课程链接:https://learn.deeplearning.ai/courses/open-source-models-hugging-face/lesson/1/introduction
代码:https://github.com/MSzgy/Open-Source-Models-with-Hugging-Face
Introduction
本课程是由大名鼎鼎的Huggingface带来的,包括了文本,图像,音频各种model的实践,对于想搭建自己的LLM app来说,是个不可多得的宝库。在huggingface中,有着大量的开原模型,数据集以及方便实用的python package(transformers, accelerator等)。
Selecting models
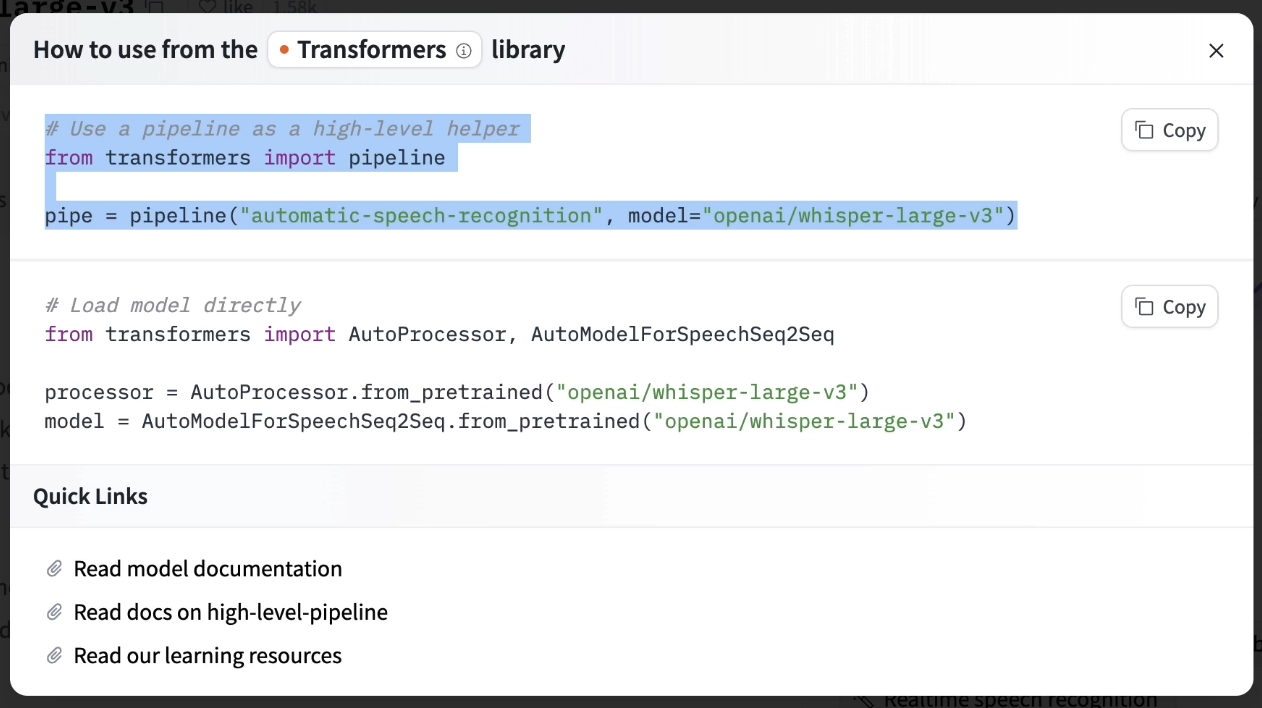
在huggingface主页,根据你想要的任务可以找到相应的model。可以在UI上找到相应的model。
除此以外,可以通过transformers库导入model。
Natural Language Processing(NLP)
Chatbot leaderboard: https://huggingface.co/spaces/awacke1/lmsys-chatbot-arena-leaderboard
Translation and Summarization
在本节代码中,pipeline中参数torch_dtype设置的bfloat16,在这里做个介绍。
translator = pipeline(task="translation",
model="./models/facebook/nllb-200-distilled-600M",
torch_dtype=torch.bfloat16) torch.bfloat16 是 PyTorch 中的数据类型,表示一种 16 位浮点数格式,称为 Brain Floating Point 16 (bfloat16)。它由 Google 设计,主要用于加速深度学习中的计算。与常见的 16 位浮点数格式(例如 float16)不同,bfloat16 的有效位(即尾数)比 float16 少,但它的指数位数和 32 位浮点数(float32)一样,这使得它在保留较大的数值范围的同时,可以提供较高的计算效率。
bfloat16 的特点:
• 数值范围:bfloat16 的数值范围与 float32 相同,因此在数值较大时不容易溢出。
• 精度:bfloat16 只有 7 位有效位,因此精度较低,不适合所有场景,但在深度学习模型中,特别是前向传播和反向传播的计算中,通常足够。
• 加速计算:bfloat16 在一些硬件(如 Google 的 TPU 和部分 GPU)上有加速支持,使得在不显著影响模型性能的情况下可以加快训练和推理速度,并减少显存占用。
在使用 PyTorch 时,可以通过将模型的权重和数据类型转换为 bfloat16 来加速模型训练和推理,特别适合大型神经网络模型的训练。
Zero-Shot Audio Classification
CLAP model
CLAP(对比语言-音频预训练)模型通过对比学习来连接语言和音频,类似于CLIP(对比语言-图像预训练)在语言和图像之间建立联系。CLAP的主要目标是创建一个通用的表示空间,将同一概念的语言描述和音频片段放在更接近的位置,这样可以通过文字搜索音频,或通过音频查找对应的文字描述。
以下是CLAP的关键点:
1. 架构:CLAP通常包含音频编码器和文本编码器。音频编码器负责处理音频输入,提取音频特征;文本编码器则处理语言输入。通过对比学习,模型学会在一个联合的嵌入空间中对齐这些表示。
2. 训练过程:模型通过音频和文本对(例如,声音片段与文本描述配对)进行训练,使用对比损失函数,使匹配的音频-文本对的嵌入更接近,而不匹配的对则相互远离。
3. 应用场景:
• 音频检索:CLAP可以通过输入文本描述来查找相关的音频样本(如“猫叫声”、“雷雨声”等)。
• 自动音频标签:该模型可以对音频文件进行分类或打标签。
• 多模态任务:CLAP可以在涉及音频的多模态任务中使用,例如音频-视觉模型或文本生成音频系统。
4. 实际应用:
• 声音库的搜索引擎,用户可以输入文本查询来查找合适的音频样本。
• 基于声音的推荐系统。
• 媒体分析中需要标记音频片段的场景(如合规检查或分类)。
CLAP的架构和应用推动了音频AI领域的发展,让用户可以通过自然语言更加便捷高效地与音频数据交互。
sampling rate
在语音处理中,需要注意采样率是否与model一致,采样率的不同则会导致音频信号失真。
Automatic Speech Recognition
在本节中,利用简化版的whisper model以及gradio搭建了个语音识别app。
whisper model
Whisper 是 OpenAI 开发的一个通用语音识别(ASR)模型,主要用于高精度的语音转文本任务。它采用了 Transformer 架构,通过大规模的多语言、多任务语音数据训练,在语音识别、翻译和语音转文本任务上表现出色。以下是 Whisper 的主要特点和功能:
Whisper 的特点
1. 多语言支持:
• Whisper 支持多种语言的识别和转录,能够处理包含不同口音和语言的音频。
• Whisper 还具备多语言的翻译功能,可以将音频内容直接翻译成指定的目标语言。
2. 强大的鲁棒性:
• Whisper 在嘈杂背景、不同录音条件下依然表现良好,对非理想音频(如噪声、口音、远场录音等)具有较强的鲁棒性。
• 它可以在较低信噪比的音频条件下提供可靠的转录。
3. 多任务训练:
• Whisper 是通过多任务学习训练的,不仅仅限于语音识别任务,还可以完成语音翻译和语言检测。
• 由于使用了多任务数据训练,它在处理不同任务时表现稳定,具有一定的泛化能力。
4. 高采样率和特定采样率要求:
• Whisper 的输入采样率为 16 kHz,因此在使用时需将音频采样率调整为 16 kHz,以确保数据与模型的要求一致。
• Whisper 通过频谱图输入,即先将音频转为频谱图特征,再输入模型进行处理。
5. 开源与易用性:
• Whisper 是开源的,用户可以在 GitHub 上获取代码和模型权重,并根据需要在自己的项目中使用。
• 它提供多种模型尺寸,从较小的模型(适合快速处理和较低算力需求)到大型模型(适合高精度转录),用户可以根据硬件和精度需求进行选择。
Whisper 的应用场景
1. 语音转文本(STT):
• Whisper 的主要应用是将语音音频转为文字,非常适用于实时语音识别、会议记录、内容转录等任务。
2. 实时字幕生成:
• 由于其较高的准确性和多语言支持,Whisper 可用于视频的实时字幕生成,帮助观众跨语言理解视频内容。
3. 多语言翻译:
• Whisper 能够从一种语言的音频直接翻译到另一种语言的文本,可以用于语言学习和跨语言交流。
4. 辅助听障人士:
• Whisper 可以实时将语音转成文本,对于听障人士是一项重要的辅助工具。
使用 Whisper 的注意事项
• 硬件要求:较大的 Whisper 模型需要显著的计算资源(如高性能 GPU)来进行高效推理。小模型则在低算力环境中表现较好。
• 数据预处理:在使用时,确保音频的采样率为 16 kHz,且音频质量良好,这样可以获得更准确的转录结果。
• 延迟:在实时应用中可能会存在一定延迟,尤其是大型模型,适合对实时性要求较低的场景。
Whisper 的出现使得多语言和多任务的语音识别更加便捷,它可以用于广泛的语音应用场景。
Text to Speech
Object Detection
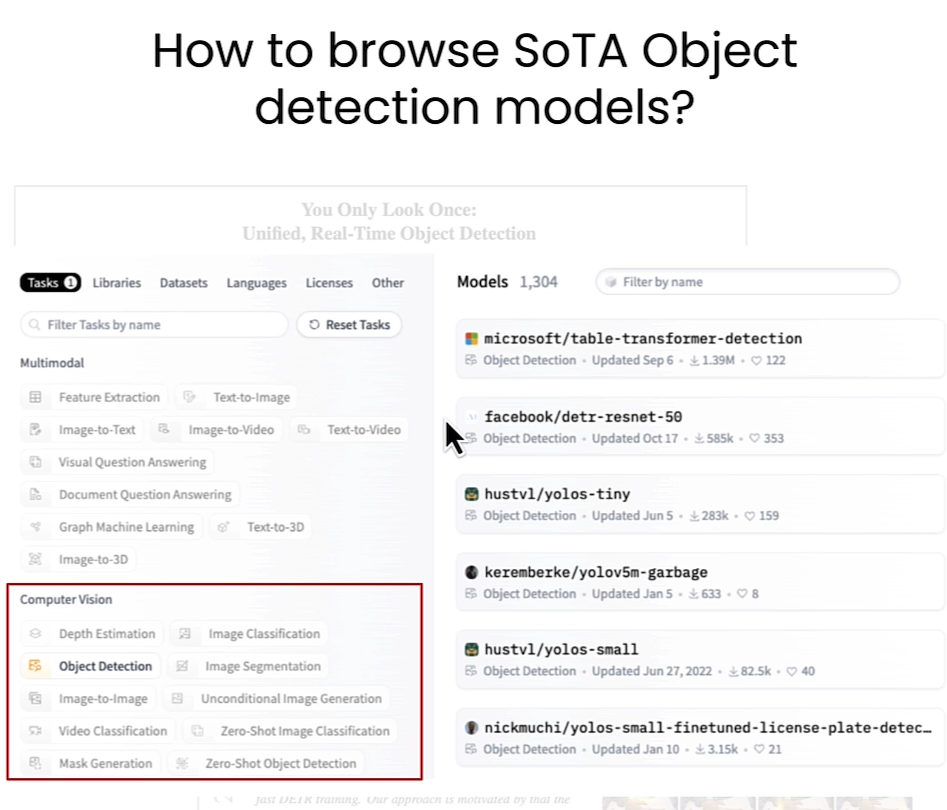
在本节举了一个目标识别的例子,用了facebook/detr-resnet-50 model
我们可以在Huggingface官网去找到一些Object Detection model。
下面的例子可以将图片转为文本,然后通过Text-to-Speech model转成语音。
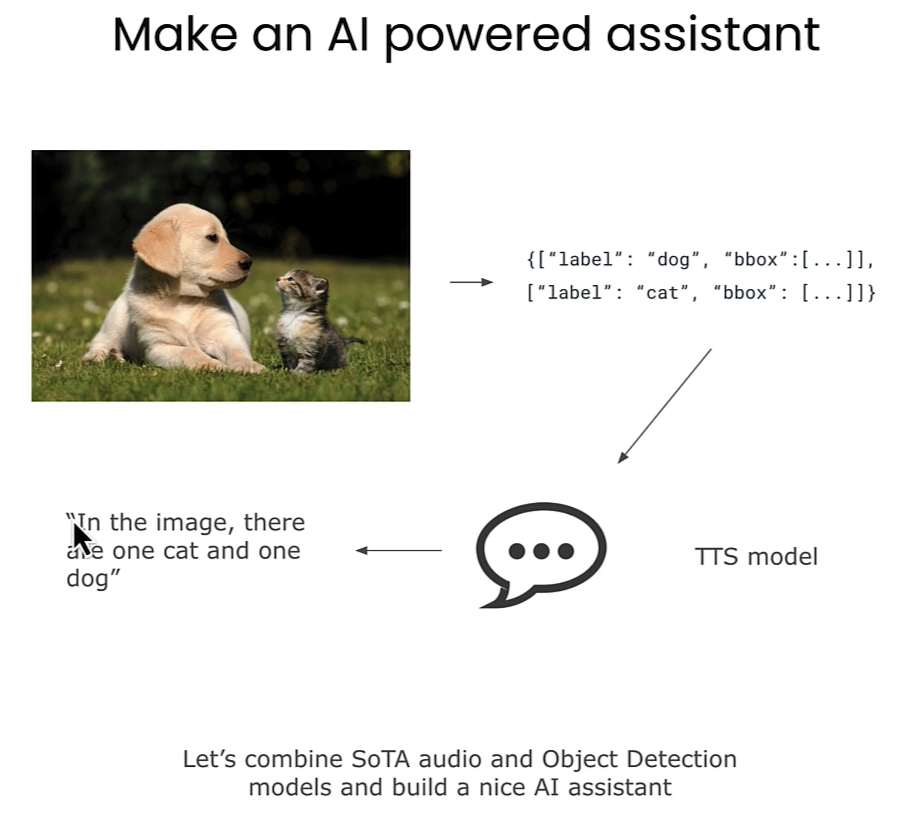
Image Segmentation
Segmentation Mask Generation 是一种在计算机视觉中的技术,主要用于识别图像中不同区域的像素级别的内容。这种技术可以精确地将图像分割为不同部分,通过生成一个“掩码”来表示图像的各个部分所属的类别。
主要内容:
1. 像素级分类:与传统的目标检测不同,分割掩码生成(Segmentation Mask Generation)对每一个像素进行分类,从而在图像上形成更细粒度的分割结果。
2. 掩码生成:生成的掩码(Mask)通常是一个与输入图像尺寸相同的矩阵,其中每个像素的值代表其所属类别。例如,在一张道路图像中,掩码可以标识出道路、建筑、树木和天空等不同部分。
3. 实例分割和语义分割:
• 语义分割(Semantic Segmentation):将图像中的每个像素按照类别进行分割,但不区分个体实例。例如,一张图片中所有的树都属于“树”这个类别。
• 实例分割(Instance Segmentation):不仅分割类别,还区分个体实例。比如,图像中不同的树会被分割为不同的实例。
应用场景
• 自动驾驶:用于识别道路上的行人、车辆、交通标志等。
• 医疗影像:帮助标记病灶区域,辅助诊断。
• 虚拟试衣、图像编辑等场景。
常用方法
• 深度学习模型:如UNet、Mask R-CNN等卷积神经网络模型,特别适合图像分割任务。
• Transformer:近年来,Vision Transformer(ViT)等模型也逐渐在分割任务中取得了较好的效果。
总的来说,Segmentation Mask Generation 是一种关键的计算机视觉技术,用于生成高精度的图像分割掩码,以实现更深入的图像理解和分析。

下面这张图片展示了 Segment Anything Model (SAM) 的架构和工作原理。SAM 是一种用于分割掩码生成的先进模型,可以在图像中自动生成物体的分割掩码。以下是图片的分解说明:
1. 上方的图像示例:上方的彩色图片显示了一个街道场景,其中每个物体(如电车、建筑物、树木等)都被不同颜色的轮廓标记出来。这些颜色区域代表 SAM 自动生成的分割掩码,帮助识别出图像中的每个物体。
2. 架构流程图:
• Image Encoder(图像编码器):输入图像首先通过图像编码器进行编码,生成图像的嵌入表示(Image Embedding),用于后续的掩码生成。
• Prompt Encoder(提示编码器):SAM 支持不同的提示类型(如点、框、文本),通过提示编码器处理这些提示信息。这种设计让用户可以为模型提供提示,指定希望分割的区域或物体。
• Mask Decoder(掩码解码器):图像嵌入和提示信息一起输入掩码解码器,生成有效的分割掩码(Valid Masks)。解码器会为每个掩码生成一个得分,指示掩码的置信度。
• 输出有效掩码:最终输出不同得分的有效掩码,显示不同物体的分割区域。
3. 自动掩码生成管道的结果:在架构图右侧,示例显示了自动生成的掩码叠加在物体(如剪刀)的图像上,以及它们对应的置信度得分。这展示了 SAM 在实际图像上生成掩码的效果。
总结:SAM 可以自动或通过提示生成精确的分割掩码,具有很高的通用性和可用性,在多个场景下都能进行物体的精细分割。
image Retrieval
在本节中将会使用多模态模型,本节使用的事来自salesforce的BLIP model。
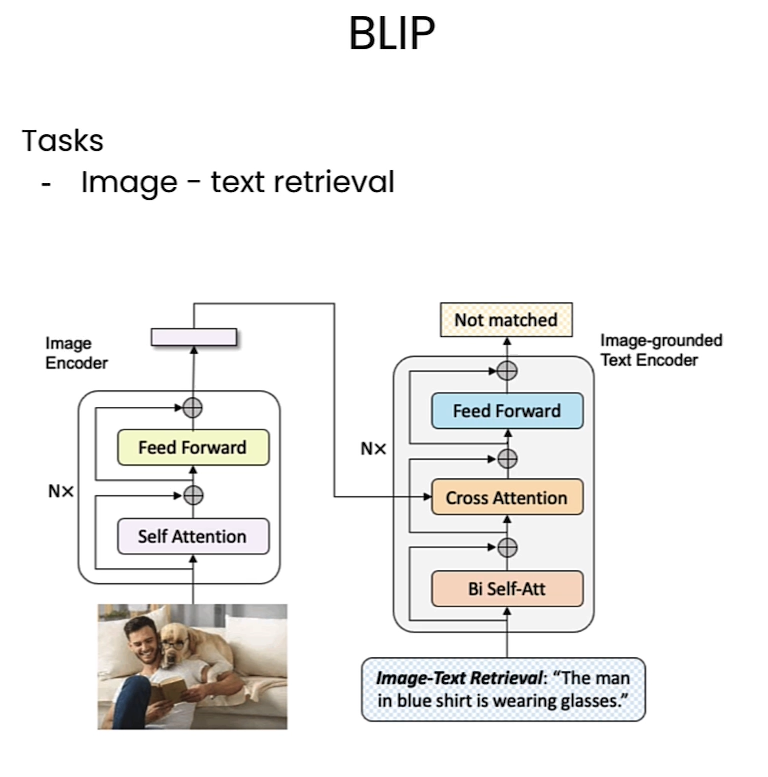
Image Captioning
在这节中利用BLIP model举了个例子,给定图片,让model补全与图片有关的文本。直接看代码就行了,在这里也简单介绍下transformers库中的一些参数意义。
在 Hugging Face 的 transformers 库中,input_ids 和 attention_mask 是两个重要的张量,通常在处理文本数据时使用。它们的含义如下:
1. input_ids:
• input_ids 是将输入文本转换成的词汇表索引序列。每个标记(token)都被映射到词汇表中的唯一编号,以便模型可以理解和处理输入。
• 例如,给定一个句子 "Hello world",模型的 tokenizer 会将其分解成标记,并为每个标记分配一个唯一编号,这些编号就是 input_ids。
2. attention_mask:
• attention_mask 是一个布尔张量,用于告诉模型应关注的标记位置。通常在使用填充(padding)时使用,填充位置的值为 0,实际内容位置的值为 1。
• 例如,如果输入序列需要填充到固定长度,则多余的填充值不会被模型关注,这就是 attention_mask 的作用。
在实际模型计算时,input_ids 为模型提供具体的内容,而 attention_mask 则帮助模型忽略无意义的填充部分,专注于实际的句子内容。这两个张量一起使得模型在批处理中可以更高效地处理不同长度的句子。
Multimodal Visual Question Answering
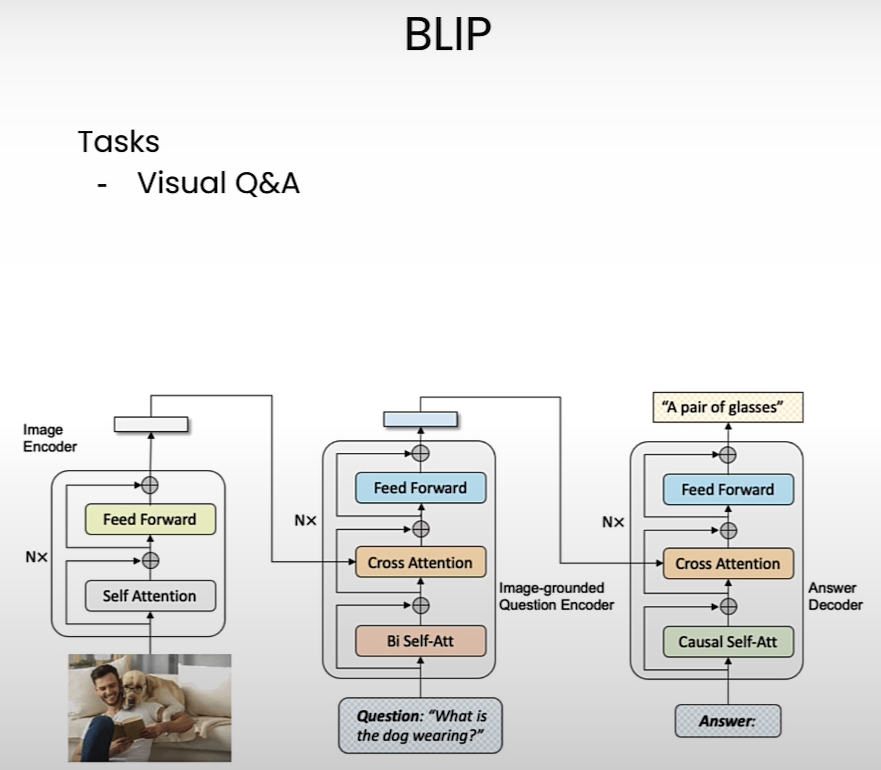
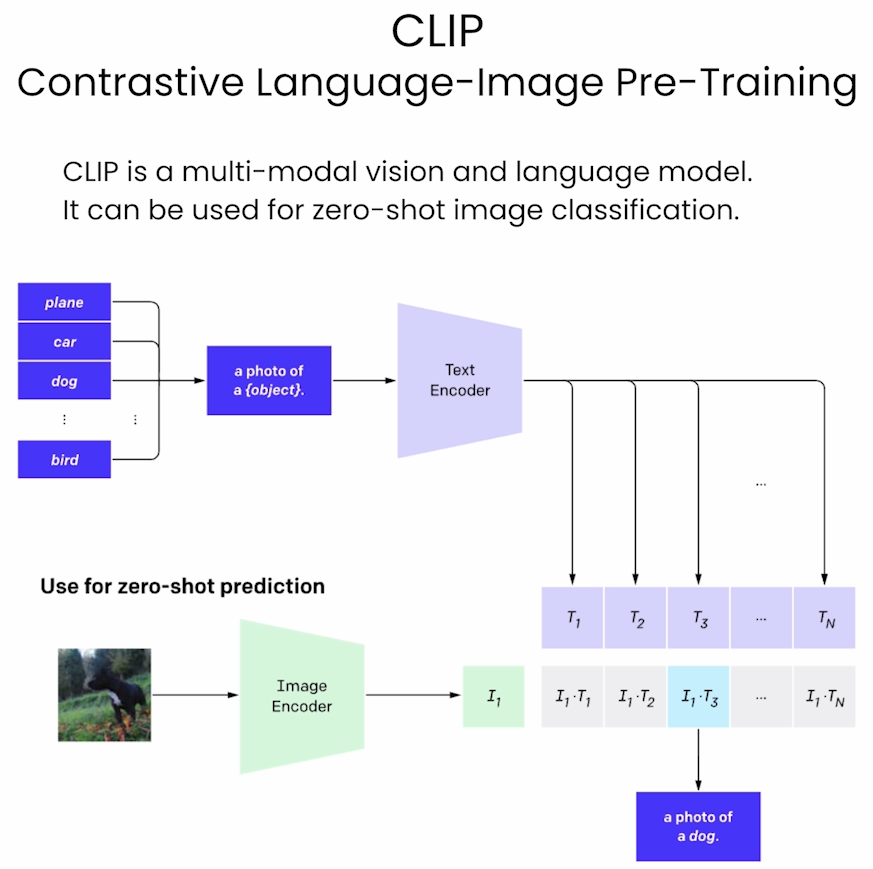
Zero-Shot Image Classification
本节使用了OpenAI的CLIP model。下面是对这个model的介绍。
CLIP (Contrastive Language–Image Pretraining) 是由 OpenAI 开发的一种模型,用于连接自然语言和视觉信息的预训练模型。它能够理解图像和文本之间的关系,并广泛应用于多模态任务,比如图像搜索、图像分类、图文匹配等。
CLIP 模型的工作原理和特点如下:
1. 模型架构
CLIP 是一种双塔结构的模型,包含一个文本编码器和一个图像编码器:
• 文本编码器: 通常是一个基于 Transformer 的模型(如 GPT 或 BERT),负责将输入的文本描述转换为一个文本特征向量。
• 图像编码器: 通常是一个卷积神经网络(如 ResNet)或 Vision Transformer(ViT),将图像输入转换为图像特征向量。
这两个编码器会将不同模态的数据映射到同一个向量空间中,以便在该空间中进行对比学习。
2. 对比学习
CLIP 使用对比学习(contrastive learning)进行训练。具体来说:
• 模型接受一组图像-文本对(例如,一张图和它的描述),并尝试在特征空间中将图像和文本嵌入拉近。
• 同时,将不相关的图像-文本对在特征空间中分开。
训练过程中,CLIP 通过最大化正确的图像-文本对的相似度,同时最小化错误对的相似度,实现了“图像理解”和“文本理解”能力。
3. 应用场景
由于 CLIP 可以将图像和文本投射到相同的嵌入空间中,所以可以直接用于许多多模态任务:
• 零样本分类: CLIP 不需要特定的数据集微调,就能基于自然语言描述进行图像分类。这使得 CLIP 能在新的分类任务上很好地表现。
• 图像-文本匹配: 可以用于在一组图像中找到最匹配的文本描述,或在一组文本中找到最相关的图像。
• 图像搜索: 将文本作为查询,搜索和匹配与之最相似的图像。
CLIP 的优势
• 多模态特性: CLIP 是一个联合视觉和语言的模型,适用于多模态任务。
• 零样本能力: CLIP 可以在没有特定任务的训练数据情况下直接用于新任务(如分类),具有强大的泛化能力。
• 开放域的知识理解: 由于 CLIP 预训练在大量互联网图文数据上,它在广泛领域的理解能力较强。
如何使用 CLIP
在 Hugging Face 的 transformers 库中,可以直接调用 CLIP 模型。例如:
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# 加载模型和处理器
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 准备图像和文本输入
image = Image.open("example.jpg")
text = "a description of the image"
# 处理输入并获取嵌入
inputs = processor(text=[text], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
# 提取图像和文本的特征向量
image_embeds = outputs.image_embeds
text_embeds = outputs.text_embeds
# 计算相似度
similarity = torch.cosine_similarity(image_embeds, text_embeds)
print("Similarity:", similarity.item())通过这种方式,CLIP 可以应用于文本-图像匹配和相关任务。
Deployment
在这节介绍了如何在huggingface中部署app。
在这里也把gradio的模版说下:
使用 Gradio 创建用户界面(UI)非常简单,它允许你快速将 Python 函数包装成 Web 应用。Gradio 的 UI 非常适合展示和测试机器学习模型或其他交互式 Python 代码。
以下是一个创建 Gradio 应用的基本模板代码:
1. 安装 Gradio
确保安装了 Gradio,可以通过以下命令进行安装:
pip install gradio
2. Gradio 应用基本模板
以下是一个 Gradio 应用的基础代码模板,创建了一个简单的文本输入和输出界面:
import gradio as gr
# 定义一个简单的函数,用于处理输入并生成输出
def greet(name):
return f"Hello, {name}!"
# 创建 Gradio 接口
interface = gr.Interface(
fn=greet, # 传入定义的函数
inputs="text", # 输入组件类型
outputs="text", # 输出组件类型
title="Greeting App", # 应用的标题
description="Enter your name to get a greeting message." # 简短的描述
)
# 启动应用
if name == "__main__":
interface.launch()
运行此代码后,会启动一个本地服务器,并在浏览器中打开一个简单的 Web 应用,用户可以输入名字,点击按钮,然后显示欢迎消息。
3. 更复杂的示例
Gradio 提供多种组件来处理不同类型的数据,比如文本、图片、音频等。以下是一个稍微复杂的例子,展示如何上传图片,并让模型预测图像类别:
import gradio as gr
from PIL import Image
# 示例函数:读取图片并返回尺寸
def analyze_image(image):
img = Image.open(image)
width, height = img.size
return f"Image size: {width} x {height}"
# 创建接口
interface = gr.Interface(
fn=analyze_image, # 处理函数
inputs="image", # 输入类型(图像上传)
outputs="text", # 输出类型(文本显示)
title="Image Analyzer",
description="Upload an image to analyze its dimensions."
)
# 启动应用
if name == "__main__":
interface.launch()
4. Gradio 应用的主要组件
• fn: 传入的处理函数。
• inputs: 定义输入组件的类型,可以是 text、image、audio、video 等。
• outputs: 定义输出组件的类型,与输入类似,可以是 text、label、image 等。
• title: 定义应用的标题。
• description: 提供一个简短的描述。
5. 运行和分享应用
运行代码后会启动一个本地服务器,并显示 Gradio UI。如果想要公开分享,可以添加 share=True 参数:
interface.launch(share=True)
这会生成一个可以共享的 URL,其他人也可以通过这个链接访问你的 Gradio 应用。