课程链接:https://learn.deeplearning.ai/courses/building-agentic-rag-with-llamaindex/lesson/1/introduction
整理的代码: https://github.com/MSzgy/Building-Agentic-RAG-with-Llamaindex.git
LlamaIndex: https://docs.llamaindex.ai/en/stable/
Introduction
本篇课程将会带你搭建一个自动搜索Agent, 利用了Llamaindex框架搭建。
LlamaIndex 是一个开源项目,最初叫做 GPT Index。该项目的目标是帮助将大型语言模型(LLM),例如 GPT、LLaMA 等,与外部数据源(如文档、数据库、API 等)进行集成。
LlamaIndex 的主要作用是通过建立索引和有效的检索机制,使得大型语言模型可以更高效地查询和利用外部数据,从而简化开发者在构建与大量文本或结构化数据相关应用时的工作。
尽管 LlamaIndex 不是一家企业,它在 AI 和开发者社区中有着重要的应用,尤其是在支持大型语言模型与外部数据交互方面。
这本课程中,以文档RAG的形式描述了LlamIndex工具的使用。
Router Query Engine
Index
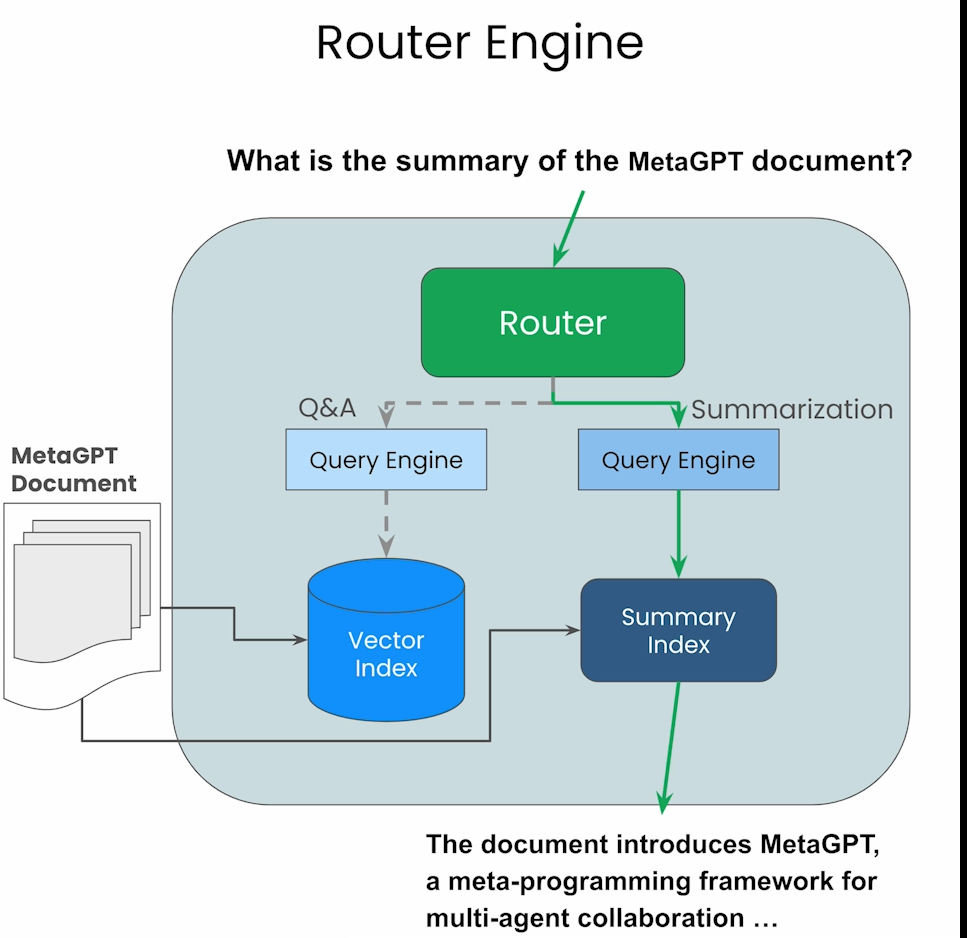
在做RAG时都会用到索引(index)以便更快地在knowledge base(知识库)中快速找到和qyuery相似的knowledge graph.
Vector Index
Query a vector Index will return the most similar the node by embedding similarity.
Summary Index
will return all the nodes currently in the index.
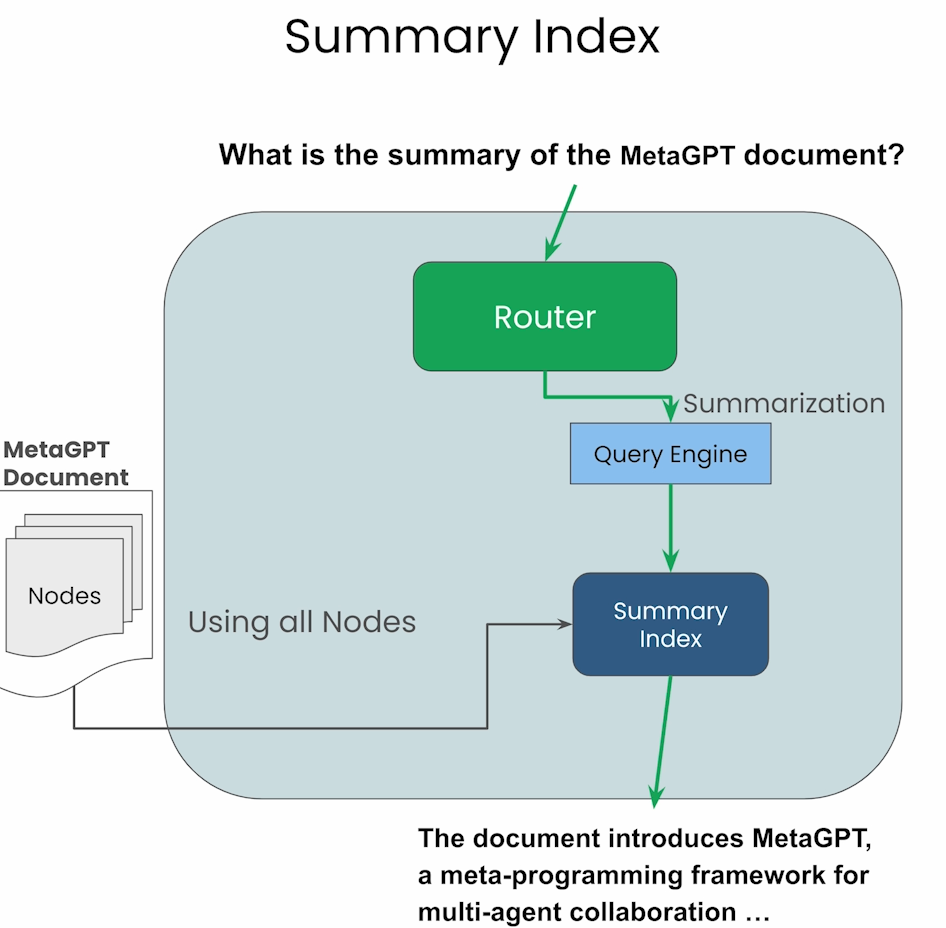
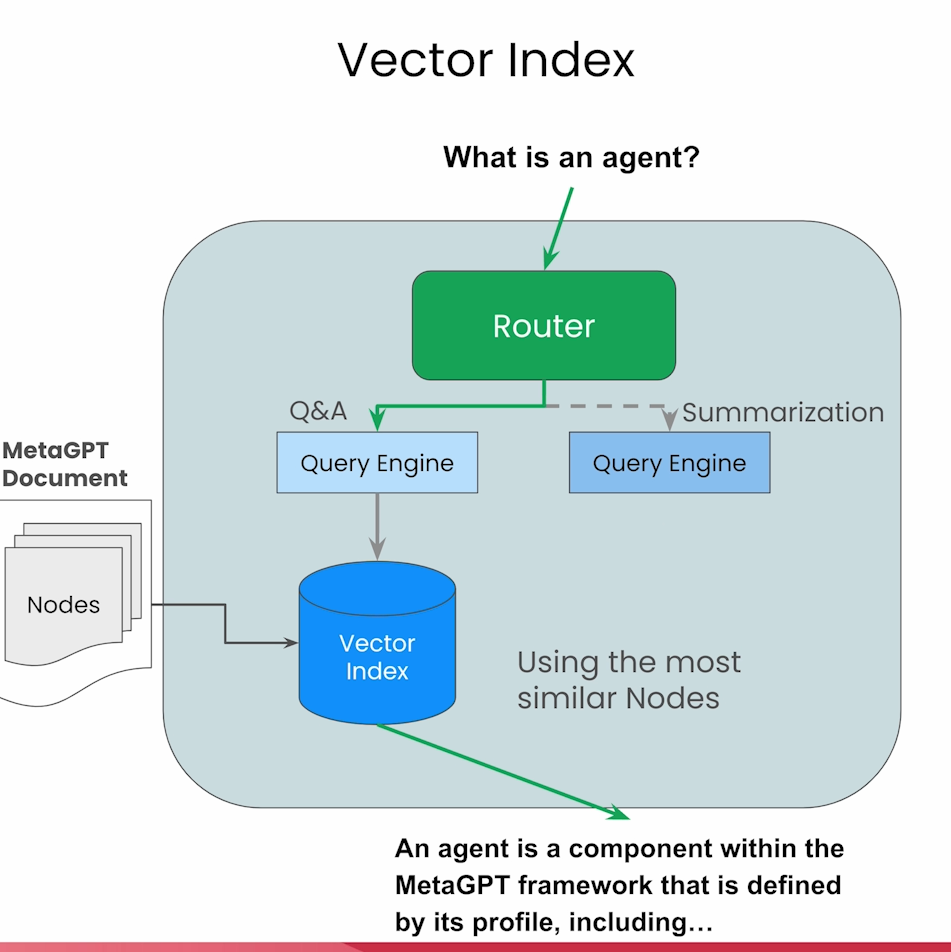
通过上述两个Index,可以构造相应的search query tool,并且构造Router去使用。LlamaIndex提供了几种Selector去允许客户创建Router。在代码中,将两个serch tool 传给SingleRouter去使用,Router会根据query自动地选择相应的query tool.例如对于summary类型,会将所有node传给LLM解析,对于特定知识的query,会选择相应的node传给LLM。

Tool Calling
本节首先举了两个函数例子,利用LlamaIndex可以直接将两个函数传入FunctionTool, 然后直接在query中提及到相应的函数,LLM就能识别并执行。
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
def add(x: int, y: int) -> int:
"""Adds two integers together."""
return x + y
def mystery(x: int, y: int) -> int:
"""Mystery function that operates on top of two numbers."""
return (x + y) * (x + y)
add_tool = FunctionTool.from_defaults(fn=add)
mystery_tool = FunctionTool.from_defaults(fn=mystery)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
response = llm.predict_and_call(
[add_tool, mystery_tool],
"Tell me the output of the mystery function on 2 and 9",
verbose=True
)
print(str(response))
在做RAG的同时,还提到了通过Metadata做数据过滤,类似https://halo.mosuyang.org/archives/prompt-compression-and-query-optimization
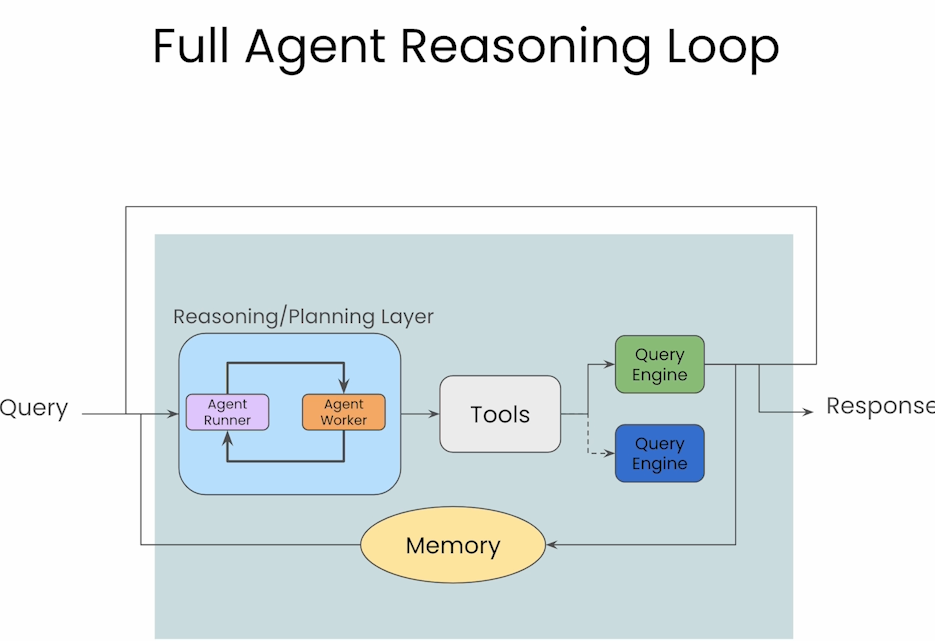
Building an Agent Reasoning App
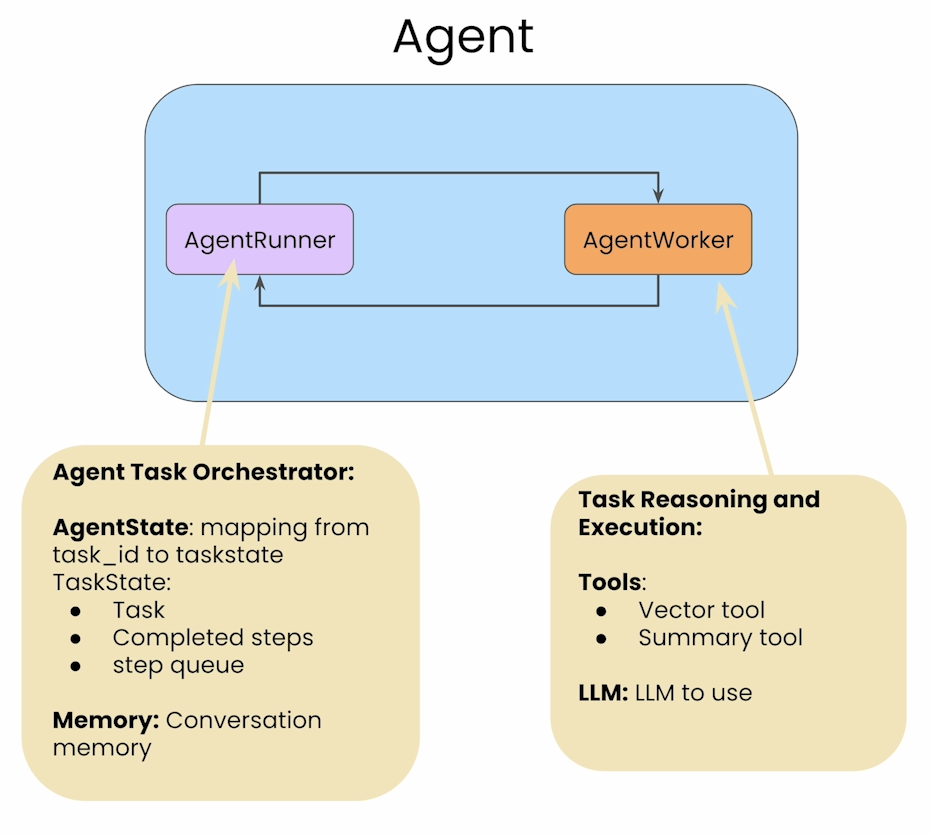
与前两节SingleRouter不同,本节介绍了带有记忆的Agent流,在调用tool时不仅会考虑当前的query,也会考虑历史信息。在这节中可以同时执行多个任务,并且前面所有任务都会作为下一个任务的context, 而且允许user在任务执行过程中发送反馈以便及时更改返回。

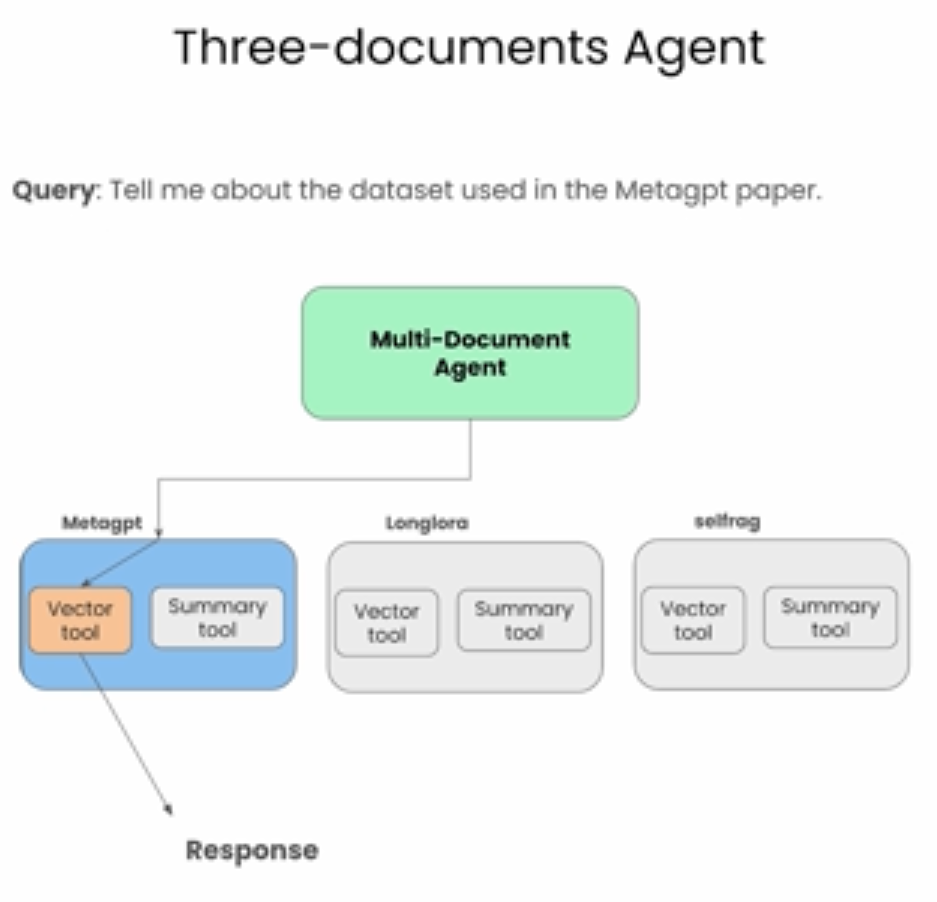
Building a Multi-Document Agent
本节先举了个有3个文档的例子,代码步骤和前几节类似,会把每个文档的summary tool以及vector index tool整合起来,一共6个tools, 然后采用与上节类似的方法。
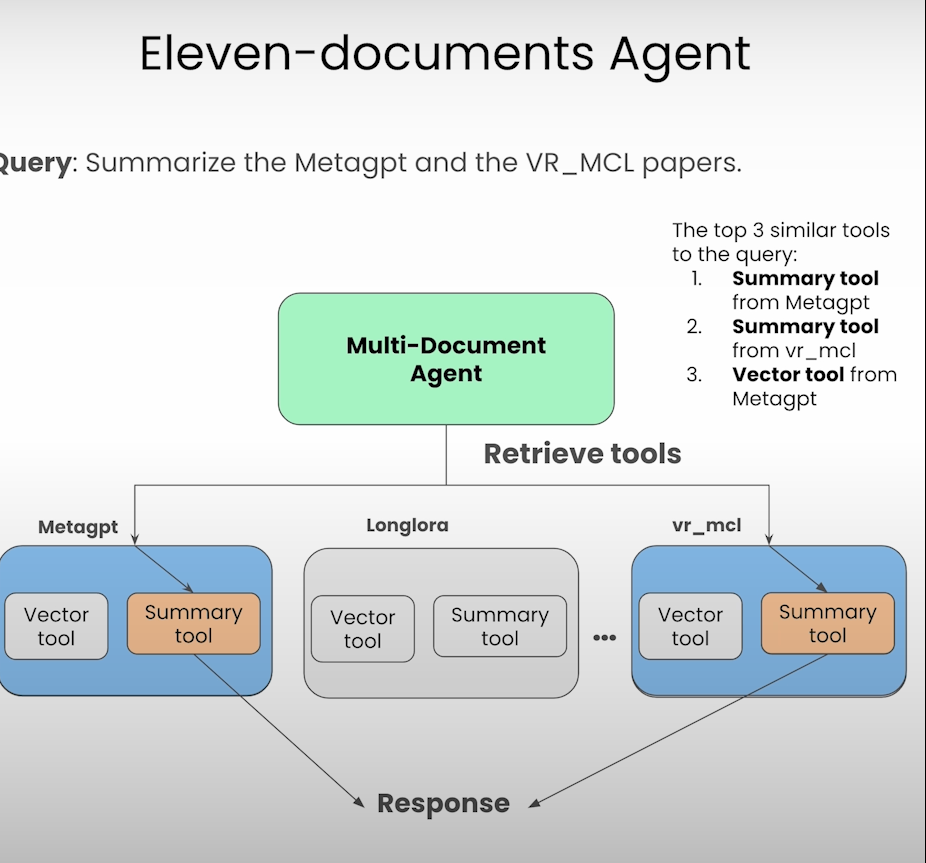
接着重点说明了,当文档数量过多,例如有100个文档,LLM上下文过长的时候该怎么处理(由于LLM的context window 是有长度限制的,因此不能考虑将全部数据作为context输入到LLM)。
介绍了一种方式,先获取所有相关的tools,而不是直接对文本做处理。
# define an "object" index and retriever over these tools
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
obj_index = ObjectIndex.from_objects(
all_tools, #获取所有可用的tools
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3) #限制获取并使用相似度最高的3个tools
tools = obj_retriever.retrieve(
"Tell me about the eval dataset used in MetaGPT and SWE-Bench"
)
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever, #注意这里取的是相似度最高的3个tools
llm=llm,
system_prompt=""" \
You are an agent designed to answer queries over a set of given papers.
Please always use the tools provided to answer a question. Do not rely on prior knowledge.\
""",
verbose=True
)
agent = AgentRunner(agent_worker)