课程链接:https://learn.deeplearning.ai/courses/langchain/lesson/1/introduction
代码: https://github.com/MSzgy/LangChain-for-LLM-Application-Development
Introduction
LangChain 是一个用于构建以语言模型 (LLM) 为中心的应用的开发框架。它帮助开发者将大型语言模型(如 GPT-3 或 GPT-4)与其他外部资源或工具(如搜索引擎、数据库、API 等)集成在一起,从而构建强大的应用程序。
LangChain 的主要功能包括:
1. 链式调用:你可以通过“链”的概念,定义一系列步骤,每个步骤依赖前面的结果,允许复杂的工作流。
2. 代理 (Agents):允许你通过语言模型来决定何时调用外部工具,代理可以动态做出决策,而不仅仅是简单执行固定的任务。
3. 内存 (Memory):为应用程序提供上下文记忆功能,使得多轮对话中的上下文信息得以保留和使用。
4. 工具集成:可以与各种外部工具(如数据库、Python 函数、搜索引擎、API 等)进行整合,使模型可以访问实时数据或进行复杂的运算。
LangChain 特别适用于开发聊天机器人、问答系统、智能搜索引擎等场景,具有很强的灵活性和扩展性。

本课程内容:
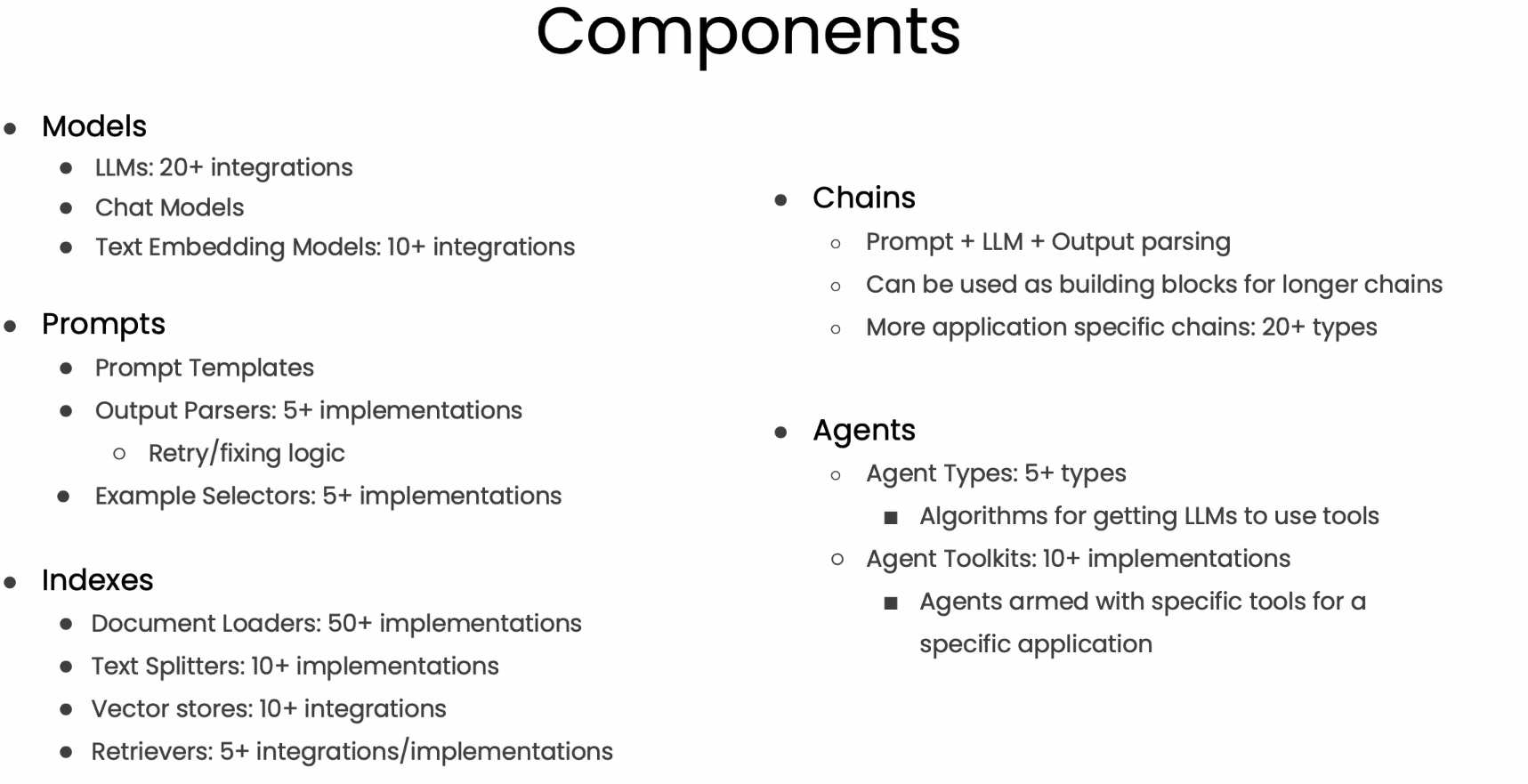
Models, Prompts and Parsers
通过使用Langchain,可以reuse prompt input, 而且也能解析LLM的output使其符合相关格式。

Memory
Langchain提供了简答并强大的组件去保存相关的对话历史记录,提供了多种类型的memory保存机制,例如根据对话轮数,根据token数,根据历史记录形成summary。
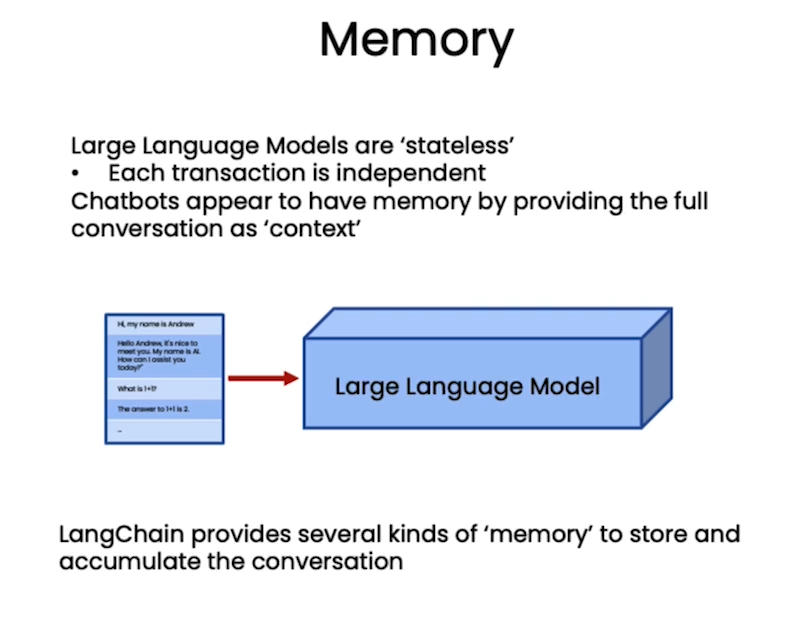

此外,Langchain中还包含其他的高级的Memory type:

采用vector 存储的例子:https://chatgpt.com/share/66fb9744-ea38-8012-9bbe-aa2f93ac9d77
Chain
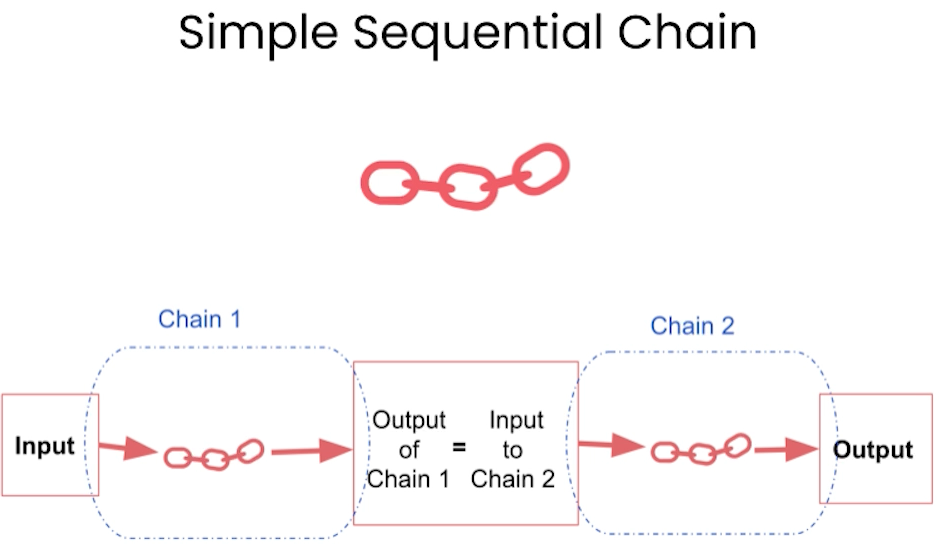
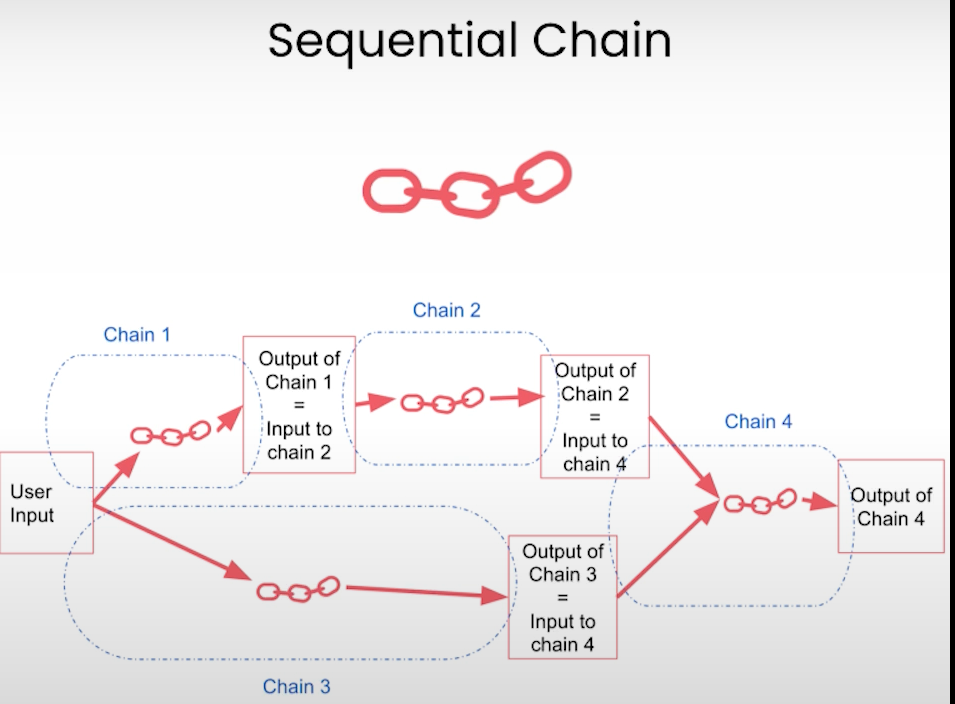
本节开始介绍LangChain中的关键字“Chain”,先从简单的simpleChain开始,接着介绍了Sequential Chain, 然后是Router Chain(根据不同的输入指向相应的sub chain)

Question and Answer
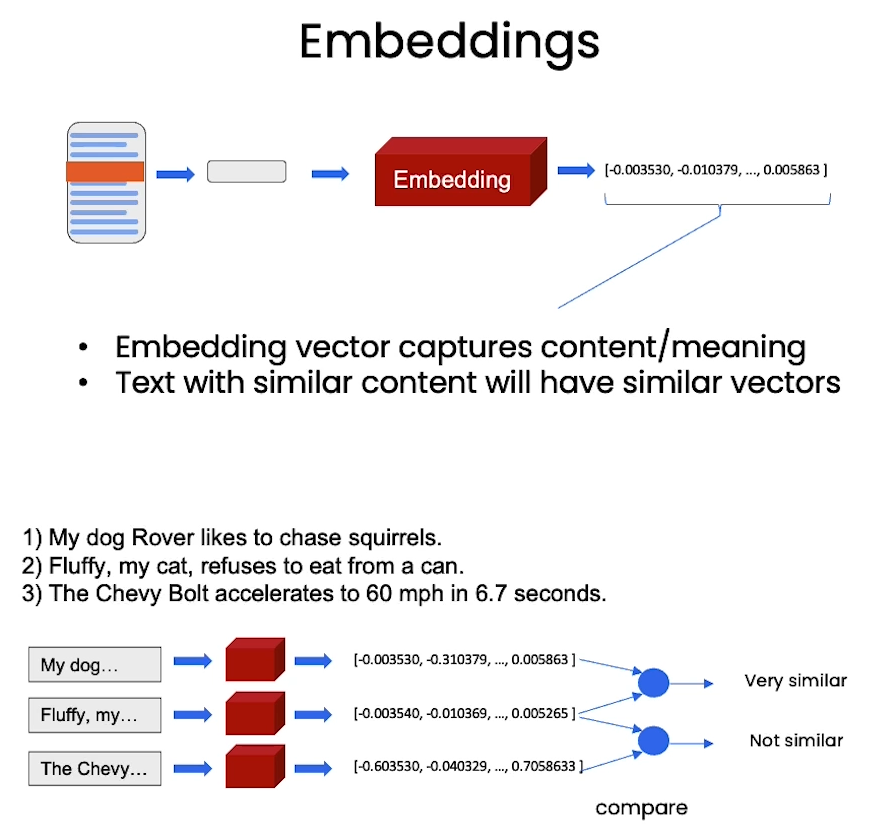
在本节中,介绍了一些技术点,涉及到embeddings vector.
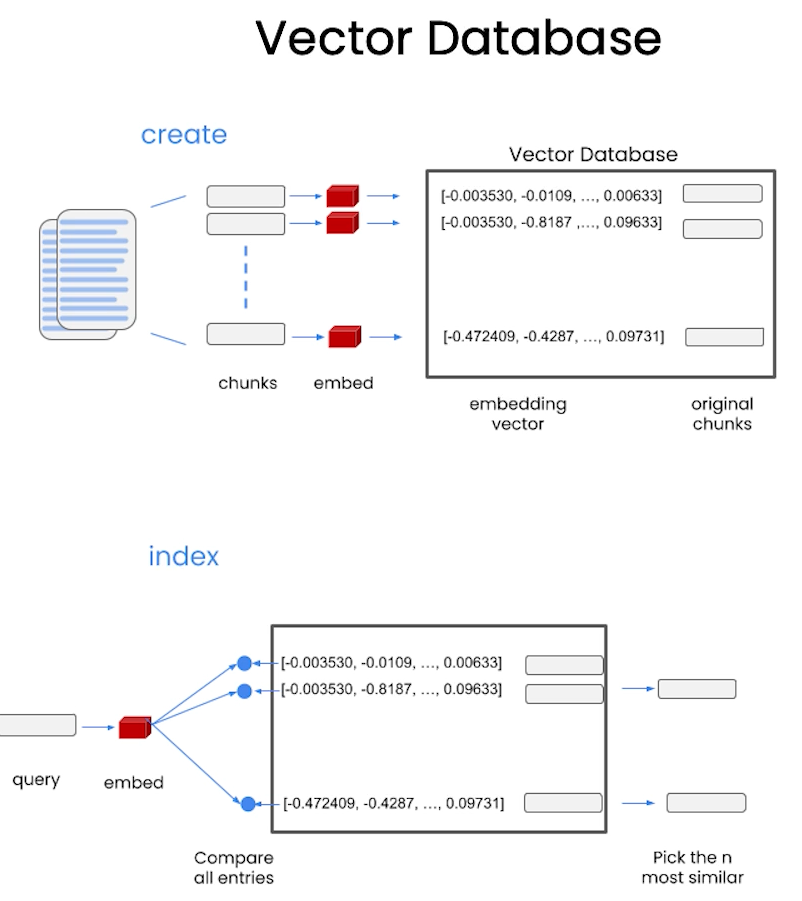
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.indexes import VectorstoreIndexCreator
# 将文档转为向量表示并存储
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])# 这段代码同样可以创建向量数据库,不过与上面代码不同,这里需要手动提供text embeddings
/**
这两段代码虽然都与创建向量索引和搜索相关,但它们的作用略有不同:
### 1. `index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch).from_loaders([loader])`
- **使用 `VectorstoreIndexCreator` 来创建索引**:
- **`VectorstoreIndexCreator`** 是 LangChain 中的一个类,专门用于简化从数据加载器创建向量索引的过程。
- **`vectorstore_cls=DocArrayInMemorySearch`**:这是指定将使用 `DocArrayInMemorySearch` 类来存储和搜索文档的向量化结果。`DocArrayInMemorySearch` 是一个内存中的向量存储,适合进行快速查询。
- **`.from_loaders([loader])`**:它通过传递的 `loader` 来加载文档,`loader` 负责从数据源中加载文档,并且可能自动完成对文档的预处理和向量化(通过嵌入模型),然后将其存入 `DocArrayInMemorySearch` 进行后续的搜索。
**总结**:这段代码用于从一个或多个数据加载器(`loader`)中读取文档,自动将文档转换为向量并创建索引。主要用于自动化从加载文档到创建向量索引的整个流程。
### 2. `db = DocArrayInMemorySearch.from_documents(docs, embeddings)`
- **直接使用 `DocArrayInMemorySearch` 创建向量数据库**:
- **`DocArrayInMemorySearch`**:这是一个向量存储类,直接将文档的向量表示存储在内存中,方便高效查询。
- **`.from_documents(docs, embeddings)`**:此方法直接接受两个参数:
- `docs`: 这是你想要存储的文档列表。
- `embeddings`: 这是与 `docs` 相对应的向量嵌入。它假设文档已经被转换为向量(即已经经过嵌入模型处理)。
**总结**:这段代码假设文档已经被处理成向量,并且你手动提供了文档和对应的嵌入。它直接将这些文档和嵌入存储到内存中的 `DocArrayInMemorySearch` 以便进行搜索。
### 区别
1. **文档加载和嵌入生成方式**:
- `VectorstoreIndexCreator` 是一个高层的工具,它通常会自动处理从文档加载到嵌入生成的整个流程,适合需要简单的端到端构建向量索引。
- `DocArrayInMemorySearch.from_documents()` 假定你已经有了文档和它们的向量表示,你手动控制文档的加载和嵌入生成,适合更灵活的场景。
2. **使用场景**:
- `VectorstoreIndexCreator` 适合在你不想手动管理文档加载和嵌入生成的情况下使用。
- `DocArrayInMemorySearch.from_documents()` 适合已经有了嵌入,并且需要手动将文档及其向量表示加载到向量存储中的场景。
*/
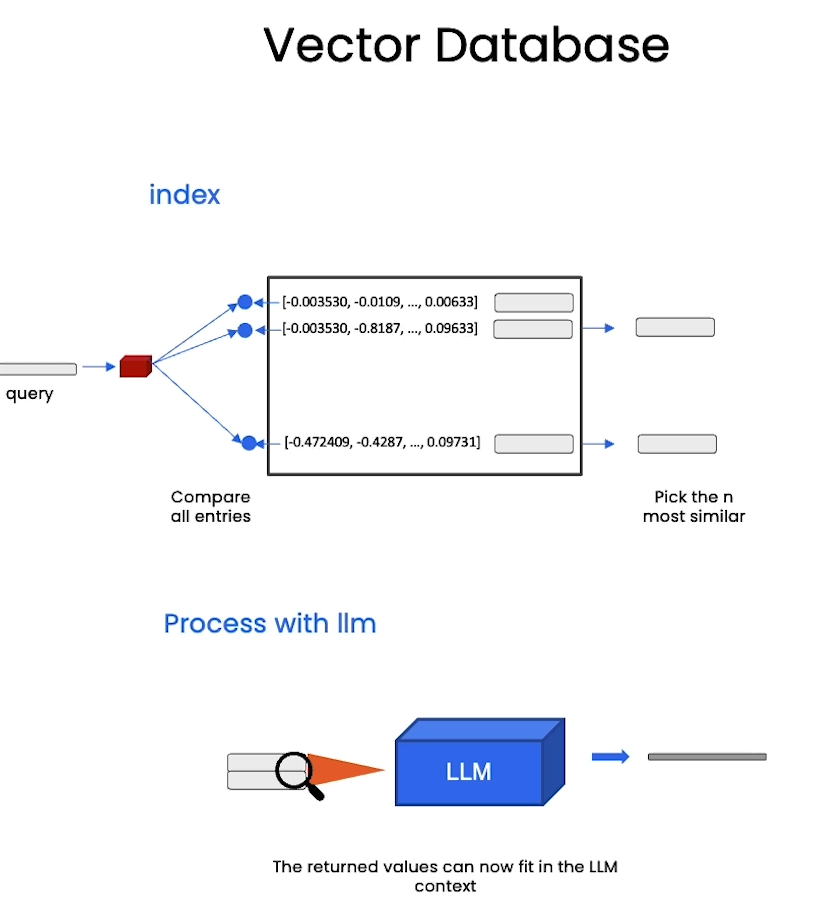
db = DocArrayInMemorySearch.from_documents(
docs,
embeddings
)
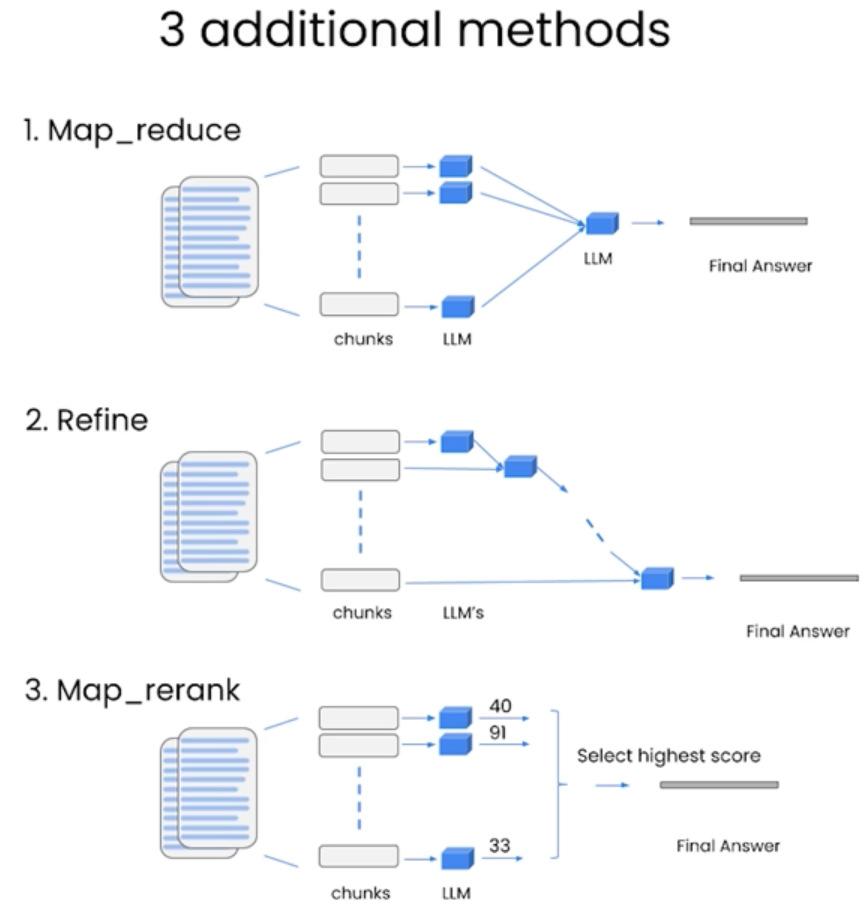
在本节中,提出了几种如何引入Context的方法,包括stuff method, map_reduce, Refine, Map_rerank.

Evaluation
本节介绍了如何对LLM的输出做evaluation
利用QAGenerateChain可以生成基于文档的问答对
QAGenerateChain 是 LangChain 用于生成问答对的链条。通过给定文本或文档,它可以自动生成问题及其相应的答案。下面是一个简单的示例,展示如何使用 QAGenerateChain 来生成问答对:
### 示例代码
from langchain.chains import QAGenerateChain
from langchain.llms import OpenAI
# 初始化语言模型(例如 OpenAI 的 GPT 模型)
llm = OpenAI(temperature=0.7)
# 创建一个 QAGenerateChain 对象,传入语言模型
qa_generate_chain = QAGenerateChain(llm=llm)
# 传入一段文本,生成问答对
doc = """
The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France.
It was named after the engineer Gustave Eiffel, whose company designed and built the tower.
Constructed from 1887 to 1889 as the centerpiece of the 1889 World's Fair,
it was initially criticized by some of France's leading artists and intellectuals for its design,
but it has become a global cultural icon of France and one of the most recognizable structures in the world.
"""
# 将文档作为输入,生成问答对
qa_pairs = qa_generate_chain.apply_and_parse([{"doc": doc}])
# 输出生成的问答对
for qa in qa_pairs:
print(f"Question: {qa['question']}")
print(f"Answer: {qa['answer']}")
print()### 代码解释:
1. `OpenAI` 模型:我们使用了一个预训练的语言模型(例如 OpenAI GPT 模型)来生成问答对。`temperature=0.7` 使得模型的生成有一些随机性。
2. `QAGenerateChain` 对象:这个链条专门用于生成基于文档的问答对。它会根据提供的文档生成相关问题和答案。
3. `apply_and_parse`:该方法接受一个文档列表,逐个处理并生成相应的问答对。
### 示例输出
假设输入文档是关于埃菲尔铁塔的介绍,生成的问答对可能如下:
Question: Where is the Eiffel Tower located?
Answer: The Eiffel Tower is located on the Champ de Mars in Paris, France.
Question: Who designed the Eiffel Tower?
Answer: The Eiffel Tower was designed by the engineer Gustave Eiffel.
Question: When was the Eiffel Tower constructed?
Answer: The Eiffel Tower was constructed from 1887 to 1889.
Question: Why was the Eiffel Tower initially criticized?
Answer: It was initially criticized by some of France's leading artists and intellectuals for its design.
Question: What has the Eiffel Tower become known as over time?
Answer: It has become a global cultural icon of France and one of the most recognizable structures in the world.### 应用场景:
- 生成训练数据:生成大量问答对以训练或微调问答系统。
- 知识提取:从文本或文档中自动提取关键信息并生成相应的问答对,帮助用户快速理解文档内容。
### 总结
QAGenerateChain 能够根据给定文档自动生成相关问题和答案,用于构建问答系统、生成学习资料等。
from langchain.evaluation.qa import QAGenerateChain
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI(model=llm_model))
new_examples = example_gen_chain.apply_and_parse(
input_list
)
Agents
在本节中,介绍了两种Agenet场景,第一种通过调用wikipedia来搜索某个人物,第二个通过调用python来执行编程。