the second image. I'll explain what sparse attention is based on the information in the image.
>
> Looking at the second image, it's titled "More attention efficiency: sparse attention" and illustrates two types of self-attention mechanisms in transformer models:
>
> 1. Global autoregressive self-attention (全局自回归自注意力)
> 2. Local autoregressive self-attention (局部自回归自注意力)
>
> The image shows how local attention "boosts performance by only paying attention to a small number of previous positions."
>
> In sparse attention, instead of each token attending to all other tokens in the sequence (which is computationally expensive and scales quadratically with sequence length), tokens only attend to a subset of other tokens. This creates a "sparse" attention pattern rather than a "dense" one where everything attends to everything else.
>
> The image specifically illustrates local attention, where each token only attends to a limited window of nearby tokens (in this case, it appears tokens 4-7 are only attending to other recent tokens, not the entire history).
>
> I'll explain the concept of sparse attention, its benefits, and how it differs from the standard dense attention mechanism.
</details>
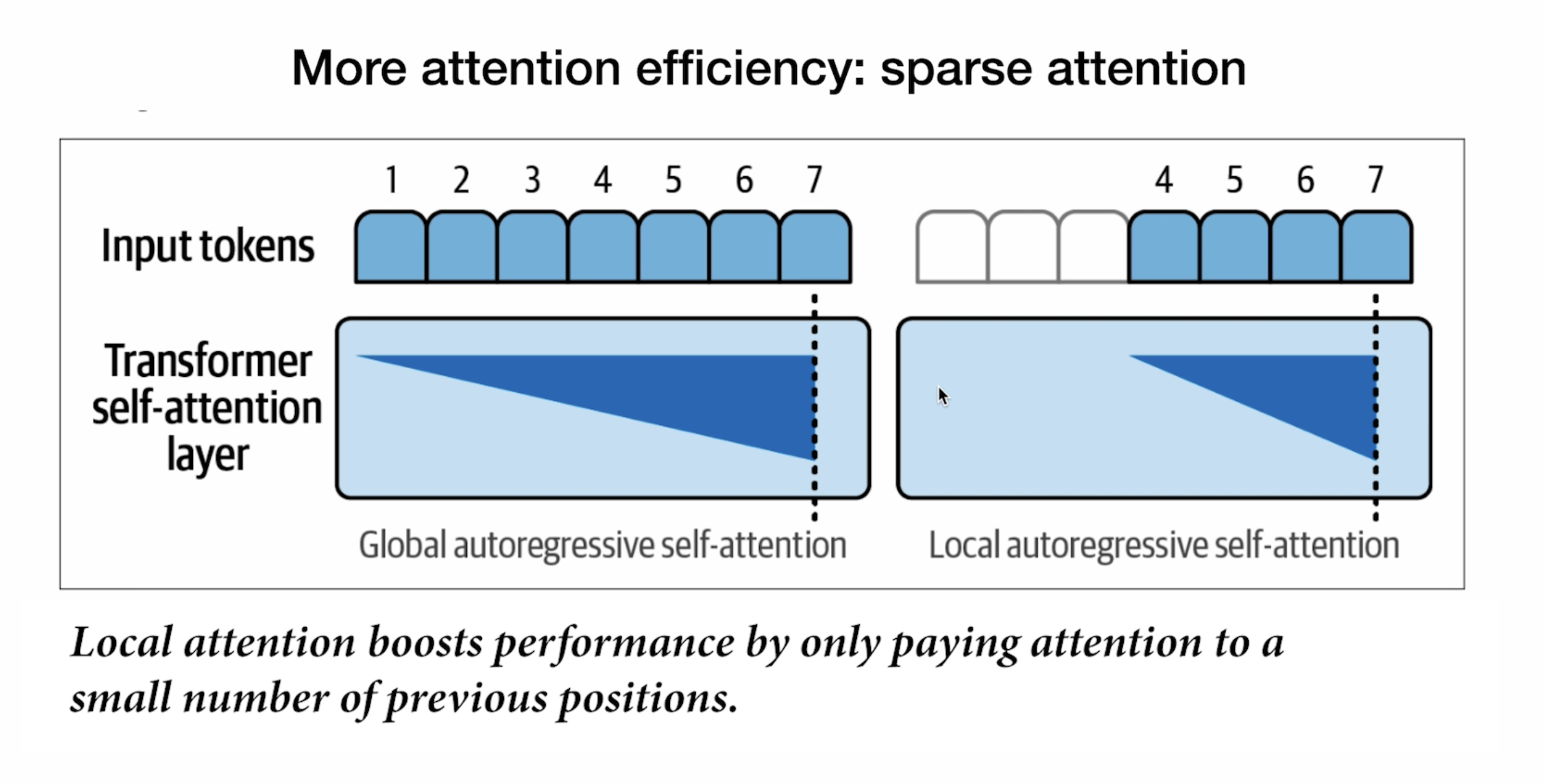
稀疏注意力(Sparse Attention)是一种提高transformer模型计算效率的技术,正如第二张图所示。它的核心思想是:不需要每个token都关注序列中的所有其他token,而是有选择性地只关注一部分重要token。
图中展示了两种对比:
1. 全局自回归自注意力(Global autoregressive self-attention):
- 每个token都关注其之前的所有token
- 形成完整的三角形注意力模式
- 计算复杂度随序列长度呈二次方增长(O(n²))
2. 局部自回归自注意力(Local autoregressive self-attention):
- 每个token只关注附近的有限窗口内的token
- 在图中,右侧只关注最近的几个位置(4-7),忽略了更早的位置(1-3)
- 形成一个截断的注意力模式
稀疏注意力的主要优势:
- 计算效率显著提高:不需要计算所有可能的token对之间的注意力分数
- 内存使用降低:不需要存储完整的注意力矩阵
- 可扩展性增强:能够处理更长的序列
- 保持性能:在许多任务中,大部分重要信息都集中在附近的上下文中
这种方法是解决transformer模型"注意力机制计算复杂度随序列长度二次方增长"这一核心挑战的重要策略之一。

Ring Attention
<details type="reasoning" done="true" duration="9">
<summary>Thought for 9 seconds</summary>
> I'm being asked about Ring Attention, which is shown in the third image (Image 3). Let me analyze what Ring Attention is based on the information provided in that image.
>
> From Image 3, I can see it's titled "Ring Attention Explained" and it appears to be a blog post or article by Kilian Haefeli, Simon Zirui Guo, and Bonnie Li dated April 10, 2024.
>
> The article discusses context length challenges in Large Language Models, noting:
> 1. Context length has expanded rapidly - from GPT-3.5's 16k tokens to Claude 2's 200k tokens to Gemini 1.5 Pro's 1 million tokens
> 2. Longer context windows allow models to incorporate and reason about more information
> 3. Increasing context length poses significant technical challenges due to GPU memory capacity
> 4. Ring Attention is presented as a promising approach to scale to a "near infinite context window"
>
> The image also shows a diagram on the right that depicts a ring-like structure with multiple GPUs (labeled GPU 1, GPU 2, GPU 3, GPU 4) connected in a ring formation, with K (keys) and V (values) being passed between them.
>
> Based on this information, Ring Attention appears to be a distributed computing technique that:
> 1. Distributes the attention computation across multiple GPUs arranged in a ring topology
> 2. Allows passing of keys and values between GPUs in a circular manner
> 3. Enables processing of extremely long contexts by overcoming individual GPU memory limitations
> 4. Creates a system where each GPU handles a portion of the context, but the overall system can process a much larger context window
>
> This approach addresses the fundamental constraint that even with techniques like sparse attention, a single GPU's memory can only handle context of limited length. By distributing the computation in a ring structure, the system can theoretically scale to much longer contexts - potentially approaching what they call a "near infinite context window."
>
> I'll explain Ring Attention based on this understanding.
</details>
Ring Attention 是一种用于扩展大型语言模型上下文窗口的技术,如图3所示。它的核心思想是使用多GPU分布式系统来突破单个GPU内存限制,实现近乎无限的上下文处理能力。
主要特点:
1. 分布式注意力计算:
- 将计算负载分布到多个GPU上
- GPU按环形拓扑连接(如图右侧所示,GPU 1→2→3→4→1形成一个环)
- 每个GPU负责处理部分上下文窗口
2. Key-Value传递机制:
- K (Keys)和V (Values)在GPU之间传递
- 数据沿着环形路径流动,使每个GPU都能访问需要的上下文信息
- 图中的K1-V1, K2-V2等表示在不同GPU间传递的键值对
3. 解决长上下文问题:
- 文章提到上下文长度从GPT-3.5的16k到Claude 2的200k再到Gemini 1.5 Pro的100万tokens不断增长
- 长上下文带来GPU内存容量挑战
- Ring Attention提供了一种扩展解决方案,理论上可接近"无限上下文窗口"
这种方法的优势在于它允许模型处理远超单个GPU内存限制的超长上下文,同时保持计算效率,对于需要理解和分析大量文本的应用场景非常有价值。

架构分析
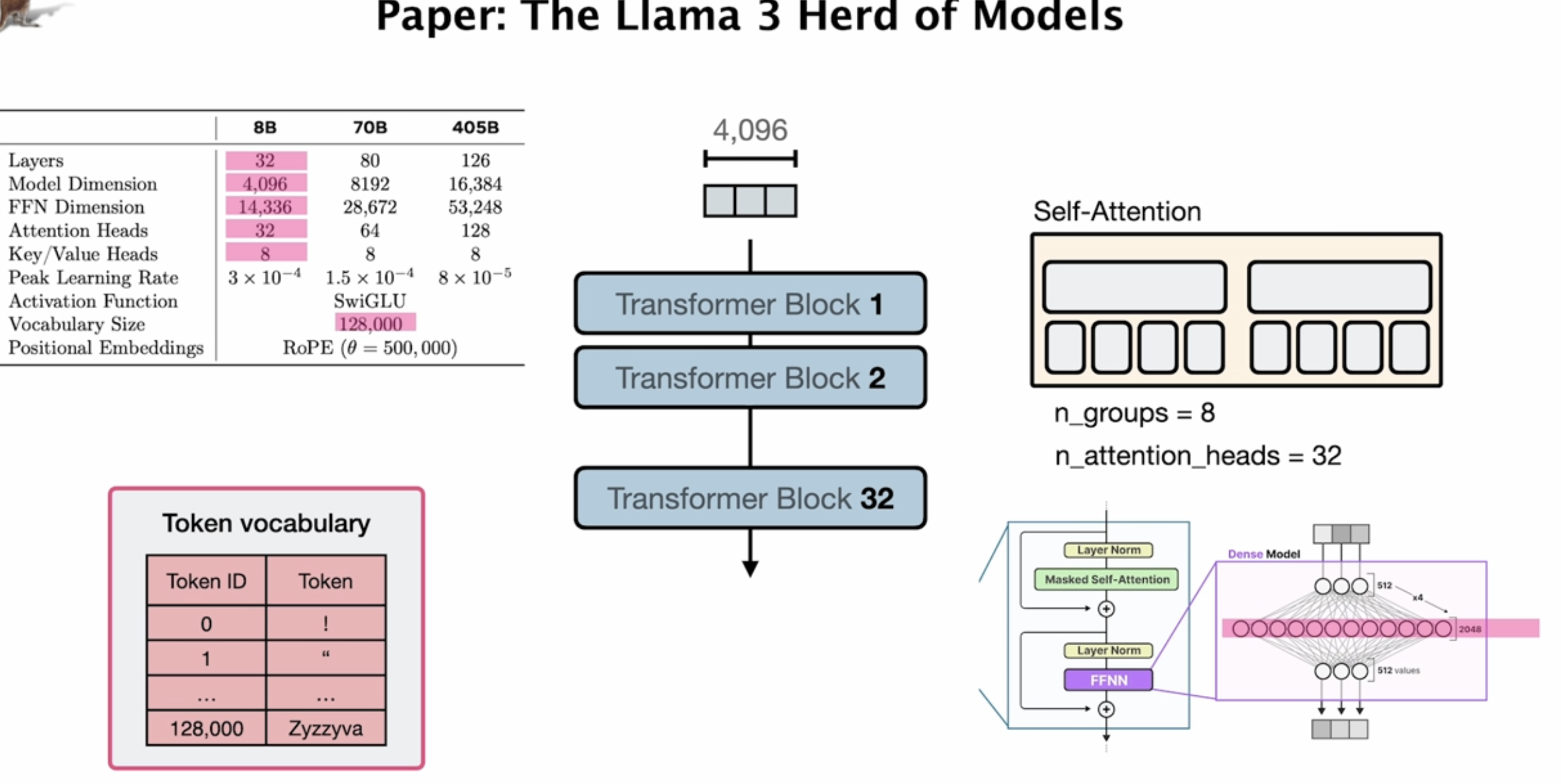
## 1. 模型规格表(左侧)
这个表格展示了三种不同规模的Llama 3模型参数配置:
- 参数规模:8B(80亿)、70B(700亿)和405B(4050亿)
- 层数:8B模型有32层,70B有80层,405B有126层
- 模型维度:即隐藏状态的维度,分别为4,096、8,192和16,384
- FFN维度:前馈神经网络维度,分别为14,336、28,672和53,248
- 注意力头数:分别为32、64和128个
- 键/值头数:所有模型均为8个(这表明使用了分组查询注意力)
- 峰值学习率:不同模型使用不同学习率
- 激活函数:SwiGLU
- 词汇表大小:128,000个token
- 位置编码:RoPE (θ = 500,000)
## 2. 整体结构(中间)
展示了模型的堆叠结构:
- 从Transformer Block 1到Block 32垂直堆叠(针对8B模型)
- 每个block宽度为4,096维度
- 输入从顶部进入,输出从底部输出
## 3. 自注意力机制详情(右上)
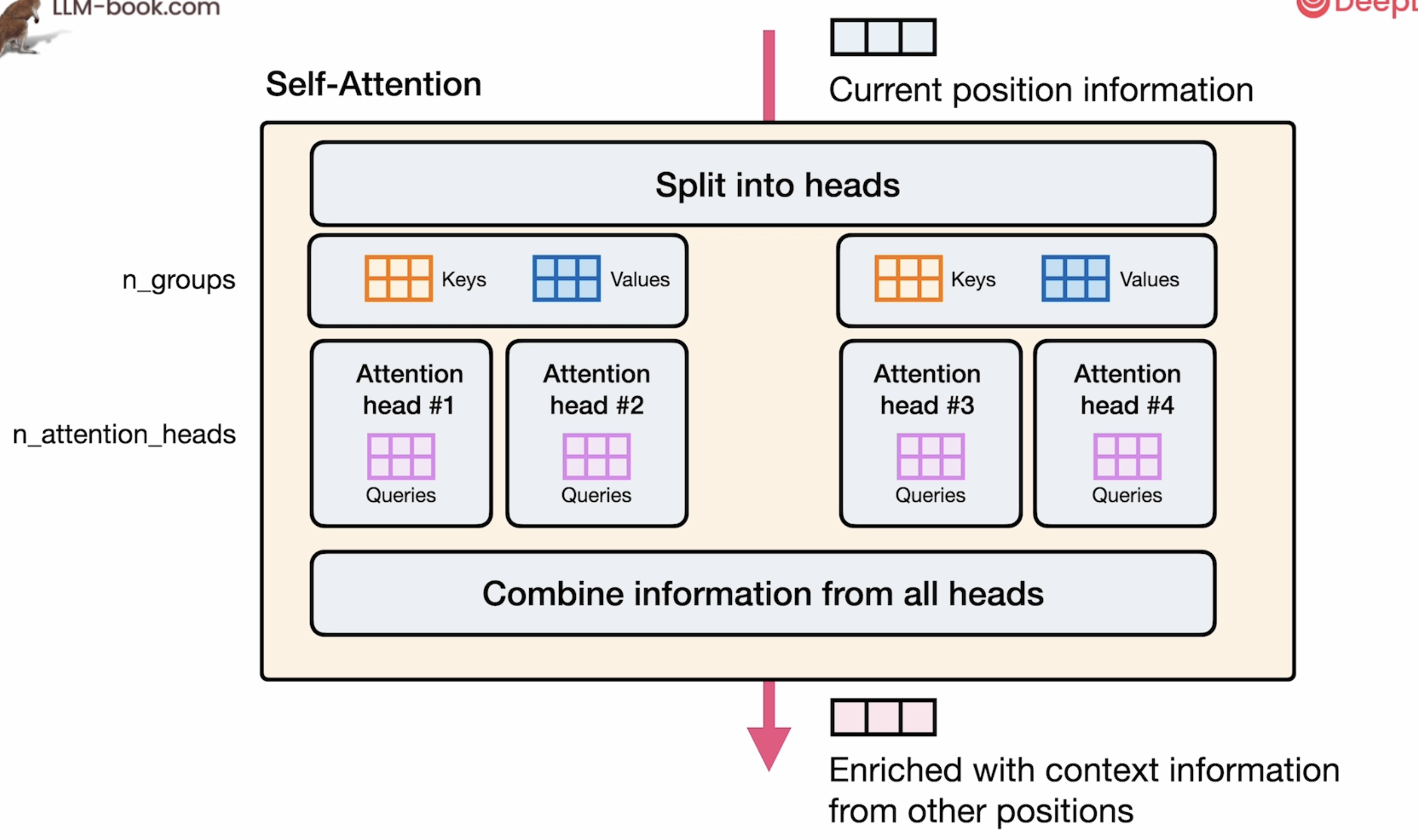
图右上角展示了Llama 3的分组查询注意力机制:
- 8个键值组(n_groups = 8)
- 32个注意力头(n_attention_heads = 32)
- 每个键值组被多个注意力头共享
## 4. Transformer块内部结构(右下)
单个Transformer块的内部结构:
- 层标准化(Layer Norm) → 掩码自注意力(Masked Self-Attention)
- 残差连接(+)
- 层标准化 → 前馈神经网络(FFNN)
- 残差连接
- FFNN详细展开图:包含多层全连接网络和维度信息
## 5. Token词汇表(左下)
词汇表结构示例:
- Token ID从0开始
- 词汇表大小为128,000
- 示例token如"!"、"""等
## 如何阅读论文中类似的模型架构图
当你在论文中遇到类似的架构图时,应按以下步骤解读:
1. 识别关键参数
- 模型规模(参数量)
- 层数
- 隐藏维度
- 注意力头数量
- 特殊机制(如分组查询注意力)
2. 理解模型比例关系
- 注意力维度与模型维度的比例
- FFN维度与模型维度的比例(通常2-4倍)
- 层数与模型尺寸的关系
3. 识别创新点
- 与标准Transformer架构的区别
- 特殊的注意力机制(如分组查询)
- 独特的激活函数或标准化方法
4. 分析扩展策略
- 模型家族如何从小模型扩展到大模型
- 哪些组件随规模成比例扩大,哪些保持不变
5. 注意性能优化设计
- 如何平衡计算效率和模型表现
- 内存优化技术(如键值共享)
6. 查看术语定义
- 不同论文可能使用不同术语描述类似概念
- 关注图例和缩写解释
Llama 3的这种架构图展示了现代大语言模型的核心设计,重点是分组查询注意力机制(每组8个键值共享多个查询)和高效的计算结构,这让它在保持强大性能的同时提高了推理效率。
Model Example
代码采用了HuggingFace的Transformer package做demo。
下面是model的架构:
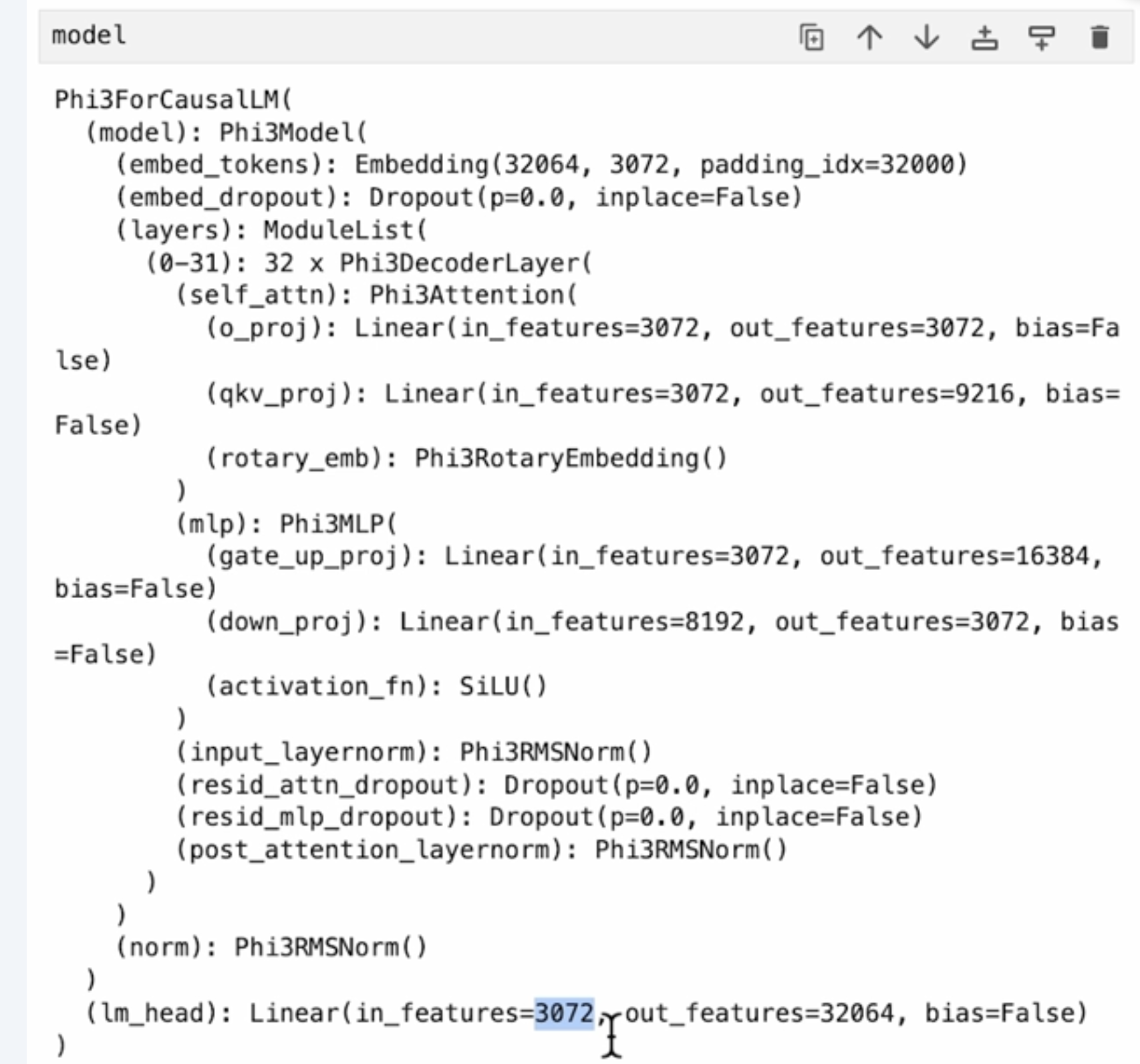
# 微软 Phi-3 模型代码架构详解
## 1. 顶层模型结构
```python
Phi3ForCausalLM(
(model): Phi3Model(
# 模型组件...
)
(lm_head): Linear(in_features=3072, out_features=32064, bias=False)
)
```
- `Phi3ForCausalLM`:因果语言模型的主类,用于自回归文本生成
- `Phi3Model`:基础模型架构
- `lm_head`:输出层,将隐藏状态映射到词汇表概率分布
## 2. 嵌入层
```python
(embed_tokens): Embedding(32064, 3072, padding_idx=32000)
(embed_dropout): Dropout(p=0.0, inplace=False)
```
- 词汇表大小:32,064个标记
- 嵌入维度:3,072
- 填充标记ID:32000
- 嵌入丢弃率:0.0(实际不使用dropout)
## 3. 主体层结构
```python
(layers): ModuleList(
(0-31): 32 x Phi3DecoderLayer(
# 32个相同结构的解码器层
)
)
```
- 层数:32个Transformer块
- 每个块包含注意力机制和前馈神经网络
## 4. 注意力机制
```python
(self_attn): Phi3Attention(
(q_proj): Linear(in_features=3072, out_features=3072, bias=False)
(qkv_proj): Linear(in_features=3072, out_features=9216, bias=False)
(rotary_emb): Phi3RotaryEmbedding()
)
```
- 查询投影(Q):3072 → 3072维度
- 键值投影(KV):3072 → 9216维度
- 9216 = 3072 × 3,暗示使用了分组查询注意力(GQA)
- 键和值共享一个投影矩阵,这与第1张图中的架构一致
- 位置编码:使用旋转位置嵌入(RoPE)
## 5. 前馈神经网络
```python
(mlp): Phi3MLP(
(gate_up_proj): Linear(in_features=3072, out_features=16384, bias=False)
(down_proj): Linear(in_features=8192, out_features=3072, bias=False)
(activation_fn): SiLU()
)
```
- 上投影:3072 → 16384维度(扩展系数约5.33倍)
- 下投影:8192 → 3072维度
- 注意输入维度为8192而非16384,这表明使用了**门控机制**
- 可能的实现:将16384拆分为两半,一半作为门控信号,另一半被门控后成为8192维输入
- 激活函数:SiLU (Swish),即 f(x) = x * sigmoid(x)
## 6. 归一化层
```python
(input_layernorm): Phi3RMSNorm()
(post_attention_layernorm): Phi3RMSNorm()
(norm): Phi3RMSNorm()
```
- 使用**RMS归一化**(非传统Layer Norm)
- 遵循"先归一化后计算"的模式
- 每个子层前都有归一化操作
## 7. 残差连接与Dropout
```python
(resid_attn_dropout): Dropout(p=0.0, inplace=False)
(resid_mlp_dropout): Dropout(p=0.0, inplace=False)
```
- 残差连接中的dropout率均为0.0
- 表明模型在推理阶段不依赖dropout
- 可能使用其他正则化方法或针对推理效率优化
## 8. 模型参数汇总
根据代码分析:
- 隐藏维度:3,072
- 层数:32
- 词汇表大小:32,064
- 总参数量:约38亿参数
- 激活函数:SiLU
- 注意力机制:分组查询注意力(GQA)
- 位置编码:旋转位置嵌入(RoPE)
## 如何阅读论文中的模型架构代码
当你在论文或技术博客中看到类似的模型代码表示时,应该这样分析:
1. 识别模型基础参数
- 查看嵌入维度、层数、词汇表大小等基本信息
- 这些直接决定了模型大小和能力
2. 分析注意力机制
- 查看注意力的类型(如标准、分组查询、多查询等)
- 分析查询、键、值的维度关系
3. 理解前馈网络设计
- 扩展比例(通常为隐藏维度的2-8倍)
- 激活函数选择
- 是否使用了门控机制(输入输出维度关系)
4. 注意特殊组件
- 位置编码方法(如RoPE、ALiBi等)
- 归一化层类型(LayerNorm、RMSNorm等)
- 残差连接和dropout的使用
5. 寻找性能优化痕迹
- 参数共享(如GQA中的键值共享)
- 量化设计(如Int8、FP16等参数量化)
- 推理优化(如KV缓存、稀疏注意力等)
通过上述分析,你可以全面理解模型设计思路,并评估其在特定任务上的潜在表现。Phi-3模型的代码表示非常清晰地展示了其架构选择,包括分组查询注意力、SiLU激活函数和RMSNorm归一化等特点。
Recent Improvements
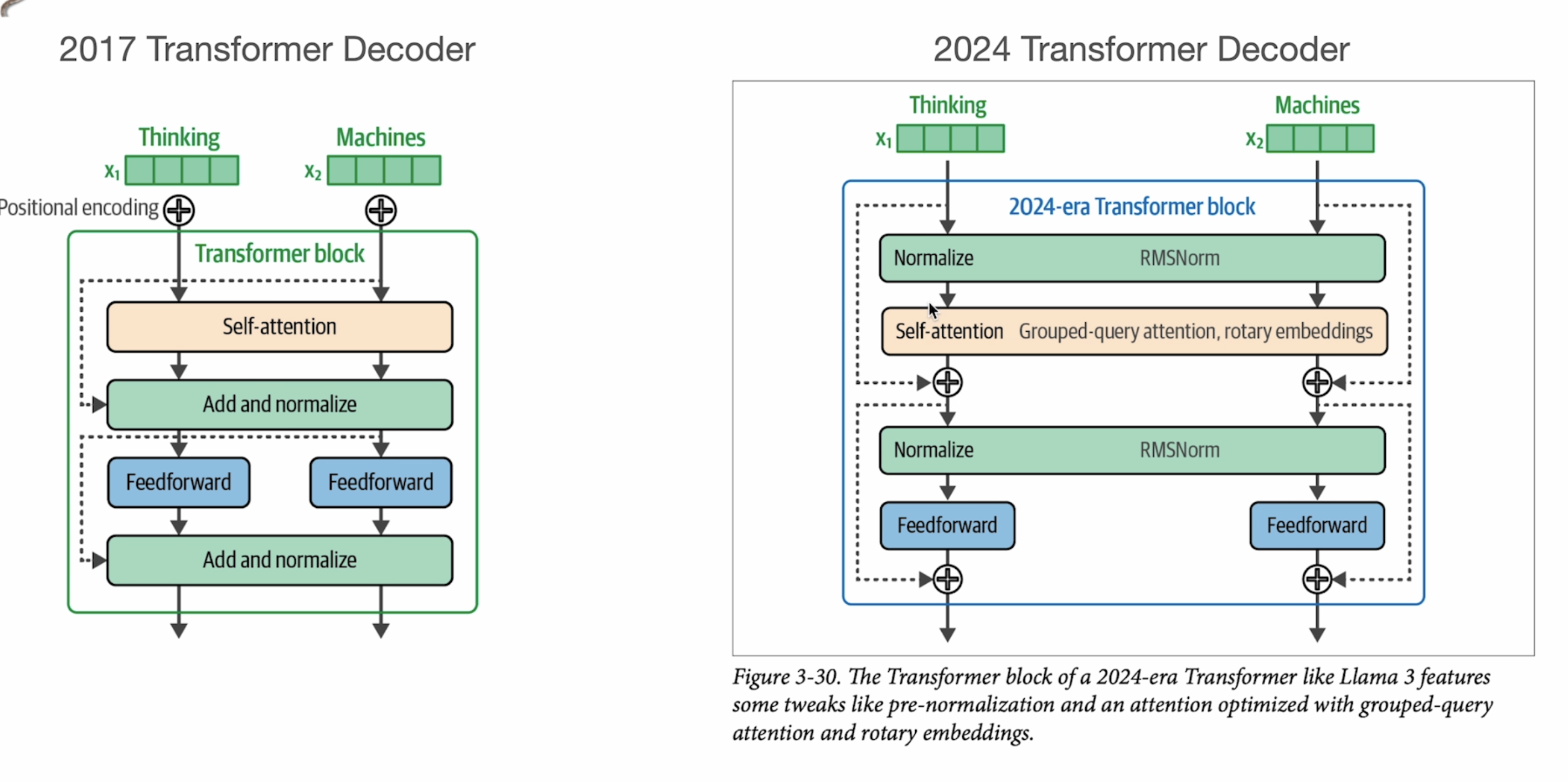
Transformer Decoder的一些变化:
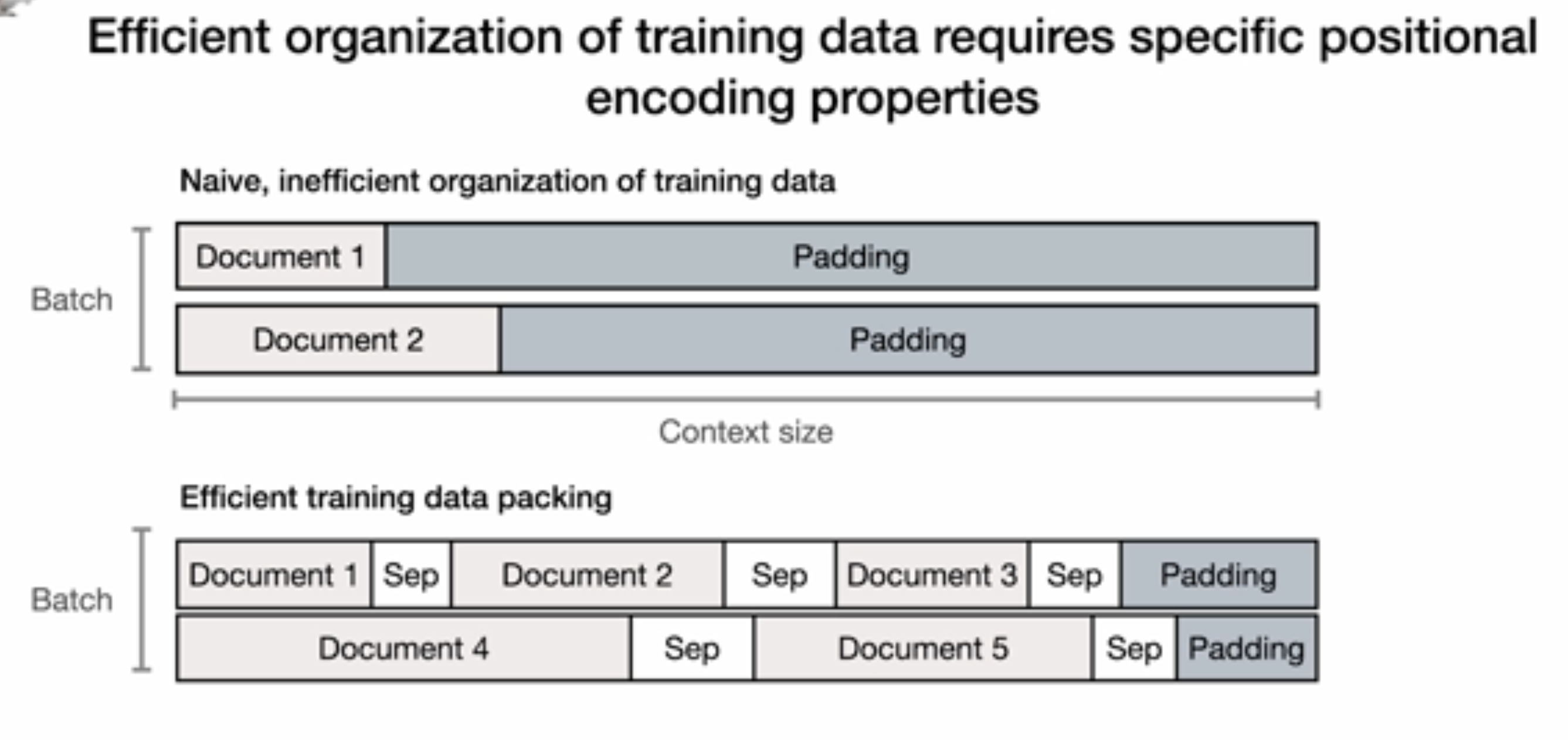
在传统的文档对齐中,我们需要把每个文档变成同样长文本,这就会导致有很多无意义的padding,这里提出了一个有效的方式,将多个短的文本合在一起,这样可以大大降低padding。但是同时引入了新的问题,对于同一行的文档,position信息该怎样处理,比如对于Document2就不应该看到Document1的token信息。
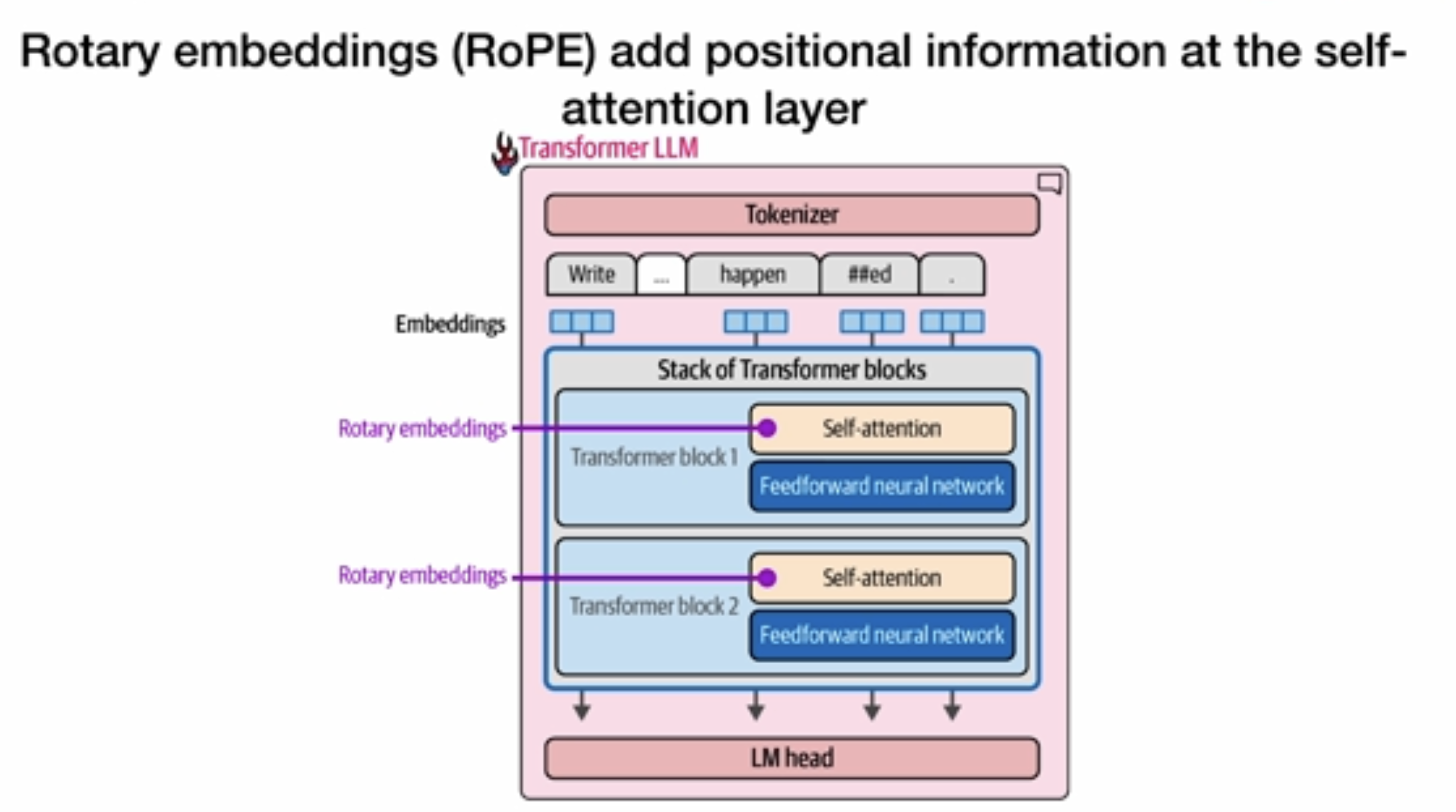
这里采用了一种Rotary embeddings,包含了position信息。
# 旋转位置编码(RoPE)的实现与工作原理:
## 1. 实现位置
- RoPE直接被应用于**每个Transformer块的自注意力层**
- 不同于传统位置编码(如绝对位置编码)添加到输入嵌入中,RoPE被直接应用于**查询和键的计算过程中**
- 如图所示,每个Transformer块的自注意力机制都使用相同的RoPE方法
## 2. 具体应用过程(图5)
从图5可以看到RoPE的精确应用流程:
1. 前置处理:
- 首先,输入通过投影矩阵生成查询(Queries)和键(Keys)向量
- 这些投影矩阵就是图中标为紫色、橙色和蓝色的三个矩阵
2. RoPE应用步骤:
- 图5中间部分标有"Apply rotary positional embeddings"的箭头
- RoPE被**同时**应用到查询(紫色)和键(橙色)上
- 应用后,它们变成了"带有位置信息"的向量
- 值(Values)向量**不需要**应用RoPE
3. Phi-3代码实现(见上面关于模型架构那节):
(self_attn): Phi3Attention(
(q_proj): Linear(in_features=3072, out_features=3072, bias=False)
(qkv_proj): Linear(in_features=3072, out_features=9216, bias=False)
(rotary_emb): Phi3RotaryEmbedding()
)- rotary_emb作为`Phi3Attention`模块的组件
- 在产生Q、K向量后,通过`Phi3RotaryEmbedding`进行旋转变换
## 3. RoPE的数学原理
RoPE通过对查询和键向量应用旋转变换来编码位置信息:
1. 旋转变换:
- 将每个向量按二维子空间分组
- 对每组应用不同频率的旋转变换
- 旋转角度与位置索引成比例
2. 数学表达:
假设d维向量x,位置m,则RoPE的应用为:
RoPE(x, m) = [R_θ,0 ⊗ R_θ,1 ⊗ ... ⊗ R_θ,d/2-1] · x其中R_θ,i是2D旋转矩阵,旋转角度为θ·m·ω^i (ω是预定义的基频)
3. Llama 3设置(图2):
- RoPE (θ = 500,000)表明使用了大基数设置
- 这个大θ值允许模型有效处理更长的上下文
## 4. 为何采用这种方式
1. 相对位置感知:
- RoPE自然能够捕捉token间的相对位置关系
- 使得模型对序列长度变化更加鲁棒
2. 线性外推能力:
- RoPE在训练长度之外的序列上表现良好
- 旋转操作可以线性外推到更长序列
3. 计算效率:
- 实现简单,计算开销小
- 不需要存储额外的位置表
4. 与注意力机制的兼容性:
- 旋转操作保留了点积值的大小,只改变方向
- 完全兼容现有的注意力计算
这种位置编码方式已成为现代LLM的标准,Llama 3和Phi-3等顶级模型都采用了这种方法来处理序列位置信息。
# 旋转位置编码(RoPE)的实际计算示例
我来通过一个简化的计算示例解释旋转位置编码公式:`RoPE(x, m) = [R_θ,0 ⊗ R_θ,1 ⊗ ... ⊗ R_θ,d/2-1] · x`
## 简化示例
假设我们有:
- 4维向量 x = [1.0, 2.0, 3.0, 4.0](表示一个token的嵌入向量)
- 位置 m = 2(序列中的第3个位置,从0开始计数)
- 频率参数 θ = 10000(常用基础值)
## 步骤1:为每对维度创建旋转矩阵
对于4维向量,我们需要2个旋转矩阵(每对维度一个):
- R_θ,0 用于维度0和1
- R_θ,1 用于维度2和3
## 步骤2:计算每对维度的旋转角度
旋转角度公式:`angle_i = m × θ^(-2i/d)`
- 第一对的角度:angle_0 = 2 × 10000^(-2×0/4) = 2 × 1 = 2
- 第二对的角度:angle_1 = 2 × 10000^(-2×1/4) = 2 × 0.01 = 0.02
## 步骤3:构建旋转矩阵
2D旋转矩阵定义为:
```
R(α) = [ cos(α), -sin(α) ]
[ sin(α), cos(α) ]
```
计算得到:
- R_θ,0 = [ cos(2), -sin(2) ] = [ -0.416, -0.909 ]
[ sin(2), cos(2) ] [ 0.909, -0.416 ]
- R_θ,1 = [ cos(0.02), -sin(0.02) ] = [ 0.9998, -0.0200 ]
[ sin(0.02), cos(0.02) ] [ 0.0200, 0.9998 ]
## 步骤4:应用旋转变换
将旋转矩阵应用到对应的维度对:
```
[x0_rot, x1_rot] = R_θ,0 · [x0, x1] = [-0.416, -0.909] · [1.0, 2.0] = [-2.234, 0.077]
[x2_rot, x3_rot] = R_θ,1 · [x2, x3] = [0.9998, -0.0200] · [3.0, 4.0] = [2.919, 4.059]
```
所以最终:RoPE(x, 2) = [-2.234, 0.077, 2.919, 4.059]
## 关键特性
1. 频率递减:注意第二对维度的旋转角度(0.02)比第一对(2.0)小得多
- 这使得不同维度对位置变化的敏感度不同
- 低维度捕获精细的位置关系
- 高维度捕获全局位置结构
2. 相对位置编码:当计算两个经过RoPE变换的向量点积时,结果会反映它们的相对位置关系
- 例如:位置5和7的向量点积结果与位置10和12的点积结果相同
- 这正是为什么它能泛化到更长序列的关键
这就是为什么RoPE在现代大语言模型中如此成功 - 它有效地将位置信息编码到注意力计算中,同时保持了对相对位置关系的敏感性。
让我用更直观的方式解释这两个关于旋转位置编码(RoPE)的关键概念:
## 1. 频率递减的直观解释
想象RoPE就像是一个由多个不同速度旋转的时钟指针组成的系统:
- 低维度对应"秒针":
- 旋转非常快(大角度变化)
- 对位置变化极其敏感
- 例如:位置变化1步,就旋转2弧度
- 高维度对应"时针":
- 旋转非常慢(小角度变化)
- 对位置变化不太敏感
- 例如:位置变化100步,才旋转0.02弧度
这种设计的实际意义:
- 低维度捕获精细位置关系:"这个词和前一个词有关系"
- 高维度捕获全局位置结构:"这个词在段落的前半部分"
实际举例:对于一个token在位置10:
- 第一对维度可能旋转20弧度(大变化)
- 第二对维度可能旋转0.2弧度(小变化)
- 第三对维度可能旋转0.002弧度(极微小变化)
## 2. 相对位置编码的直观解释
假设我们在计算注意力分数,简化情况:
1. 场景A:
- 位置5的token在查询位置7的token
- 相对距离:2
2. 场景B:
- 位置100的token在查询位置102的token
- 相对距离:2
RoPE的神奇之处:**这两种场景会产生完全相同的注意力分数!**
这就像人类语言理解:
- "请看**后面两个**单词"这个指令
- 无论你在文章的开头、中间还是结尾,"后面两个"的相对关系都是一样的
为什么这很重要?
- 模型能学习到"前一个词"、"后两个词"这类普遍模式
- 能处理训练中从未见过的长序列
- 只需学习相对关系,不必记忆每个绝对位置
这正是为什么RoPE能够处理比训练时更长的序列,因为它关注的是相对位置关系,而非绝对位置。
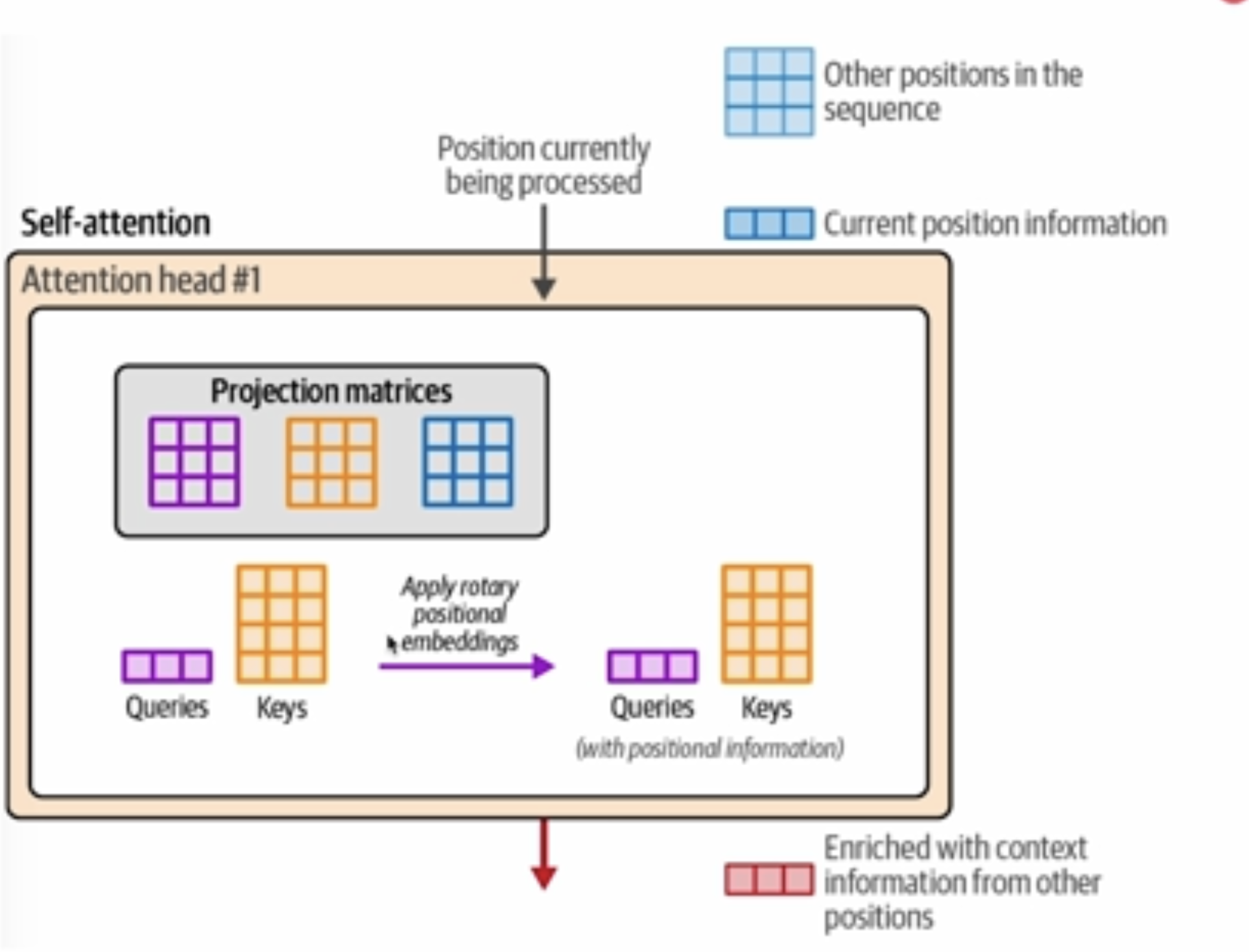
在自注意力机制中,当我们说"位置5的token在查询位置7的token"时,我们描述的是注意力计算的具体过程。让我详细解释这个查询过程:
## 自注意力中的查询过程
1. 初始表示:
- 位置5的token被转换为嵌入向量并投影成**查询向量Q₅** (紫色矩阵)
- 位置7的token被转换为嵌入向量并投影成**键向量K₇** (橙色矩阵)和**值向量V₇** (蓝色矩阵)
2. 应用RoPE:
- 位置信息通过旋转位置编码加入查询和键向量:
- Q₅ 变成 RoPE(Q₅, 5) - 根据位置5旋转的查询向量
- K₇ 变成 RoPE(K₇, 7) - 根据位置7旋转的键向量
- 这在图5中清晰显示,紫色和橙色向量被"Apply rotary positional embeddings"处理
3. 注意力分数计算:
- 计算两个旋转后向量的点积:score = RoPE(Q₅, 5) · RoPE(K₇, 7)
- 数学上,这个点积仅依赖于**相对距离**:f(Q₅, K₇, 7-5) = f(Q₅, K₇, 2)
- 所以不管是位置(5,7)还是位置(100,102),只要相对距离都是2,计算出的注意力分数模式是相同的
4. 注意力权重获取:
- 这个分数和其他所有分数一起通过softmax归一化,产生注意力权重
- 权重表示位置5应该"关注"位置7多少
5. 信息聚合:
- 位置5使用这些权重从所有可访问位置(包括位置7,如果是双向模型)聚合信息
- 具体是对所有值向量进行加权求和:output₅ = Σ(attention_weight × value_vector)
这就是模型中"位置5查询位置7"的完整过程。RoPE的设计使得这个查询过程自然包含相对位置信息,让模型能学习"查询前两个词"或"查询后三个词"这样的位置相关模式,而不必依赖绝对位置。
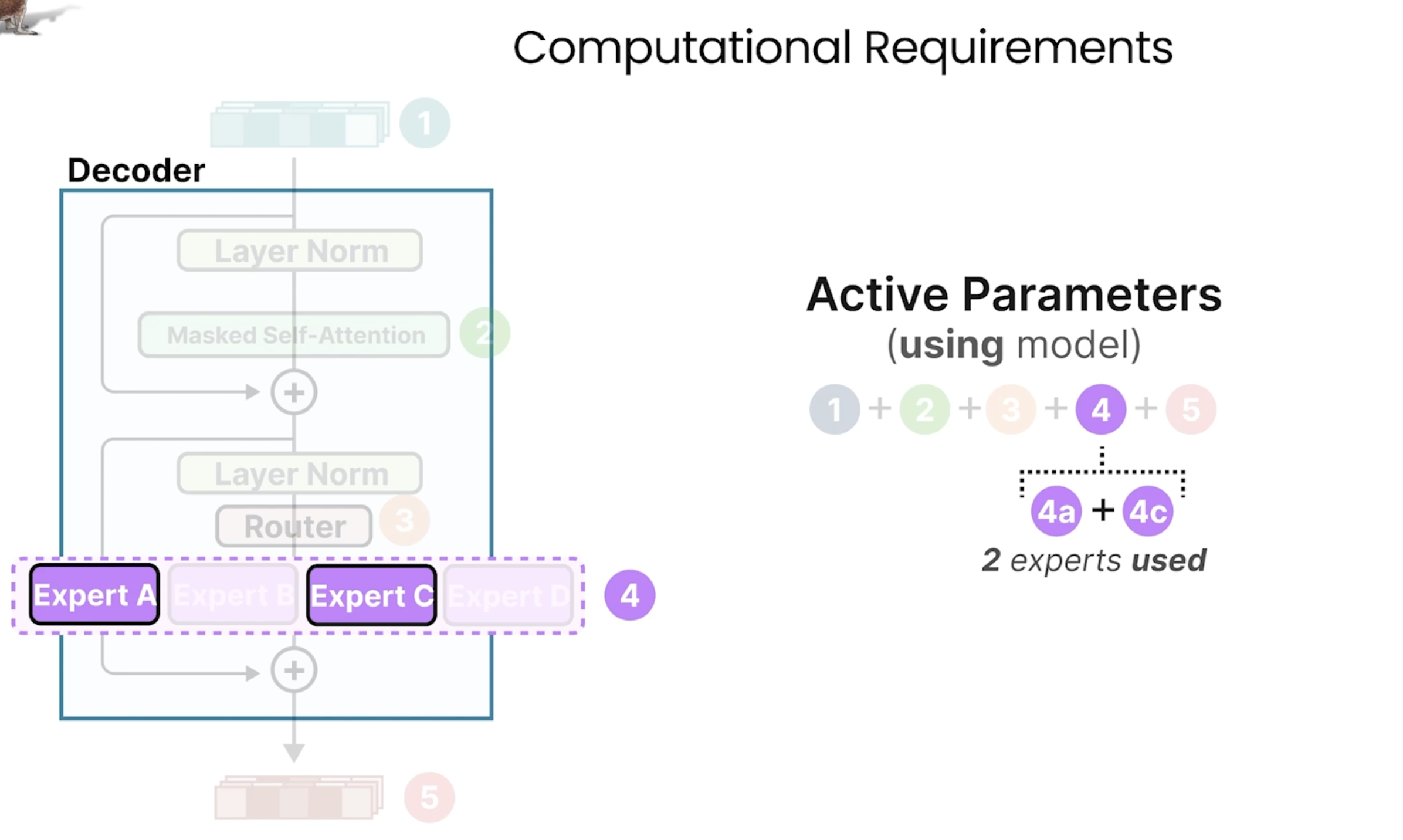
Mixture of Experts(MoE)
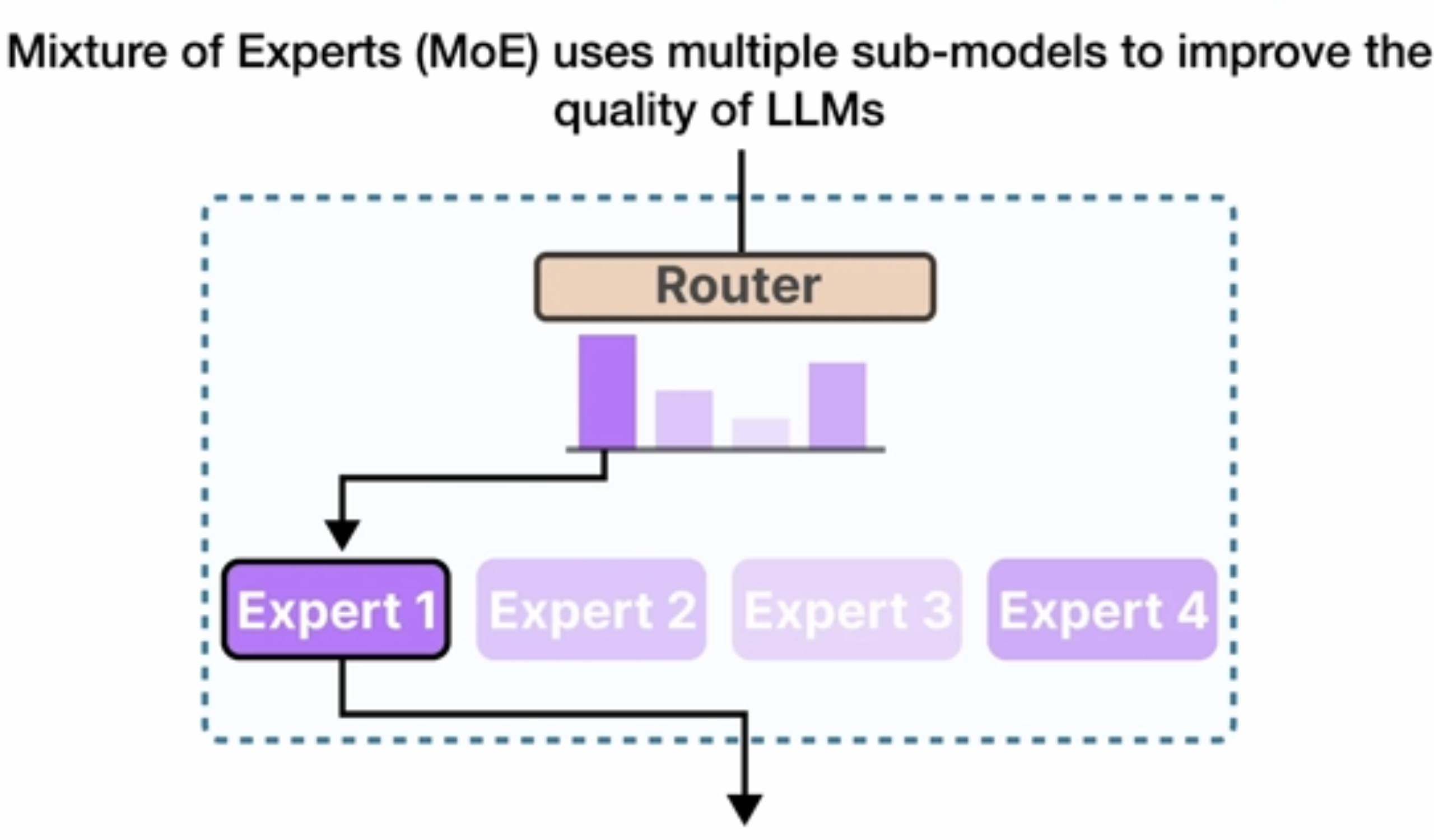
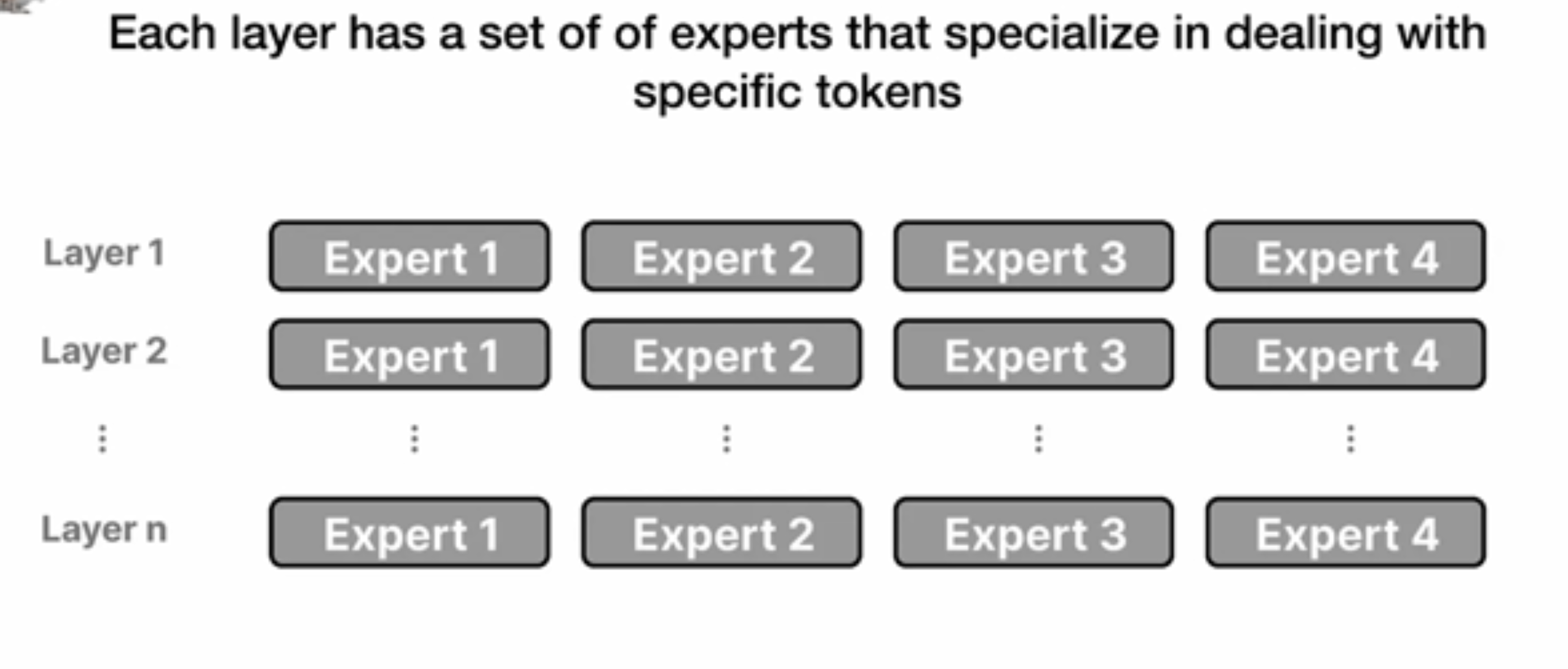
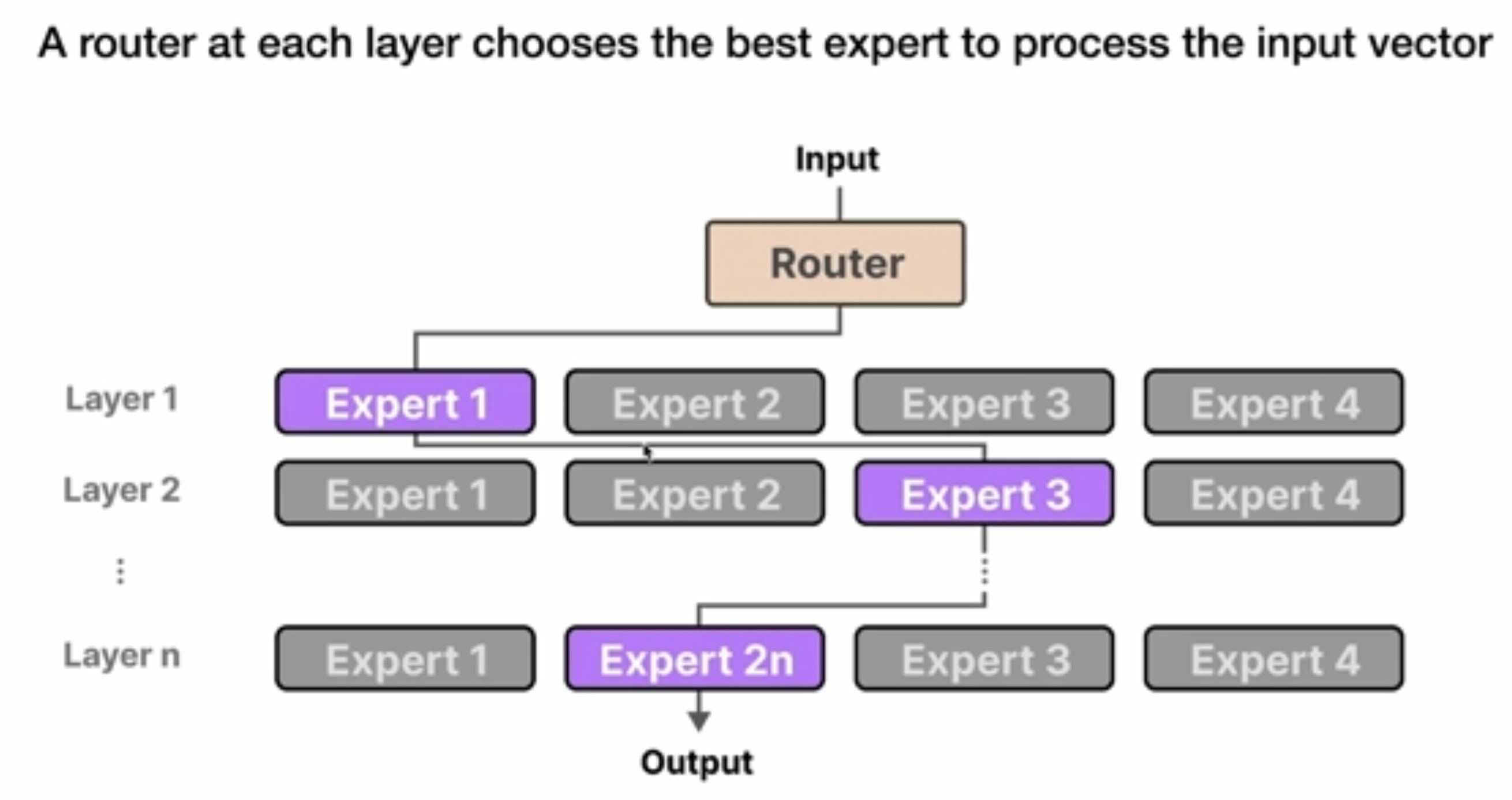
这里的Epxerts并不是我们想的比如针对某个特定领域的知识专家,而是关注于不同点的expert:如下图所示。
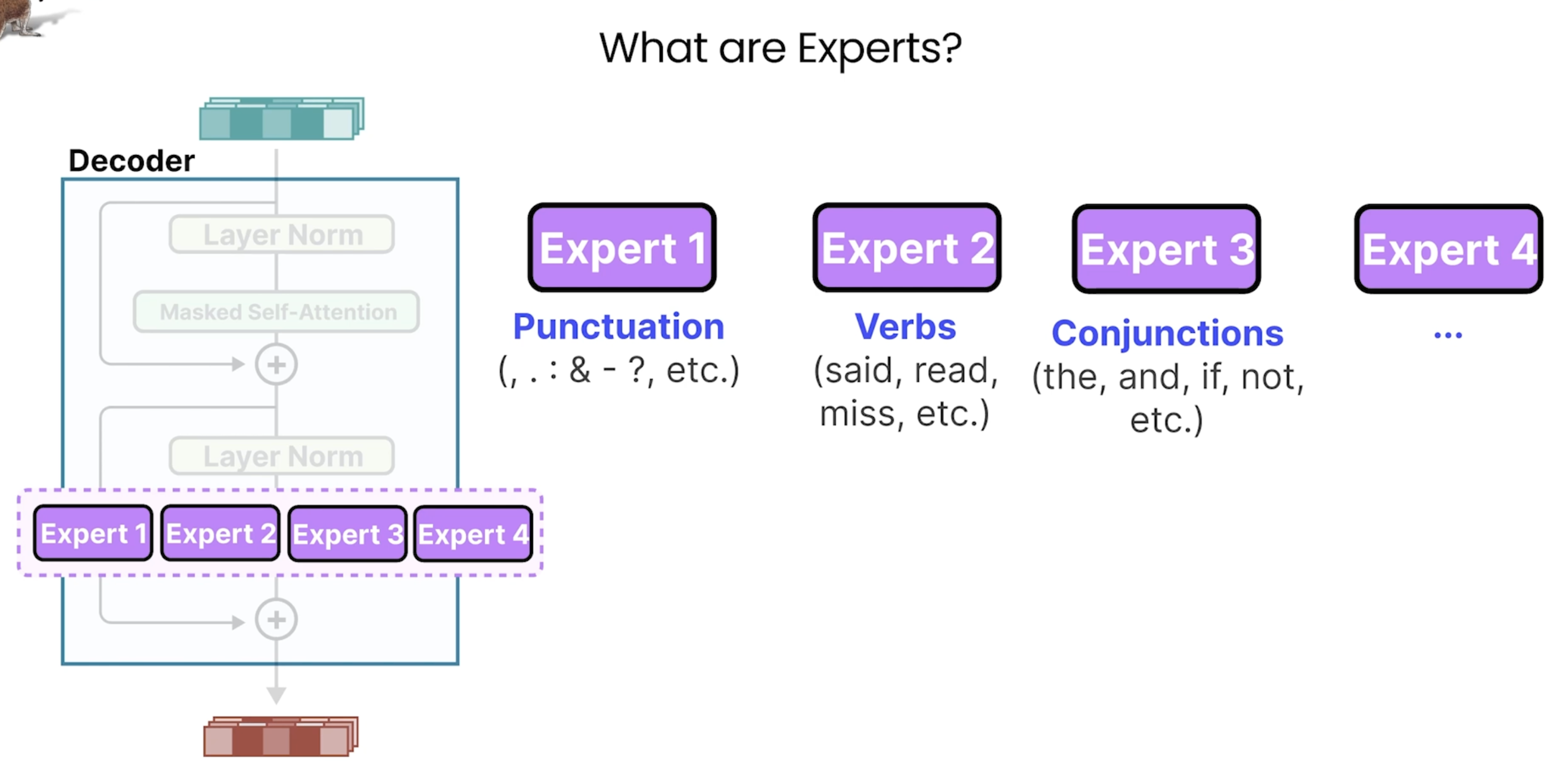
在每层每次会通过Router去选择会激活一个活多个Experts:
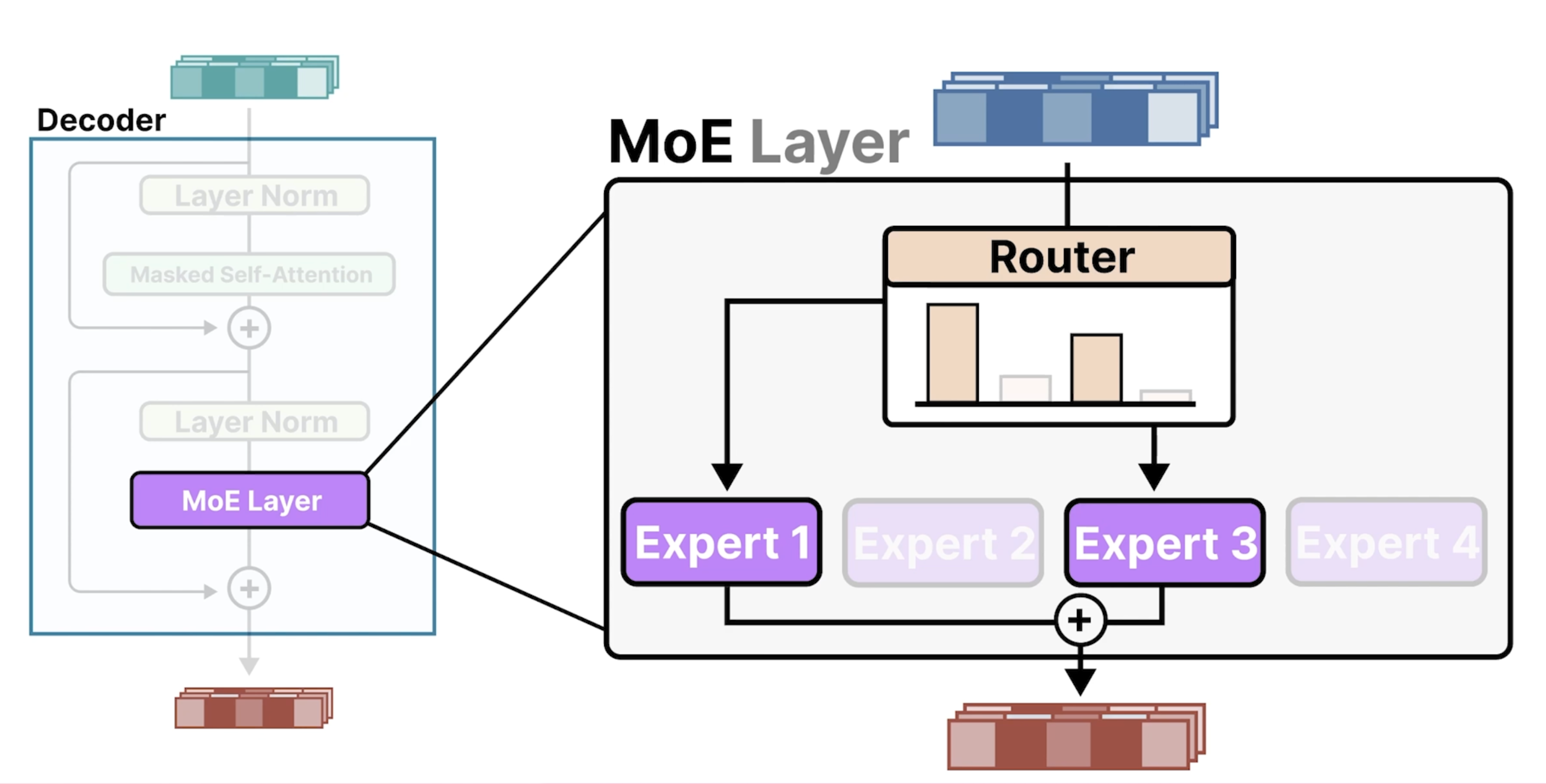
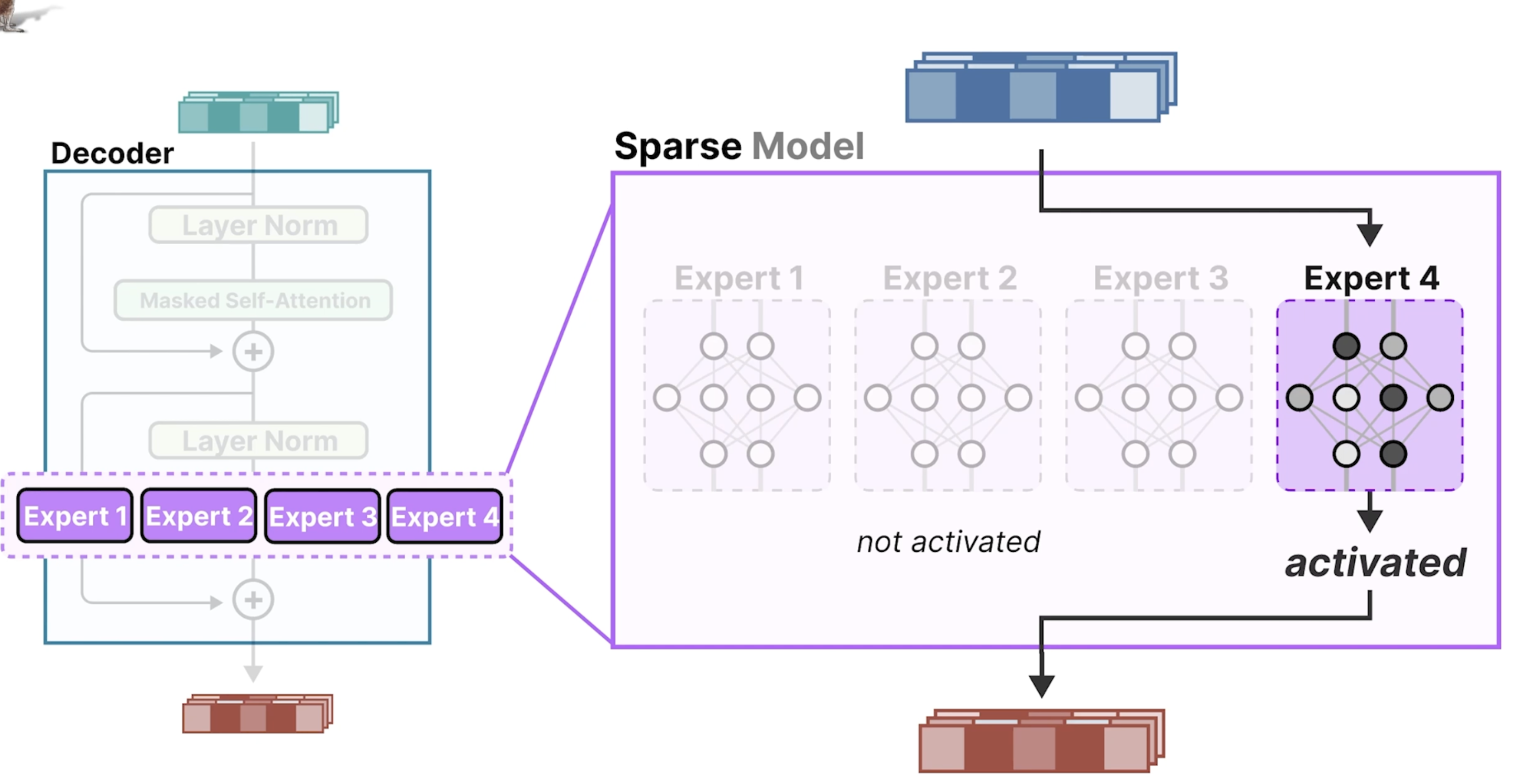
下面总结了需要算力的几个方面:在做训练时,需要将所有的expert的参数全加载到内存中,但是在做推理时,每次只会选择个一个Expert。