课程链接:https://learn.deeplearning.ai/courses/langchain-chat-with-your-data/lesson/1/introduction
代码:https://github.com/MSzgy/LangChain-Chat-with-Your-Data
Introduction
本课程是由LangChain带来的第二篇课程,第一篇在这里:https://halo.mosuyang.org/archives/langchain-for-llm-application-development。本课程着重于对于RAG的讲解。
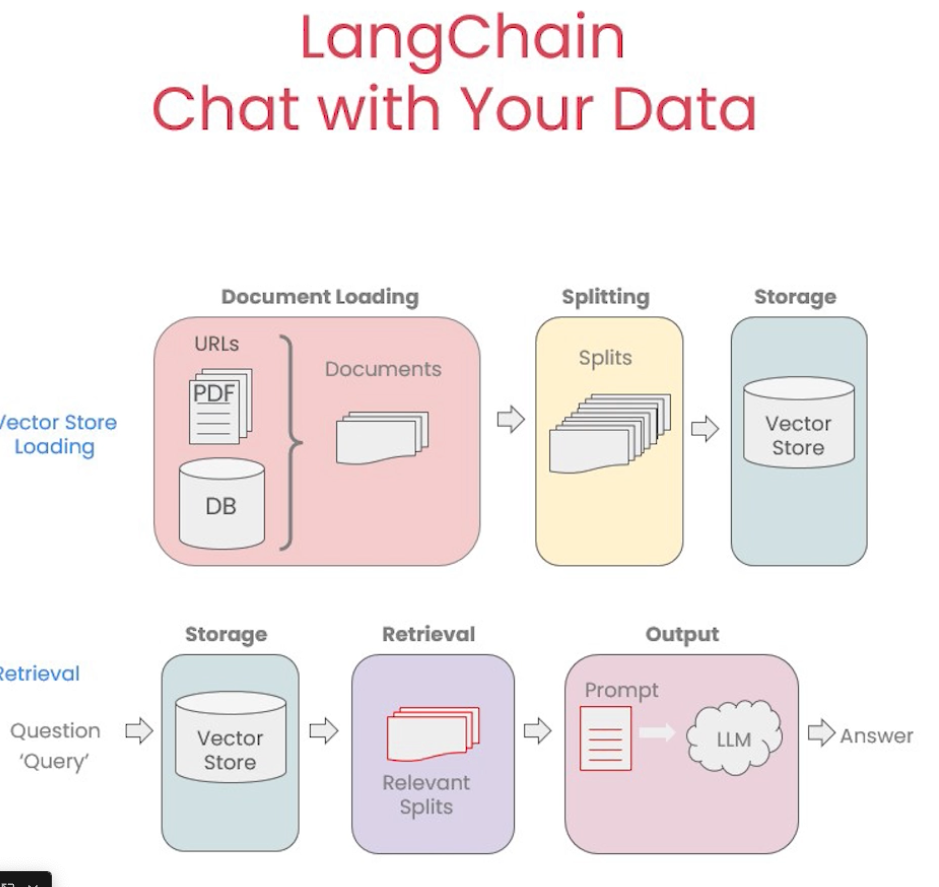
Document Loading

Document Splitting

下面是几个spliiter:
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)RecursiveCharacterTextSplitter 和 CharacterTextSplitter 都是用于将文本分割成较小块的工具,但它们的分割方式有所不同。以下是对这两个 splitter 的解释:
1. RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter 是一种递归的字符级别文本分割器。它的工作方式是按照特定的分隔符顺序递归地尝试分割文本,例如按段落、句子或单词分割,从更大的结构逐步向下细分。
工作原理:
• RecursiveCharacterTextSplitter 通过指定多个分隔符(如句号、换行符、空格等)进行递归拆分。
• 它会先尝试使用第一个分隔符进行分割,如果结果块的大小满足设定的 chunk_size,则停止分割,否则继续使用下一个分隔符。
• 通过这种方式,它可以更智能地在句子、段落或其他语义边界上分割文本,保持较好的上下文完整性。
优点:
• 更加智能地拆分文本,通常不会在句子或段落中间截断。
• 对于自然语言处理任务,如摘要生成或问答系统,这种递归的分割方式可以保留更多的上下文,利于模型理解语义结构。
示例代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
2. CharacterTextSplitter
CharacterTextSplitter 是一种简单的字符级别分割器,它只按照字符数量来分割文本。
工作原理:
• CharacterTextSplitter 会遍历文本,并将其按设定的 chunk_size 进行截断。
• 它仅仅关注字符数量,不考虑句子、单词或段落等语义结构,因此分割点可能会落在句子或单词的中间。
• 如果需要重叠部分,它会在每个块的尾部添加 chunk_overlap 字符数,以提供一些上下文信息。
优点:
• 更加简单高效,适用于不需要精确语义分割的场景。
• 对于只需处理纯文本或字符级别的任务(如文本分类、相似度计算),这种分割方式更高效。
示例代码:
from langchain.text_splitter import CharacterTextSplitter
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
总结
• RecursiveCharacterTextSplitter:适合需要保留语义结构的文本处理任务,分割更加智能。
• CharacterTextSplitter:简单直接,适合快速的字符级别分割,不考虑语义结构。
Vectorstores and Embedding
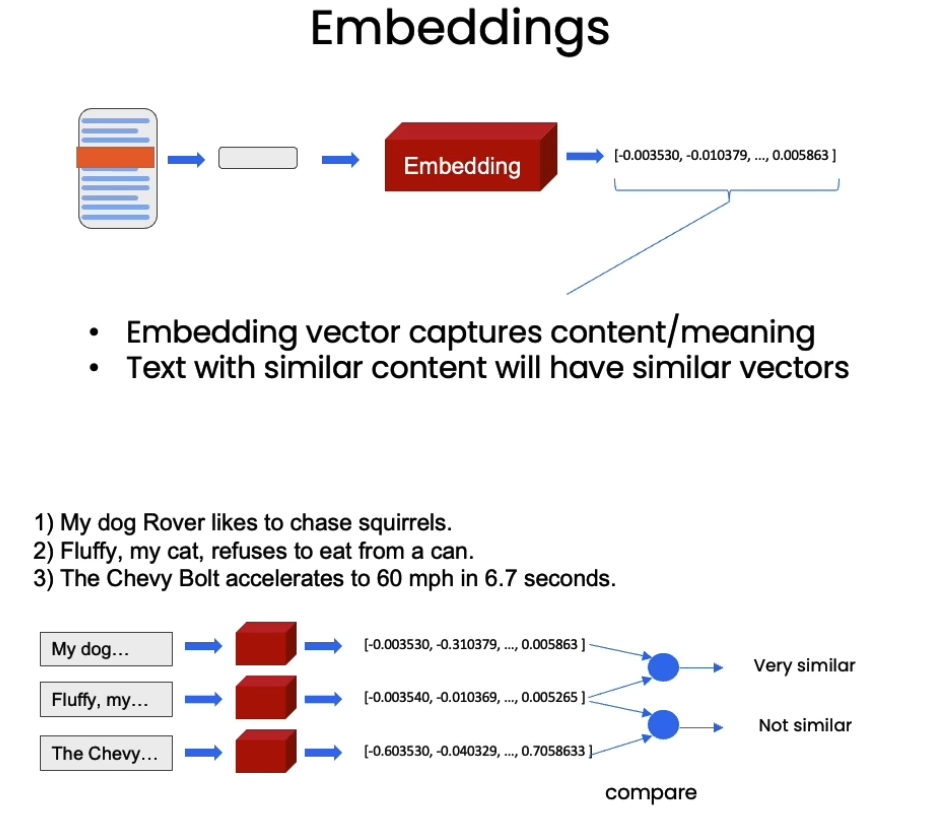
将文本转为word embeddigns,然后在查询时,会找到相似的文本段落。
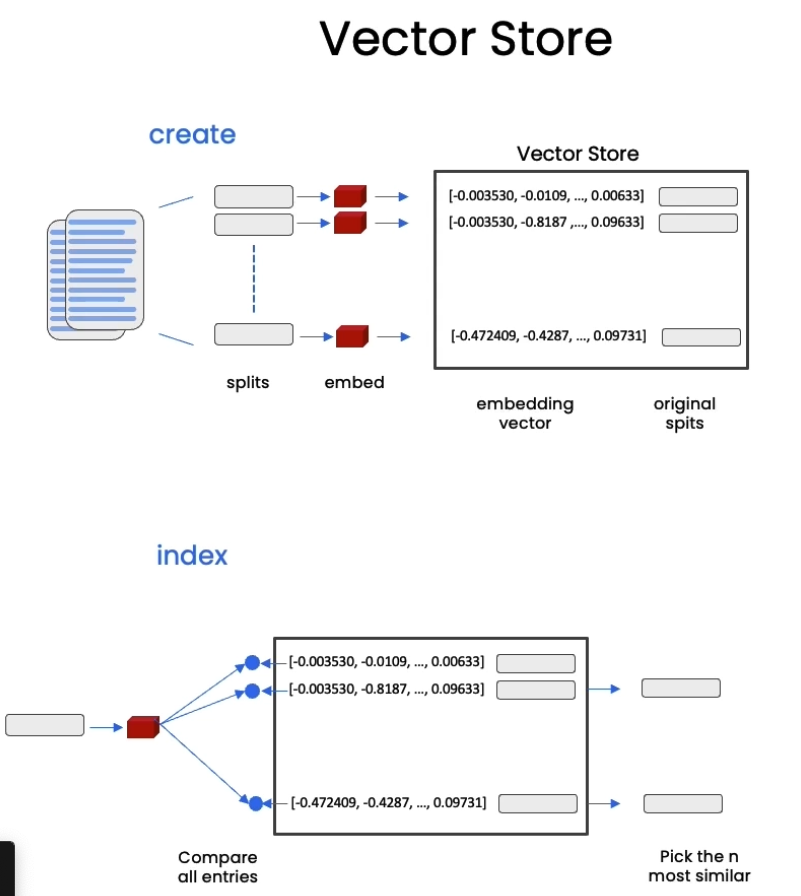
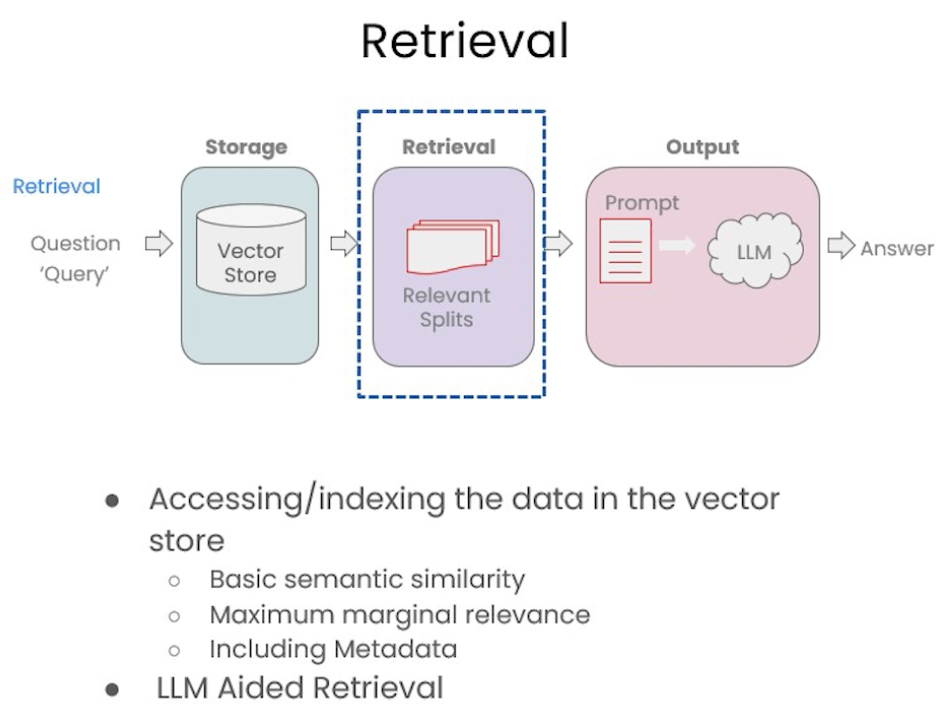
Retrieval
为了增强retrieval的效果,这里提出了三种方法
Basic semantic similarity
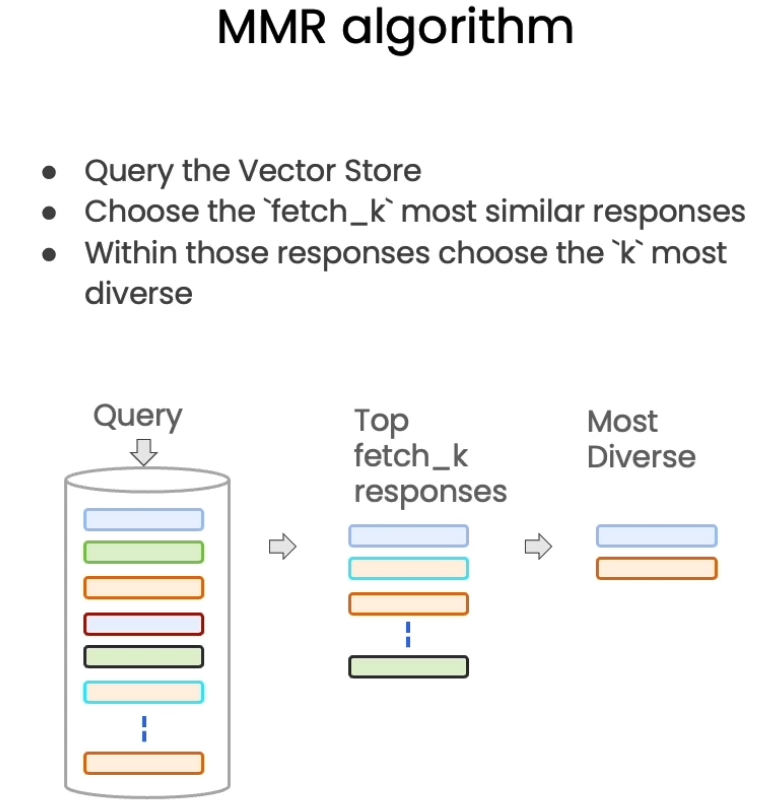
Maximum marginal relevance
Including Metadata
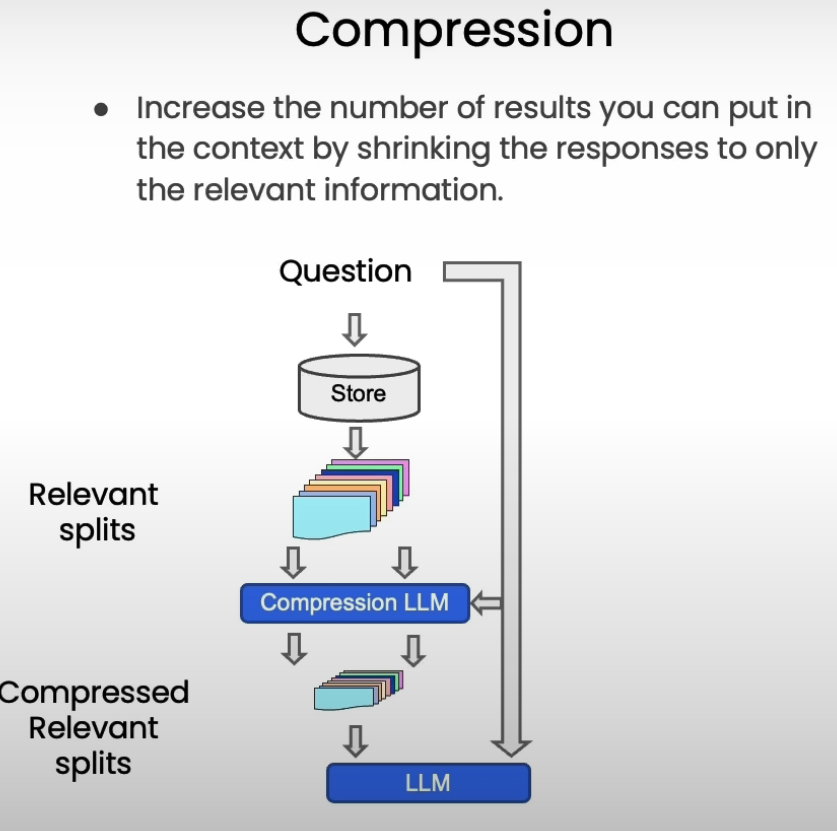
除了上面提到的retriever,这里还介绍了传统的机器学习方法:SVM(支持向量机)以及TF-IDF()

SVM:
SVM(Support Vector Machine,支持向量机)是一种用于分类和回归任务的机器学习算法。SVM的主要目标是找到一个最佳的超平面,将数据分成不同类别,同时尽可能地增加两个类别之间的“间隔”。它特别适合于高维空间的数据分类问题。
SVM的基本概念
1. 支持向量(Support Vectors)
• 支持向量是位于分类边界上的数据点。这些点对确定分类边界(超平面)有着关键作用。SVM的目标就是找到一个最佳超平面,使得这些支持向量之间的间隔最大化。
2. 超平面(Hyperplane)
• 超平面是一个可以分割空间中不同类别的边界。例如,在二维平面中,超平面是一个直线;在三维空间中,超平面是一个平面。SVM会尝试找到一个最优超平面,将数据分成两个类别,同时使超平面两侧的“间隔”最大化。
3. 间隔(Margin)
• 间隔是超平面与支持向量之间的距离。SVM的核心思想就是在所有可能的超平面中,找到能使间隔最大的那个,这样可以提高模型的鲁棒性和泛化能力。
SVM的主要原理
SVM通过优化以下公式来找到最佳的超平面:
\[
\max \left(\frac{2}{\lVert w \rVert}\right)
\]
其中, 是超平面的法向量,优化的目的是最大化间隔,同时限制错误分类的情况。
SVM的两种类型
1. 线性SVM
• 线性SVM适用于线性可分的数据集,数据点之间可以通过一个线性超平面完全分开。
2. 非线性SVM
• 对于线性不可分的数据集,SVM引入“核函数”(如高斯核、径向基核函数)将数据映射到更高维度空间,使得数据在高维空间中可以通过线性超平面分割。
• 常用的核函数有线性核、径向基核、多项式核等。
SVM的优点与缺点
• 优点:
• 在高维空间中表现出色,尤其适合图像识别、文本分类等任务。
• SVM的决策边界是由少数支持向量决定的,具有一定的鲁棒性。
• 通过使用不同的核函数,可以处理线性和非线性分类问题。
• 缺点:
• 对于数据量特别大的情况,SVM的计算代价较高。
• 当数据类别间存在严重重叠时,SVM的表现可能不理想。
• SVM需要选择合适的核函数和超参数,这些选择可能需要大量实验和调参。
应用场景
SVM广泛用于文本分类、人脸识别、医学诊断等领域。在这些应用中,它能够在噪音较少、类别明显的数据上实现较高的分类准确率。
TF-IDF:
TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计方法,用于衡量一个词语在文档集合中的重要性。它通常用于信息检索、文本挖掘和搜索引擎等领域,以提高查询效果,过滤掉常见词语,同时保留有区分度的关键词。TF-IDF由两个主要部分组成:
1. 词频(TF, Term Frequency)
• 词频表示某个词在文档中出现的频率。
• 公式:
• 如果一个词在文档中出现得越频繁,其TF值就越大。
2. 逆文档频率(IDF, Inverse Document Frequency)
• 逆文档频率衡量某个词在所有文档中的稀有程度。
• 公式:
• 一个词在越少的文档中出现,IDF值就越大,意味着该词能更好地代表特定文档的内容。
3. TF-IDF值的计算
• 最终的TF-IDF值是通过将TF和IDF相乘得到的:
• 这样可以平衡词语在单个文档中出现的频率与在所有文档中的普遍性。常见词(如“the”、“is”)的TF-IDF值会较低,而在特定文档中出现频繁但在其他文档中稀有的词则会获得更高的权重。
示例
假设一个词在某篇文章中出现10次,而该词在10,000篇文章中仅出现5次,则该词在该文章中的重要性会被TF-IDF高估。
应用场景
TF-IDF广泛用于文档分类、信息检索、关键词提取和文本相似度计算中,通过计算每个词的TF-IDF值来挑选出对文档区分度较高的词语。
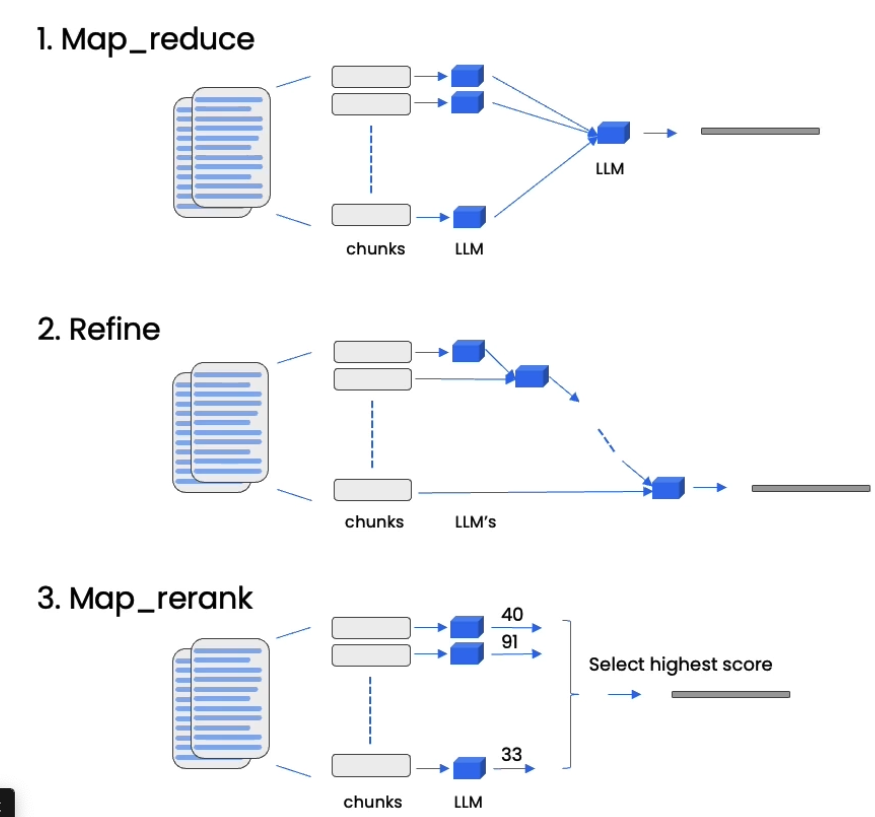
Question Answering
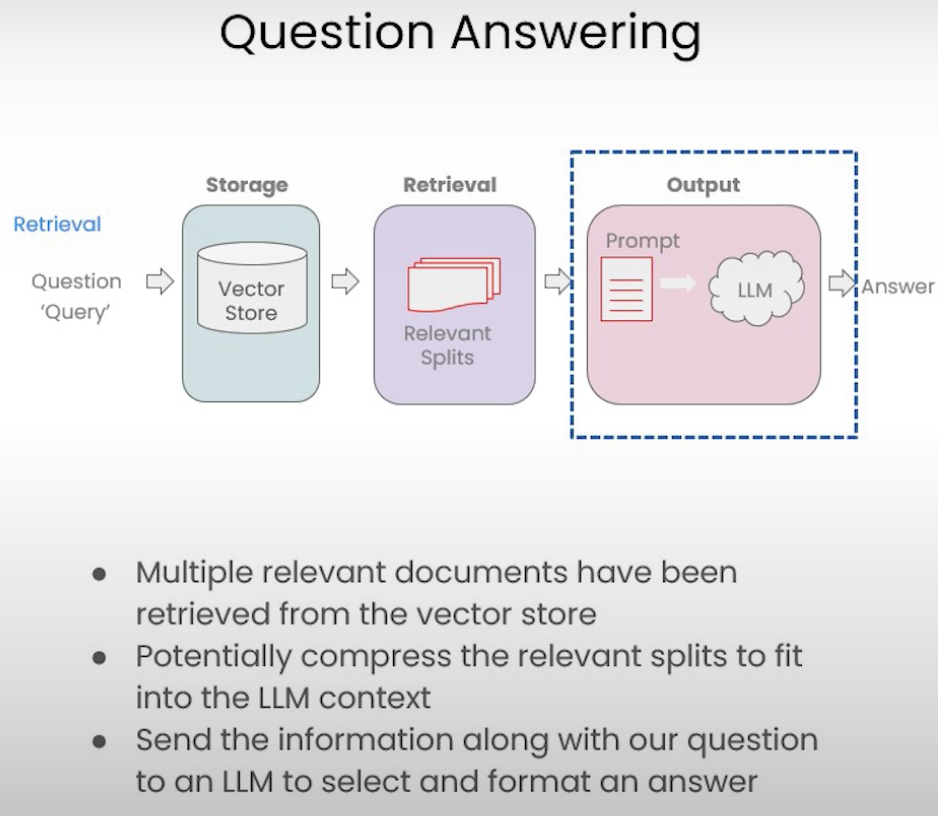
some methods to retrieve.
Chat
本节在上节的基础上增加了对chat history的记录。具体可见代码。